What It Means When Open-Source Models Match Frontier AI
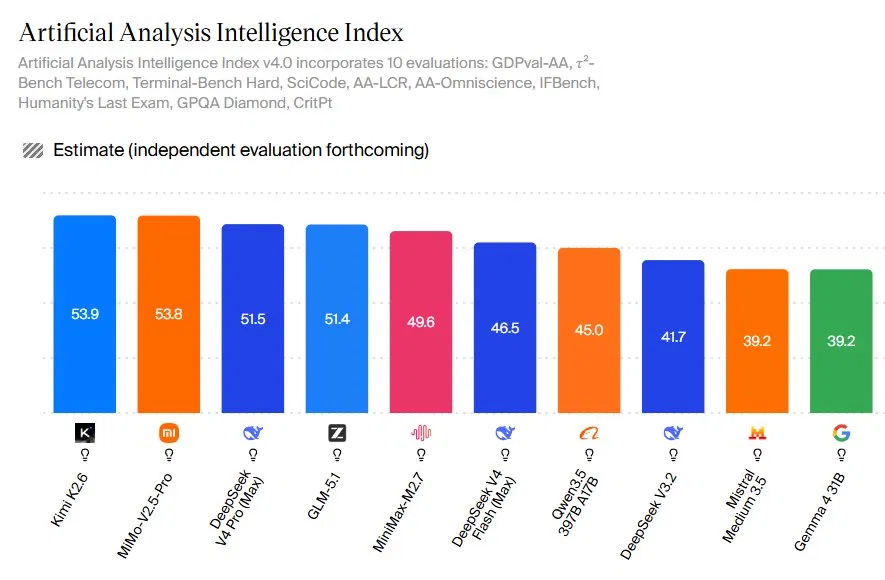
Open-source AI models are advanced language and multimodal systems whose weights are publicly available, and they are increasingly able to match or approach the task performance of frontier proprietary models on coding, reasoning, agentic workflows, and long‑context analysis while being far more cost effective AI options for organisations and individual developers. The Artificial Analysis Intelligence Index now shows open-source leaders posting scores that push into territory once reserved for closed systems. Moonshot AI’s Kimi K2.6 tops the open list at 53.9, while MiniMax’s MMo‑V2.5‑Pro and DeepSeek V4 Pro (Max) trail by a narrow margin. In a frontier AI comparison, the standout fact is that DeepSeek V4 Pro’s Codeforces rating of 3206 beats GPT‑5.4 and Gemini‑3.1‑Pro on coding. For buyers, the “best AI models 2026” discussion has shifted from simple league tables to a more practical question: which specific model fits a concrete job.
Task-Specific Strengths: From Agents to Long Context
The new generation of open source AI models is designed around practical workloads rather than abstract benchmarks. Kimi K2.6, for example, focuses on long‑running agentic tasks: it autonomously refactored an eight‑year‑old financial matching engine over 13 hours, making more than 1,000 tool calls and delivering a 185% throughput improvement. GLM‑5.1 posts the highest Artificial Analysis Agentic Index score among open‑weights models at 63, showing how far agent performance has come. Long‑context reasoning is another area where open models now shine in frontier AI comparison. MiniMax’s MMo‑V2.5‑Pro can process up to one million tokens, making it suitable for legal archives, codebases, and complex research. DeepSeek’s V4 series and MiniMax’s M‑series are tuned for reliable multi‑step tool use, including shell, browser, retrieval, and code. For teams, this means model selection can focus on concrete workflows instead of one-size-fits-all rankings.
Speed and Throughput: Why Tokens per Second Matter
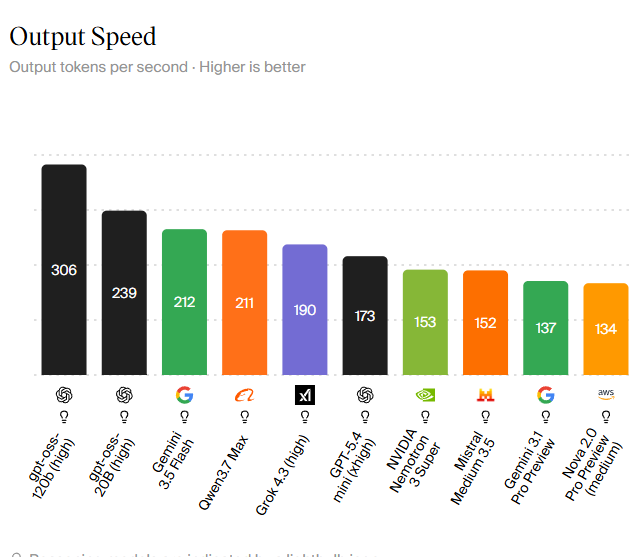
Speed has become as important as raw intelligence in AI model performance. The Artificial Analysis data on the fastest AI models shows how throughput can change user experience. GPT‑oss 120B on a high‑compute tier leads with 306 tokens per second, while GPT‑oss 20B reaches 239 tokens per second. Gemini 3.5 Flash delivers 212 tokens per second and ranks among the most capable models on that list. Open source AI models are competitive here too. Qwen3.7 Max outputs 211 tokens per second, essentially neck‑and‑neck with Gemini 3.5 Flash, and Mistral Medium 3.5 reaches 152 tokens per second while maintaining an efficient, open‑weight profile. For developers and enterprises comparing the best AI models 2026, throughput is more than a vanity statistic: fast responses make coding assistants, chat tools, and autonomous agents feel usable rather than sluggish, especially when scaled across thousands of requests.
Cost Efficiency and the New Economics of Model Choice
Cost is where open models often gain a decisive edge. DeepSeek V4 Flash (Max) is a clear example of cost effective AI: it scores 46.5 on the Intelligence Index yet is significantly faster and cheaper to run than V4 Pro. According to Artificial Analysis, “Flash comes in at USD 113 (approx. RM520) to run the full Intelligence Index benchmark suite, versus USD 1,071 (approx. RM4,920) for V4 Pro.” Architectural choices support this efficiency. Models such as DeepSeek V4 Flash and MiniMax’s MoE‑based systems keep only a subset of parameters active during inference, reducing compute needs without gutting capability. Qwen 3.5’s flagship variant is released under Apache 2.0, enabling on‑premise deployment without separate licensing deals. For many teams, these economics mean an open model can meet or exceed their needs at a fraction of the frontier bill.
From Leaderboards to Use-Case-First Model Selection
The maturing landscape means there is no single winner among the best AI models 2026. DeepSeek itself says its V4 Pro trails frontier closed models by roughly three to six months, yet it leads all tested systems on Codeforces. GLM‑5.1 cuts hallucinations through disciplined abstention when uncertain, which may matter more to a regulated industry than a tiny gap in headline benchmark scores. For many buyers, the frontier AI comparison now starts with a use‑case checklist: Is long‑context analysis critical? How important is speed-per-dollar? Will the team benefit more from top‑tier coding or from high‑reliability agents? In many scenarios, open source AI models now match or closely track closed systems on the metrics that count. The result is a more competitive market where model choice is driven by fit, speed, and total cost rather than by brand or hype.





