
What the Next-Generation OpenSearch Serverless Actually Is
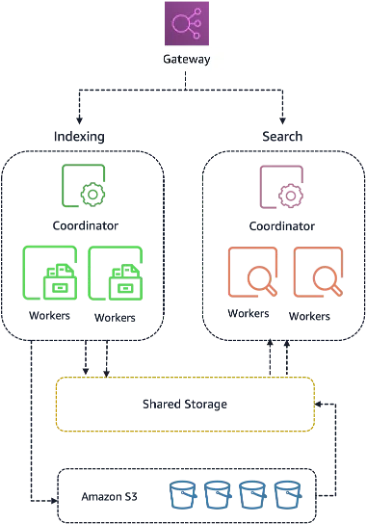
The next-generation OpenSearch Serverless is a fully managed search and vector engine from AWS that separates compute from storage to deliver 20x faster resource provisioning, true scale-to-zero behavior, and lower costs for unpredictable AI workloads. In practice, it runs text and vector search as a serverless service on top of the open-source OpenSearch project, but with a proprietary shared storage layer that makes compute nodes stateless. This new AWS serverless architecture targets agent-led development, where coding assistants, retrieval-augmented generation, and autonomous agents generate sharp bursts of traffic instead of steady, human-driven patterns. By turning OpenSearch Capacity Units into stateless workers that mount shared storage on demand, AWS can bring capacity online in seconds, release it when idle, and shield developers from cluster sizing decisions that used to slow down AI workload infrastructure planning.
Decoupled Storage and Compute: The Heart of the Redesign
AWS’s NextGen OpenSearch Serverless architecture introduces a shared storage layer that fully decouples data from compute, turning OpenSearch Capacity Units into stateless workers. Because data no longer lives on the compute nodes, those OCUs do not need to bootstrap local disks before serving queries; they attach shared storage on startup and begin handling requests within seconds. According to AWS, this change makes resource provisioning 20 times faster than the previous serverless design and allows collections to “shrink all the way to zero when nothing's happening.” Efficient scale down follows directly from this separation: idle compute capacity can be dropped without risking data loss or lengthy recovery. AWS keeps this storage layer proprietary for now, which gives it room to tune performance and reliability for emerging AI workload infrastructure needs without being constrained by the open-source core.
AI Agents, Bursty Traffic, and the Need for Serverless Search
Agent-led development changes how search infrastructure is used: autonomous coding agents, retrieval flows, and chained tools generate unpredictable spikes of requests rather than steady human-driven traffic. Historically, search did not need to split storage and compute because workloads were more stable, but agentic AI can cause sudden bursts followed by long idle periods. AWS argues that even sophisticated teams now benefit from a serverless OpenSearch Serverless model that scales with these patterns. Collections can scale down to zero capacity, and when an agent restarts or a new workflow kicks in, the platform can restore compute within seconds instead of minutes. This combination targets both developer productivity and cost control, since users are not forced to keep clusters provisioned for peak load when most of the time traffic is low, sporadic, or test-oriented during agent experimentation.

Serverless Abstraction and Network Simplification for Developers
The new OpenSearch Serverless experience is designed so developers spend less time on infrastructure and more on agent logic and application behavior. Collections are now organized into collection groups, which define whether they use the Classic or NextGen architecture and can share compute across workloads to improve efficiency for smaller deployments. A new regional endpoint format gives each account a single hostname per region, with the target collection identified via headers, which simplifies connection pooling and TLS session reuse for AI workload infrastructure. Engineers can create NextGen collections via the AWS console, SDK, or CLI, with an Express console mode for quick setup. AWS is expanding integrations with platforms like Vercel and agent-focused IDEs such as Cursor and Kiro, letting developers spin up OpenSearch Serverless collections directly from their existing workflows without managing clusters, nodes, or scaling policies.
Positioning Against Competing AI Search and Vector Engines
Amazon OpenSearch Serverless sits in a crowded landscape of search and vector engines aimed at AI applications. Elasticsearch Serverless offers a similar managed search and analytics service, while PostgreSQL with pgvector appeals to teams that want to extend an existing database rather than adopt a dedicated search engine. Specialist vector databases like Pinecone focus on high-performance similarity search for retrieval-augmented generation workloads. AWS is betting that its serverless architecture, shared storage, and tight integration with AI development tools will make OpenSearch Serverless a foundational component for agentic AI. The service promises “up to 60 percent cost savings compared to the cost of OpenSearch Service clusters provisioned for peak capacity,” giving teams a path to scale experimental agents into production without a parallel expansion in cluster management effort or overprovisioned infrastructure.





