What Fugu Ultra Is: A Frontier System Built on Multi-Agent AI Orchestration
Fugu Ultra is a frontier-level multi-agent AI orchestration system that coordinates a pool of language models, delegating and validating subtasks across them, to deliver performance comparable to top single-model systems on coding, reasoning, and scientific benchmarks while reducing dependence on any one AI provider. Instead of being one massive monolithic model, Fugu Ultra acts as a conductor: it routes complex, multi-step tasks across specialized agents, including instances of itself, and combines their outputs into a single, coherent answer. This design targets demanding workflows in engineering, research, cybersecurity, and data analysis where long contexts, careful checking, and sustained focus matter more than raw parameter counts. By exposing all of this through an OpenAI-compatible API, Sakana AI makes the system accessible to developers who already build around standard model endpoints, without forcing them to handle multiple vendor integrations or custom coordination logic themselves.

Inside the Fugu Architecture: Coordinated Roles Instead of One Giant Brain
Sakana’s broader Fugu system rests on two research lines that frame how multi-agent AI orchestration works in practice. The TRINITY framework uses a lightweight coordinator to assign models dynamic roles such as Thinker, Worker, or Verifier over multiple turns, rather than locking them into fixed pipelines. Another component, called the Conductor, uses reinforcement learning to discover natural-language coordination strategies, effectively training the system to decide how to prompt and route each agent for maximum performance. The tagline, “One Model to Command Them All,” captures this emphasis on AI model coordination instead of brute-force scaling. Fugu Ultra can even call copies of itself as specialists, allowing deeper chains of reasoning or verification without redesigning workflows. This approach reflects Sakana AI’s research-first identity and shows how orchestration, rather than endlessly growing single models, can extract more capability from existing model pools.
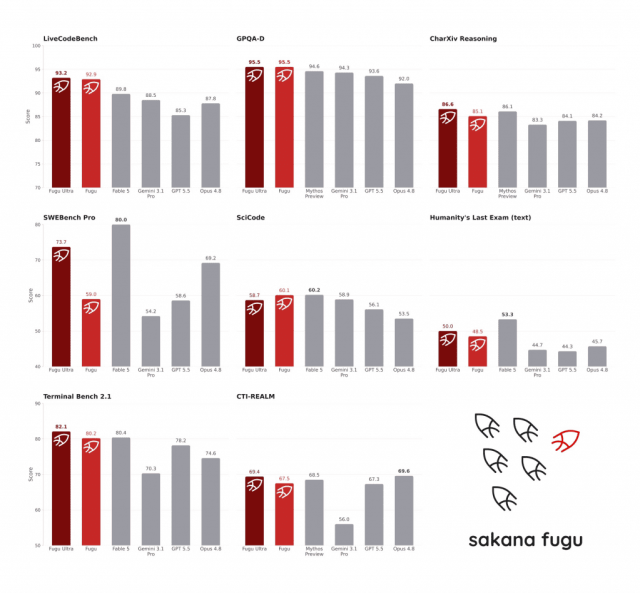
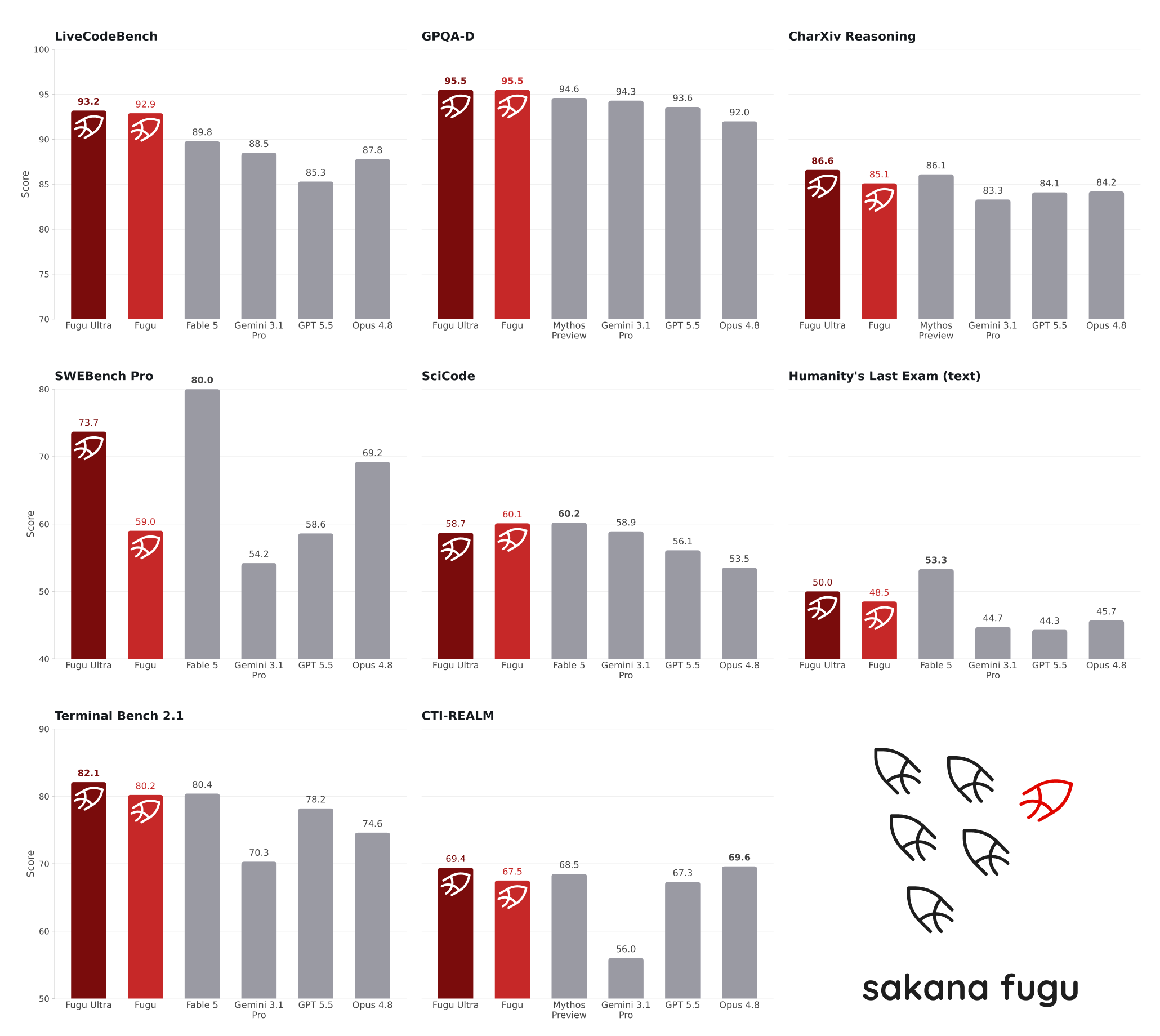
Benchmark Results: Multi-Model Coordination Rivals Frontier Lab Performance
