
What Effort Controls in Claude Opus 4.8 Actually Do
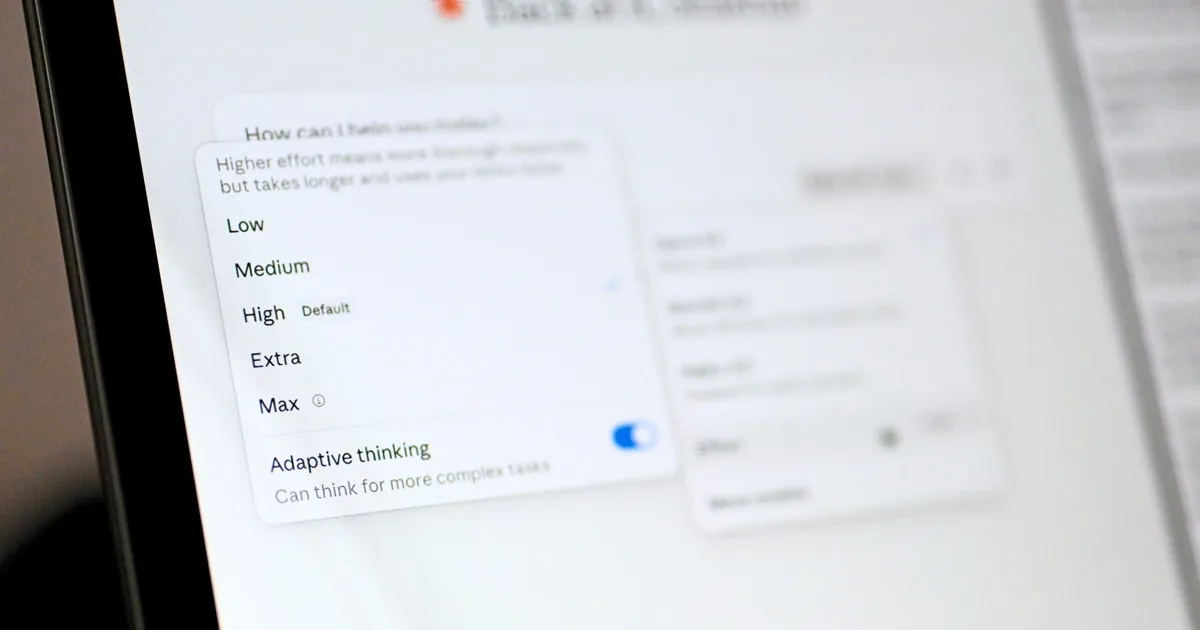
Claude Opus 4.8 effort controls AI thinking speed by letting users choose how intensively the model reasons before responding, trading deeper multi-step analysis for slower replies and higher rate-limit usage, or favoring rapid, lightweight reasoning for quick answers and lower cost. Instead of Claude deciding how much to “think” behind the scenes, a new effort selector now sits alongside the model picker on claude.ai and Claude Work, giving users direct control over the model’s internal reasoning budget. Opus 4.8 offers five effort levels: Low, Medium, High (the default), Extra, and Max. Low effort aims for fast, concise replies that suit routine questions, email drafts, and everyday chats. High, Extra, and Max push Claude to explore more options, run more self-checks, and build longer chains of thought, which benefits complicated tasks, but will consume tokens and rate limits more quickly.

Fast Mode vs. Standard Reasoning: How AI Thinking Speed Changes
Fast mode reasoning in Claude Opus 4.8 gives users a way to get quicker replies without changing models. According to Anthropic, Fast mode runs at about 2.5 times the previous speed while costing around one-third less than standard Opus 4.8 reasoning for the same workload. Under the hood, it is the same core model, but configured to prioritize shorter reasoning paths and tighter outputs. That makes Fast mode a strong fit for chat-style questions, quick summaries, or rapid-fire coding edits where turnaround matters more than exhaustive analysis. Standard effort levels still remain for deeper work, allowing you to mix and match: you might explore ideas or iterate code in Fast mode, then switch to High or Max effort for a final, carefully checked answer. Both modes share the same safety alignment and benchmark gains introduced in Opus 4.8.
When to Use Low, Medium, High, Extra, and Max Effort
Effort controls AI behavior most clearly in how long Claude thinks before it answers, so it helps to map each level to typical tasks. Low effort fits trivial questions, casual brainstorming, and short replies, where a near-instant answer beats nuanced reasoning. Medium works well for everyday productivity: clearer emails, short reports, and straightforward code fixes. High (the default) is ideal for moderate complexity, such as multi-step instructions, non-trivial bug hunts, or structured planning. Extra and Max are for your hardest problems: dense legal-style analysis, long reasoning chains in research, or complex comparisons that benefit from Claude’s stronger self-checks. Because higher effort consumes more tokens and may hit rate limits faster, a practical pattern is to start with Low or Medium to frame the problem, then rerun the most important prompts at Extra or Max for a more reliable final result.
Dynamic Workflows and Coding: Effort Controls for Developers
For developers, Claude Opus 4.8 combines effort controls with new dynamic workflows in Claude Code to tackle large-scale engineering tasks. The model can now plan a big job, spin up hundreds of parallel sub-agents within one session, and verify outputs before returning results. On benchmarks, Opus 4.8 reached 69.2% in agentic coding tests, 74.6% on Terminal Bench 2.1, and 83.4% on OS World Verified, showing stronger coding and agentic skills. Effort levels influence how carefully those sub-agents inspect code, reason about tests, and cross-check changes. For a huge refactor, you might keep early exploration in Low or Medium effort Fast mode, then shift to High or Extra effort for final merge suggestions. The updated Messages API also allows mid-task system messages, so teams can adjust instructions, budgets, or permissions while preserving prompt cache, making the whole workflow more flexible.
Pricing, Reliability Gains, and How to Pick the Right Mode
Anthropic keeps Claude Opus 4.8 pricing the same as Opus 4.7 for standard usage at USD 5 (approx. RM23) per million input tokens and USD 25 (approx. RM115) per million output tokens, despite adding effort controls, Fast mode, and dynamic workflows. Early users report better judgment and reliability, especially for legal and other agentic work, with Opus 4.8 about four times less likely than 4.7 to miss flaws in its own code. In practice, that means you can choose effort based on stakes: use Fast mode and Low or Medium effort for drafts, experiments, and routine tasks, then reserve High, Extra, or Max for decisions that demand more careful reasoning. Because the same aligned model underpins every mode, effort controls AI thinking depth rather than safety, so your main trade-off is speed, cost, and thoroughness—now squarely in your hands.





