
From Experiments to Enterprise: The Scaling Gap in Machine Learning
Enterprises are discovering that the hardest part of AI is no longer building a working model, but running it sustainably at scale. Teams can prototype quickly with modern tooling, yet struggle to turn these proofs of concept into production-grade systems that balance reliability, cost, and governance. This “last mile” problem spans machine learning production scaling, model lifecycle management, and inference platform architecture. It involves imperfect data, messy lineage, and operational complexity that traditional pipelines were never designed to handle. At the same time, real-time use cases—such as large-scale personalization or AI-assisted communication—demand low latency and strict service-level objectives. Netflix and Databricks are approaching this challenge from different angles: Netflix with a metadata-driven, graph-based view of ML assets, and Databricks with a high-throughput inference platform co-engineered with customers. Together, their approaches illustrate what modern enterprise ML infrastructure must look like.
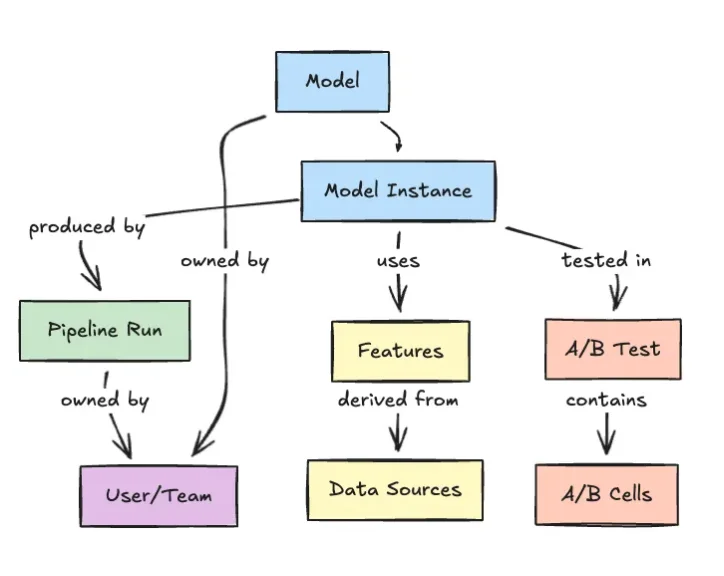
Netflix’s Model Lifecycle Graph: Making ML Assets First-Class Citizens
Netflix’s Model Lifecycle Graph reframes ML systems as interconnected entities rather than isolated pipelines. Instead of treating datasets, features, models, evaluations, workflows, and production services as separate artifacts, the company models them as nodes in a graph with explicit relationships. This enables engineers to traverse lineage end-to-end: from upstream datasets to derived features, through training and evaluation, and into the services where models are deployed. The result is richer model lifecycle management, better discoverability of reusable assets, and clearer impact analysis when anything changes. In large organizations, small schema tweaks or feature deprecations can ripple across many teams; the graph provides a shared source of truth for understanding those dependencies. By making these relationships first-class infrastructure concerns, Netflix is supporting machine learning production scaling in a way that aligns with increasingly interconnected ML ecosystems, where models depend on many evolving components rather than a single static pipeline.