Benchmark scores indicate that the Fugu Ultra model stands alongside leading frontier systems despite its orchestration-first design. On the SWE-Bench Pro software engineering benchmark, Fugu Ultra scores 73.7, ahead of Claude Opus 4.8 at 69.2 and GPT-5.5 at 58.6. On LiveCodeBench, Fugu reaches 92.9 and Fugu Ultra 93.2, topping Gemini 3.1 Pro’s 88.5. On Humanity’s Last Exam, a demanding general-knowledge test, Fugu Ultra achieves 50.0, essentially matching Opus 4.8’s 49.8. Sakana notes that Anthropic’s highest-tier models, Claude Fable 5 and Mythos Preview, are not in the Fugu agent pool because they are not publicly accessible, yet Fugu sits “shoulder-to-shoulder” with them on several benchmarks. These results support Sakana’s claim that a coordinated team of models, when routed carefully, can rival or outperform individual frontier models in real-world tasks.
Developer Experience and Pricing: One OpenAI-Compatible API, Many Agents
For developers, one of Fugu Ultra’s major draws is its single OpenAI-compatible API. Instead of wiring multiple models, endpoints, and prompts together by hand, teams interact with one endpoint while Fugu’s internal coordinator handles agent selection and routing. This keeps integration overhead low and makes it easy to slot Fugu into existing applications built around standard LLM APIs. Fugu comes in two tiers: the standard Fugu model for everyday coding and chatbot tasks, and Fugu Ultra for long-horizon workloads like Kaggle competitions, literature reviews, or end-to-end security assessments. Fugu Ultra pricing is set at USD 5 (approx. RM23) per million input tokens and USD 30 (approx. RM138) per million output tokens, with higher rates above a 272K-token context. Subscription plans at USD 20 (approx. RM92), USD 100 (approx. RM460), and USD 200 (approx. RM920) per month offer predictable costs, with a promotional second month free for early subscribers.
Strategic Shift: Efficiency, Vendor Flexibility, and AI Sovereignty
Sakana AI positions Fugu Ultra as evidence that the next phase of AI competition may favor efficiency and orchestration over raw scale. By coordinating multiple models, enterprises can reach frontier-level performance while retaining control over which providers participate in the pool, a useful feature for teams with data residency or compliance constraints. Vendor flexibility becomes a selling point rather than an afterthought. Fugu Ultra’s multi-agent AI orchestration also fits into Sakana’s broader argument for AI sovereignty: organizations gain a resilient AI layer that is less exposed to single-vendor outages, policy shifts, or export controls. As frontier labs race to build larger and more expensive models, systems like Fugu Ultra show that careful AI model coordination, grounded in research and delivered through familiar APIs, can give smaller players a credible way to compete at the top of the market.