
Why AI Memory Pricing Is Now Everyone’s Problem
For organizations deploying large AI models, memory chip costs have quietly become one of the biggest line items in the hardware budget. In the “before times,” it was common to overprovision DRAM because it was relatively cheap and made capacity planning easy. That habit is now dangerous. When AI memory pricing spikes, every unnecessary gigabyte means fewer nodes can be deployed and projects slow down or shrink. Overprovisioned RAM also hides architectural issues, such as inefficient model placement or poorly tuned virtual machines. The challenge is no longer just buying enough memory, but buying exactly the memory capacity your workloads truly need. To fight back, you need the same weapon driving these costs: AI. AI-powered analysis can reveal real working sets, reclaimable cache, and wasteful allocation patterns across fleets, helping you make surgical decisions instead of repeating old, expensive configurations.
Profile Your Workloads: From Single Workstation to Full Fleet
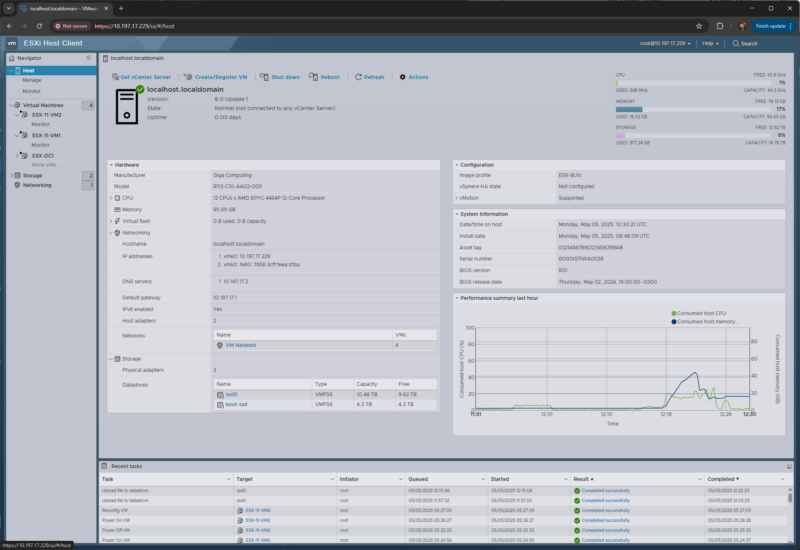
The first step in AI infrastructure optimization is understanding how memory is actually used, not just how much is installed. On virtualized hosts, platforms such as ESXi and vCenter expose key signals like active memory, ballooning, compression, and swapping. Similar insights exist in Proxmox VE, KVM, Hyper-V, and Kubernetes, where you can track container memory limits, PSI memory pressure, and out-of-memory events. For smaller environments, tools like Task Manager, top, htop, free, vmstat, or Netdata work well if you monitor them over a realistic time window. Aim for at least a full business cycle that captures peaks from backups, patching, model loading, and traffic surges. The goal is to derive sustained and peak working sets after stripping out reclaimable cache and normal OS housekeeping. Once you have this data, you can stop blindly cloning 512GB servers “because that’s what we always do,” and start targeting 256GB or 384GB where appropriate.
Let AI Find the Hidden Waste in Your Memory Footprint
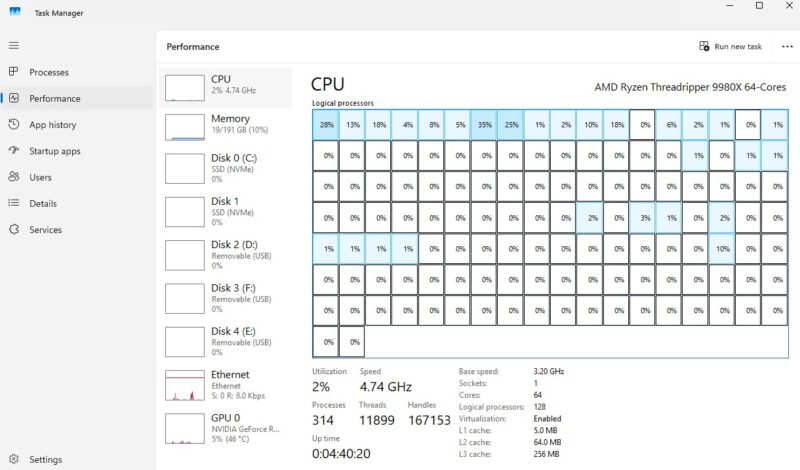
Collecting telemetry is only half the battle; making sense of it across hundreds or thousands of systems is where AI tools shine. Modern AI agents can ingest time-series memory metrics and quickly highlight patterns humans miss: hosts that never exceed 40 percent working set, VMs with huge allocations but low p95 usage, or nodes quietly swapping under peak load. They can separate memory-resident workloads—like key database or cache tiers that should remain generously provisioned—from front-end services that are ideal candidates for downsizing. Visualization is critical here. Allocated-versus-observed dashboards instantly reveal where slack is concentrated and which systems deserve human review first. AI does not replace that review, but it accelerates it. With multiple AI agents and prompts, you can get several independent optimization suggestions, then compare and refine them into a confident right-sizing plan to reduce memory expenses without risking critical performance.
Case Study: Turning Memory Insights into Concrete Savings
Consider a server originally purchased with 512GB of RAM because that was the historical standard for its workload class. After a month of AI-assisted profiling, the p95 working set—excluding reclaimable caches and OS overhead—sits around 170GB, with a p99 of 220GB. In the past, that gap between installed and needed capacity would have gone unnoticed. With AI-generated analytics and clear visualizations, the overprovisioning becomes obvious. Armed with this data, architects can confidently specify 256GB for new nodes, or 384GB if occasional quarterly spikes appear, rather than reflexively cloning 512GB. Across a fleet, AI highlights other similar candidates while flagging true memory-resident systems that should remain untouched. The outcome is a measurable reduction in memory chip costs and the ability to deploy more nodes or cores within the same budget, instead of burning resources on unused DRAM headroom.
Practical Steps to Reduce Memory Expenses in Any Organization
You do not need a dedicated test lab to benefit from AI infrastructure optimization. Start by enabling detailed memory monitoring on your existing stack—virtualization hosts, containers, and bare-metal nodes alike. Next, export that data into an observability platform or data lake that AI tools can access. Use AI agents to classify workloads into three buckets: clearly overprovisioned, clearly memory-resident, and ambiguous. For easy wins, right-size reversible workloads such as stateless web frontends, ensuring you can roll back quickly if needed. For databases and critical AI inference tiers, consider softer controls like ballooning policies rather than hard cuts. Re-run the AI analysis after changes to validate impact and catch new bottlenecks. Even small environments, such as a single VPS, can follow the same pattern to justify moving to a smaller instance and lowering recurring memory expenses over time.