Cost-Efficient AI Coding: How Composer 2.5 Changes the Equation
Cursor’s new Composer 2.5 model is designed to drive AI coding cost efficiency while boosting reliability on real projects. Built on the same open-source Kimi K2.5 checkpoint as Composer 2, the upgrade focuses on smarter post-training rather than an expensive base-model swap. Pricing remains aggressive: standard Composer 2.5 access is set at USD 0.50 (approx. RM2.30) per million input tokens and USD 2.50 (approx. RM11.50) per million output tokens, with a faster default tier at USD 3.00 (approx. RM13.80) per million input and USD 15.00 (approx. RM69.00) per million output. Cursor claims these refinements yield up to 10x cost efficiency compared to earlier versions once benchmarked against capability. That positions Composer 2.5 as an affordable AI coding tool aimed squarely at developers who want premium-grade assistance for multi-file edits, refactors, and debugging without paying the typical enterprise-agent price tags of top proprietary models.
Synthetic Training at 25x Scale and Reinforcement Learning Coding Gains
The performance jump in Composer 2.5 comes not from a new foundation model but from scaled training on synthetic workloads and more targeted reinforcement learning coding strategies. Cursor reports a 25x increase in synthetic task training compared with Composer 2, exposing the model to a much larger variety of generated coding scenarios before it ever touches live repositories. On top of this, Cursor adds tougher RL environments plus localized textual feedback inside trajectories, inserting short hints directly where the model’s behavior should change. This targeted reinforcement learning correction is meant to fix specific mistakes while preserving high-level objectives, improving long-horizon planning and tool use. The result is a coding agent that can sustain longer task rollouts, better adhere to nuanced instructions, and show more consistent communication style and effort calibration—all without changing the underlying Kimi K2.5 base.

Benchmarks: Terminal-Bench, SWE-Bench and CursorBench Improvements
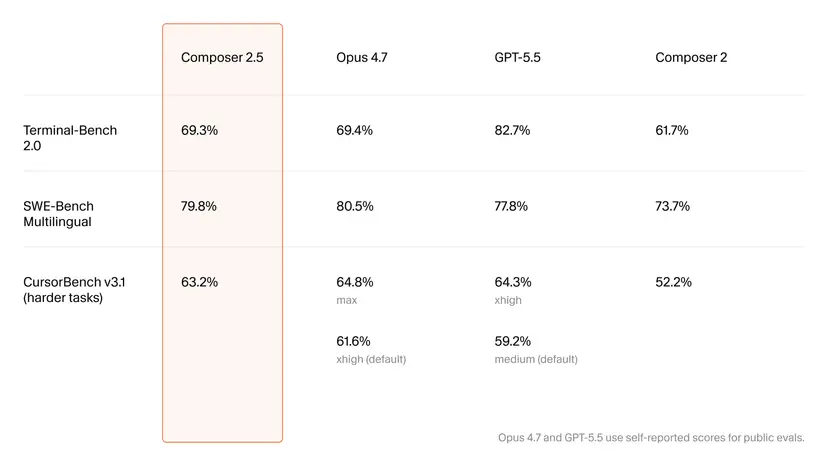
On paper, Composer 2.5’s benchmark results suggest the synthetic training and RL upgrades are paying off. Cursor says the model’s score on Terminal-Bench 2.0 rises from 61.7% in Composer 2 to 69.3% in Composer 2.5, indicating stronger command-line and tool-usage performance. On its in-house CursorBench v3.1, the model jumps from 52.2% to 63.2%, targeting agent-style, multi-step coding tasks that resemble repository work more closely than isolated completions. Composer 2.5 also records 79.8% on SWE-Bench Multilingual, reflecting meaningful gains in code-generation accuracy on standardized tasks. While benchmarks cannot fully guarantee real-world productivity, they do point to concrete progress in areas that matter to coding agents: planning, tool invocation, and consistency across longer trajectories. These improvements directly support Cursor’s pitch that better post-training can rival bigger, more expensive models on practical developer workloads.
How Composer 2.5 Stacks Against Claude Opus and Other Premium Models
Composer 2.5 enters a crowded field dominated by premium tools like Claude Opus 4.7 and the latest GPT-family coding assistants. According to Cursor, Composer 2 already beat Opus 4.6 on coding benchmarks at a fraction of the price, and Composer 2.5 narrows the gap further. The new release reportedly matches or approaches Claude Opus 4.7 on several coding benchmarks, even edging past GPT-5.5 by 2% on SWE-Bench Multilingual, while still undercutting proprietary models on token pricing. This positions Composer 2.5 as a cost-competitive alternative for teams that want Claude-level capability without Claude-level bills. However, even Cursor acknowledges that benchmarks are only a proxy. Developers still need to validate multi-file refactors, repository-wide consistency, and tool-call robustness in day-to-day workflows before declaring Composer 2.5 a true replacement for top-tier commercial coding agents.
Longer Coding Jobs, Real-World Limits, and What Comes Next
A major claim behind Composer 2.5 is better handling of long-running coding jobs. Cursor’s targeted feedback during RL is specifically aimed at the credit-assignment problem that often derails multi-step agents midway through a task. Early internal tests reportedly show stronger performance on sustained coding tasks and more accurate tool calls than previous versions. Yet initial user feedback is mixed, with some developers noting that Composer 2.5 can still drift modes or lose track of multi-step tasks and then attempt to recover context. That reflects a broader industry pattern: model intelligence on paper does not always translate cleanly into coding productivity. Cursor is already collaborating with SpaceXAI on a larger model using significantly more compute, suggesting the company sees Composer 2.5 as both a practical upgrade and a stepping stone toward even more capable, still cost-efficient AI coding platforms.