
What Cosmos 3 Is and Why It Matters for Physical AI
NVIDIA Cosmos 3 is an open world foundation model for physical AI that lets robots, autonomous vehicles and smart spaces understand real-world scenes, predict future events and generate actions through a single mixture-of-transformers architecture. Unlike narrow perception or simulation tools, Cosmos 3 is a robotics foundation model that unifies physical reasoning, world modeling AI and policy learning in one system. It can natively process and generate text, images, video, ambient sound and action trajectories, making it an omnimodel tailored to physical systems instead of chatbots. Cosmos 3 is released as open physical AI models, with weights, training code, datasets and deployment tools available so development can be reproduced and adapted to specific domains. This focus on openness aims to shorten physical AI model training and evaluation from months to days while giving teams a common platform for vision reasoning systems and autonomous vehicle AI.

Inside the Mixture-of-Transformers Architecture
Cosmos 3’s core innovation is its mixture-of-transformers design, which joins a reasoning transformer with an expert generation transformer in a two-tower layout. The reasoner tower acts as a multimodal vision-language model, taking images, video and text as input and inferring motion, spatial relationships and object interactions over time. This gives physical AI systems a structured understanding of the environment before any scene is synthesized or actions are proposed. The generator tower then uses diffusion-based methods, conditioned on that understanding, to produce physics-aware video and action sequences. Because both towers live in a single world modeling AI stack, developers no longer need to stitch together separate perception, simulation and control models. As NVIDIA describes it, this unified architecture lets Cosmos 3 “power perception, prediction and action” with one consistent pipeline for training and deployment.

From Vision Reasoning to World Generation and Action Prediction
Cosmos 3 combines three capabilities that physical AI models need most: vision reasoning, world generation and action prediction. As a vision reasoning system, it can interpret multimodal inputs and answer questions about scenes, trajectories and cause-and-effect. As a world model, it generates rare or hazardous edge-case video data for autonomous vehicle AI and surveillance, and can predict future frames from text, images or video prompts. As a world action model, it links visual context with action trajectories so robots can be trained on video-plus-action pairs rather than static images alone. Developers can use Cosmos 3 Nano on workstation GPUs for real-time robotics or Cosmos 3 Super in data centers for high-fidelity simulation and synthetic data. Both variants share the same interface for text, image, video, audio and action, simplifying experimentation across different physical AI workloads.
OpenMDW Packaging and the Cosmos Coalition
To make Cosmos 3 practical for engineering teams, NVIDIA ships it with OpenMDW-ready packaging that bundles model artifacts, code, documentation and datasets under a single model-centric license. This structure lets developers train, modify, contribute, redistribute and deploy the robotics foundation model without juggling multiple legal agreements. Cosmos 3 checkpoints are hosted on open platforms such as Hugging Face, with scripts and Cosmos NIM microservices available for GPU-optimized deployment. According to NVIDIA, Cosmos 3 is trained on one of the largest multimodal physical AI datasets, covering billions of text, image, video, sound and action samples. NVIDIA has also formed the Cosmos Coalition with partners like Agile Robots, Black Forest Labs, Generalist, LTX, Runway and Skild AI to push the state of world modeling AI and share best practices for physical AI policy model development.
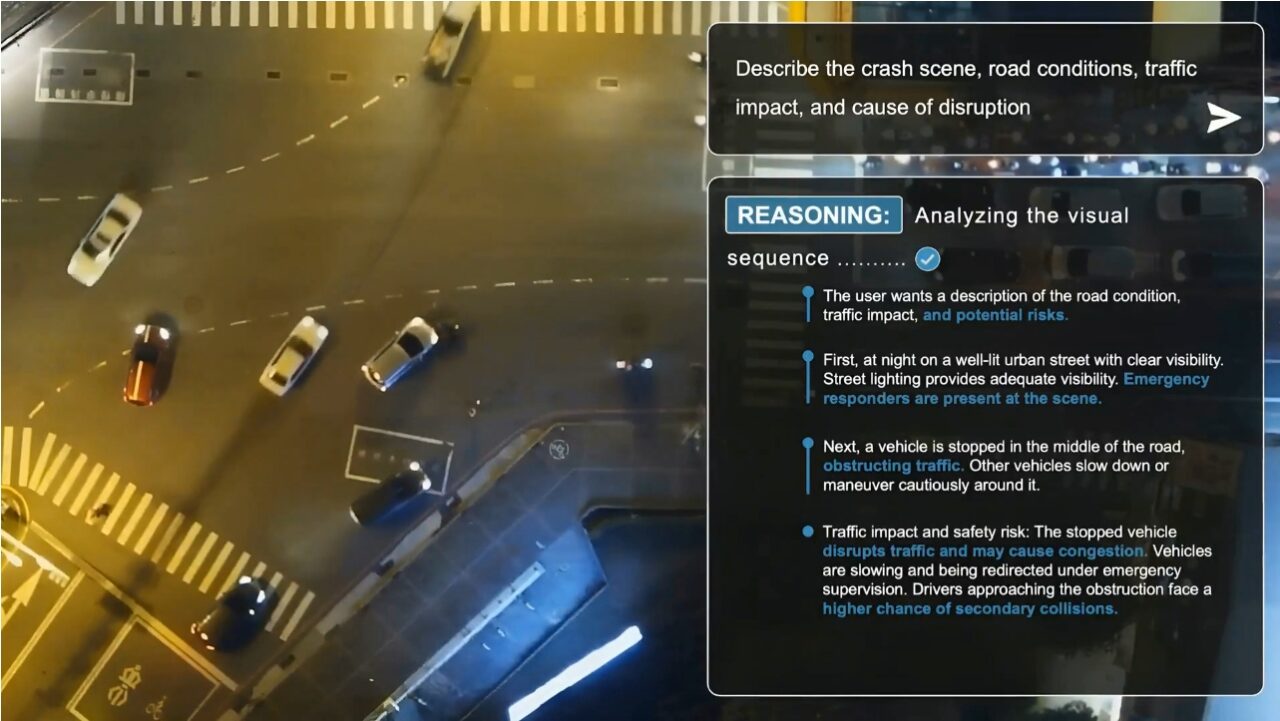
Implications for Robots, Autonomous Vehicles and Smart Spaces
For robotics teams and autonomous vehicle developers, Cosmos 3 reframes how machines learn to operate in dynamic environments. Instead of training separate perception stacks, simulators and controllers, teams can start from a single open world foundation model that already understands motion, collisions and spatial-temporal patterns. This enables robots to preview possible futures before acting, and lets autonomous vehicle AI systems evaluate edge cases in simulated worlds that reflect physics-aware behavior. Warehouse monitoring, safety analytics and large vision systems gain the ability to predict actions and test interventions in synthetic yet realistic scenarios. Because Cosmos 3 is an open physical AI foundation, organizations can fine-tune it on their own sensor feeds, embodiment constraints and tasks, creating domain-specific world models while still benefiting from shared tools, datasets and a common ecosystem around physical AI models.





