What GPU Memory Optimization Means for Enterprise AI
GPU memory optimization in enterprise AI deployment is the set of techniques that reduce padding, fragmentation, and redundant computation so large language models use less memory bandwidth and capacity while preserving model architecture and accuracy. For enterprise teams, the pressure is clear: LLM inference efficiency now controls both user latency and infrastructure bills. Traditional batching turns ragged, variable-length prompts into neat rectangles by padding shorter texts up to the longest sequence. That wastes GPU cycles on zeros and inflates key-value cache footprints. At the same time, retrieval-heavy applications keep recomputing context the model has already processed. The emerging answer is not new model designs but smarter orchestration: hardware-aware sequence packing on the front end and persistent memory engines on the back end that treat attention states as reusable assets instead of disposable byproducts.
Sequence Packing: Stopping GPUs from Multiplying Zeros
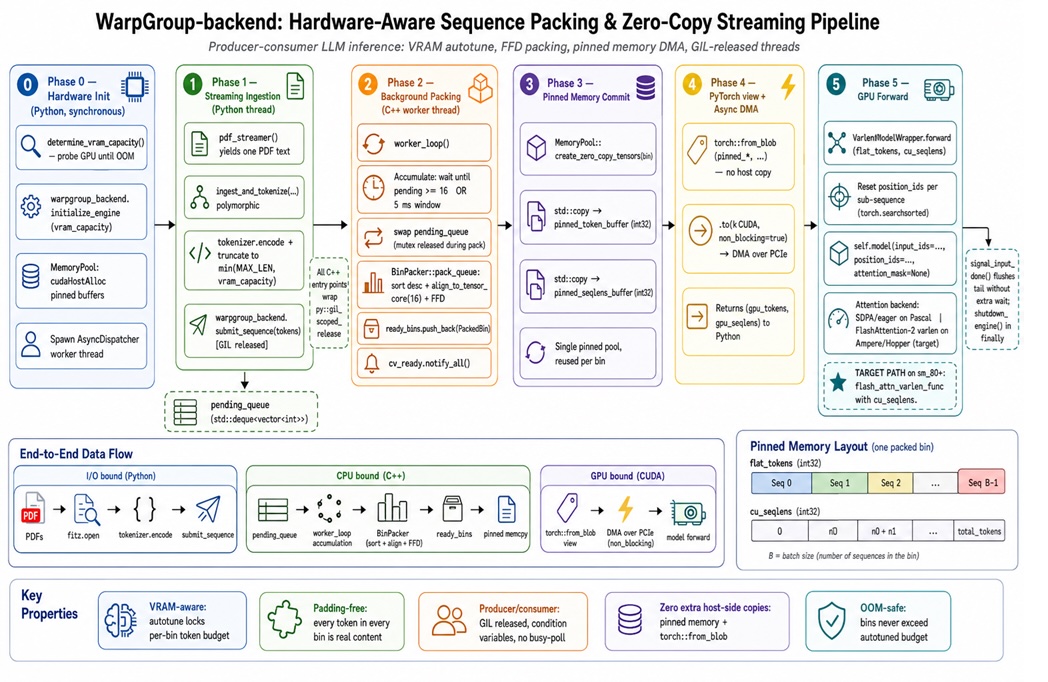
In most production stacks, LLM batching still pads every sequence in a batch to the longest prompt, so GPUs spend a large share of their time multiplying zeros. The WarpGroup-Backend project shows how aggressive sequence packing can reclaim that wasted capacity by turning variable-length requests into a single one-dimensional ribbon and handling attention with variable-length kernels. Instead of naïve padding, it uses VRAM-aware bin packing: sequences are sorted, grouped by total token budget, and packed into bins that match the GPU’s usable memory measured at runtime. It also rounds sequence lengths to hardware-friendly multiples, avoiding throughput loss from awkward tensor shapes. The result is tangible: WarpGroup reports up to 2.08× throughput on an H100 and up to 5.89× on a GTX 1080, with fewer out-of-memory errors and no changes to the underlying transformer architecture.
Hardware-Aware Pipelines: From Python Bottlenecks to Fully Fed GPUs
The gains from sequence packing depend on how requests move from application code to GPUs. Python-centric queues often turn into a single-threaded bottleneck because of the global interpreter lock, especially when the same process must tokenize text, schedule batches, and issue kernels. WarpGroup-Backend addresses this by shifting the hot bin-packing loop into a C++ backend that runs in its own threads and releases the Python lock. A five-phase pipeline measures usable VRAM, streams tokenized sequences into C++, packs them into bins, and uses pinned-memory transfers to keep GPUs busy with large, efficient ribbons. This architecture is hardware-aware in two ways: it sizes bins based on observed VRAM headroom and aligns sequence lengths to the tensor-core tile sizes that deliver peak throughput. The outcome is more reliable LLM inference efficiency: the GPU spends more time on meaningful tokens, less on overhead, and batch sizes grow without operational drama.

Taliesin and Memory Engines: Eliminating Redundant Recomputation
While sequence packing trims per-step overhead, memory engines tackle a deeper cost: recomputing the same context for each query. Corbenic AI’s Taliesin saves the internal memory of a model after it processes a long document and restores that state later, bit-identical to a fresh pass. Instead of re-reading a 100-page report ten times, the model reads it once and then answers follow-up questions from stored key-value memory. Corbenic reports that on a $0.69-per-hour graphics card (approx. RM3.20), the longest test contexts that took more than two minutes to process from scratch were restored in under seven seconds, a 21× speedup. In cross-GPU trials between an Ampere A6000 and an Ada Lovelace RTX 4090, Taliesin produced 64 of 64 identical output tokens and backed results with SHA-256 hashes, showing that AI cost reduction can be achieved without accepting approximate answers.

From Cost Savings to Scalable Enterprise AI Deployment
Together, hardware-aware sequence packing and memory engines point to a new pattern for enterprise AI deployment: make every token and every computed activation count. Sequence packing shrinks padding overhead and GPU memory footprints for live batches, while systems like Taliesin remove the recurring cost of reprocessing long contexts across sessions, users, or even GPU generations. Neither approach needs new model architectures; they work as drop-in optimizations around existing LLMs. For platform teams, this changes the economics of scaling: higher throughput per card, predictable latency for long-context workloads, and the option to shift expensive prefill work to cheaper GPUs and serve from faster ones without losing determinism. As LLM inference efficiency improves, the limiting factor becomes orchestration quality rather than model size alone, rewarding organizations that invest in GPU memory optimization instead of raw hardware expansion.