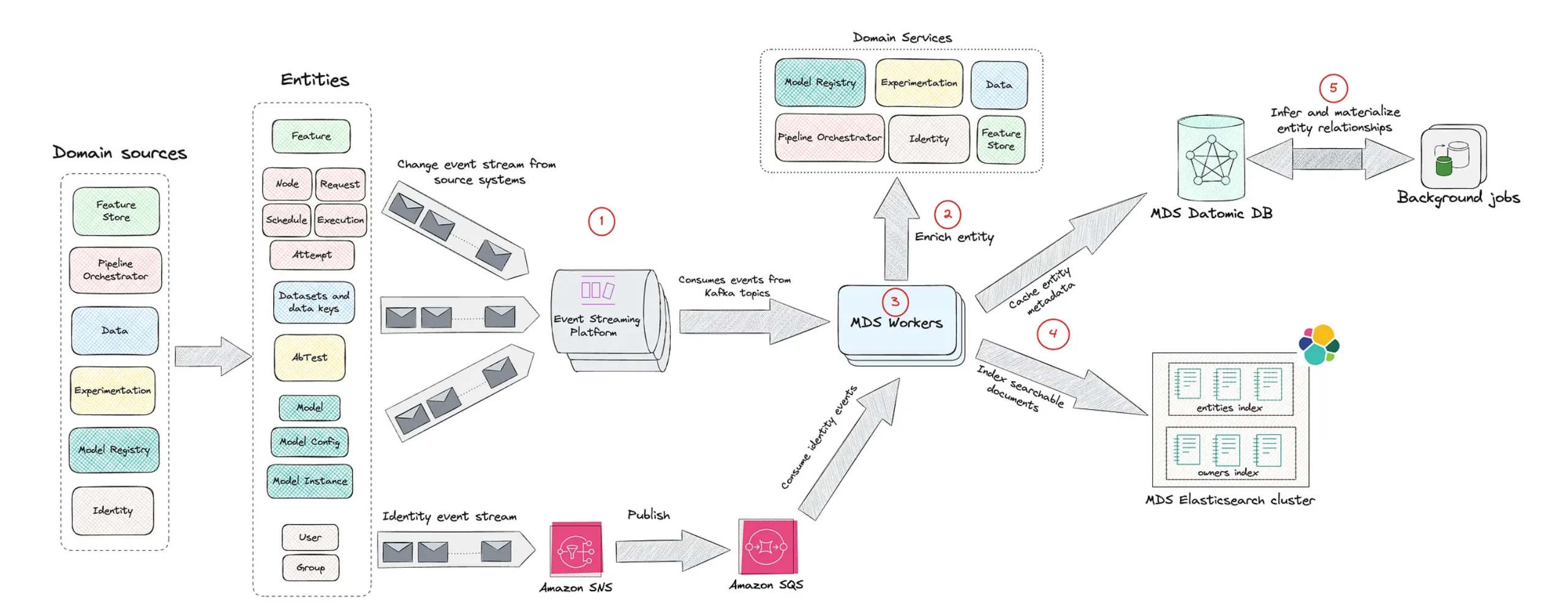
Databricks and Superhuman: Architecting a 200K QPS Inference Platform
On the serving side, Databricks and productivity platform Superhuman have built an inference stack that illustrates what enterprise-grade architecture looks like under extreme load. Superhuman’s custom large language model powers grammatical error correction across more than 40 million daily users, hitting over 200,000 queries per second with roughly 50 input and 50 output tokens per request. By migrating from a DIY vLLM-based stack to Databricks model serving, the teams co-designed an inference platform architecture that meets sub-second p99 latency and strict four-nines reliability. Core elements include an Endpoint Discovery Service that drives a power-of-two-choices load balancer to avoid hotspots, aggressive-but-stable autoscaling based on request concurrency, and optimized container startup via image acceleration for rapid scale-up during traffic ramps. This collaboration shows that high-throughput, low-latency inference is as much about close engineering partnership and infrastructure design as it is about the underlying model.
Imperfect Data, Human-in-the-Loop, and the Hidden Costs of Production ML
While infrastructure matters, production ML also lives in a world of imperfect data and unpredictable outputs. Joe Rose of JBS Dev argues that enterprises don’t need flawless data lakes or multi-year transformation programs before they can deploy generative or agentic AI. Modern tools—and large language models in particular—are increasingly resilient to messy inputs, from half-written prompts to unstructured documents like PDFs and images. In one medical billing project, generative AI helped extract and reconcile records across inconsistent formats, with humans in the loop to validate ambiguous cases. This illustrates a broader reality: production ML is less about pristine datasets and more about building systems that can detect, handle, and gradually improve around noisy data. It also surfaces hidden costs: monitoring, guardrails, and human review all add ongoing operational overhead that must be factored into any sustainable enterprise ML infrastructure plan, beyond the headline model capability itself.

Converging Lessons: Designing Sustainable Enterprise ML Infrastructure
Taken together, Netflix’s graph-based lifecycle management, Databricks’ high-throughput inference platform, and JBS Dev’s pragmatic stance on imperfect data point toward a new blueprint for enterprise ML infrastructure. Organizations need metadata-centric views that make dependencies and lineage traversable; scalable inference architectures that balance latency, reliability, and cost; and workflows that embrace human-in-the-loop oversight rather than chasing unrealistic data perfection. The gap between prototype and production narrows when ML assets are treated as part of a living system, not one-off projects. That means investing in model lifecycle management, building inference platforms that can handle spikes without exploding costs, and designing processes that accept model and data imperfections. For enterprises, machine learning production scaling is no longer just a technical challenge; it’s an architectural and organizational one, where success depends on aligning tools, platforms, and people around the realities of running AI systems over time.