
What GPU Memory Expansion over Thunderbolt Claims to Do
Thunderbolt GPU memory expansion is an emerging approach where high‑speed external storage pretends to be extra video memory, promising to let laptops run larger local AI models without buying expensive new hardware. The core idea is simple: if you can make GPUs think they have more memory, you can fit bigger large language models, improve local GPU acceleration for LLM inference on a laptop, and reduce reliance on cloud APIs. In practice, that means pushing data across a Thunderbolt cable fast enough that GPU kernels do not stall waiting for tokens or activations. It also means treating flash storage like a slower extension of VRAM, while keeping the most frequently accessed tensors on the physical GPU. Whether this works smoothly depends on bandwidth, latency, software support, and how cleverly models stream weights in and out.
OWC Stack AI: Inflating Thunderbolt GPU Memory on Desktops
OWC’s Stack AI is the first product to openly promise VRAM expansion over Thunderbolt, rather than a conventional external GPU. The aluminum “Thunderbolt 5 AI Accelerator and Storage Hub” connects over Thunderbolt 5 and exposes high‑speed flash that, according to OWC, “uses onboard high-speed flash to expand the onboard VRAM of a PC’s graphics card.” The marketing pitch is clear: let your Mac or PC handle far larger LLMs locally by turning the Stack AI into extra Thunderbolt GPU memory, instead of paying for cloud inference or buying a high‑memory workstation. Today the company is targeting Windows and Linux at launch, with Mac support promised later. OWC positions this as a portable edge AI processing brick you can share across desks, especially for AI research teams and businesses that hit GPU memory limits long before they run out of compute.
Technical Reality Check: Bandwidth, Latency, and Model Size
Even with Thunderbolt 5, extending VRAM over a cable means facing slower access than on‑package memory. True GPU memory sits directly on the graphics card with extremely high bandwidth and low latency. Flash accessed via Thunderbolt cannot match that, so performance hinges on smart streaming rather than pretending everything is uniform RAM. In realistic LLM inference on a laptop, that likely means keeping active layers and key‑value caches in physical VRAM while paging colder weights to and from the Stack AI. Thunderbolt 5’s bandwidth may be enough to keep tokens flowing for medium‑sized models, but long context windows or multimodal workloads will stress the link. Compared with multi‑Mac Thunderbolt clusters that share both memory and compute, a Stack‑style device focuses on memory pressure alone, leaving you dependent on the GPU cores you already have.
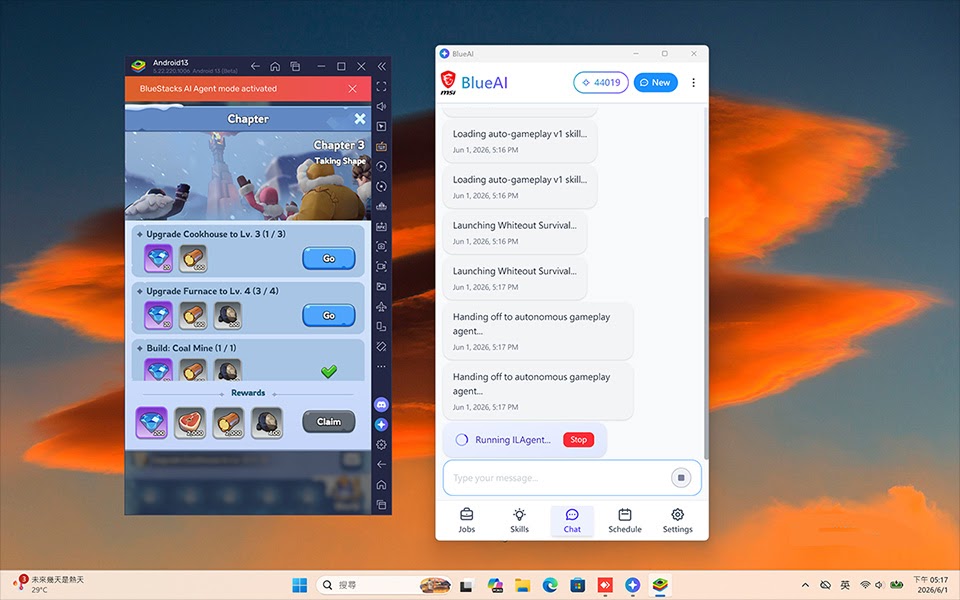
MSI and BlueStacks: Local GPU Acceleration for Everyday Agents
On gaming laptops, MSI and BlueStacks are attacking the same cost and privacy problem from the opposite angle: use GPU power you already own rather than rent cloud time. Their Blue AI Worker is a local‑first AI agent that runs a vision language model on the laptop’s GPU, reading the screen directly instead of streaming high‑resolution game footage to remote servers. According to MSI’s announcement, the software shifts “heavy visual processing duties from cloud servers onto hardware the user already possesses: a dedicated graphics processing unit.” Only high‑level reasoning calls go to the cloud, so bandwidth and token bills shrink. MSI will even show a “Token Mileage” estimate of annual savings for different RTX GPUs at an assumed 10 million visual tokens per month, turning local GPU acceleration into a tangible number on the spec sheet.
Is GPU Memory Expansion over Thunderbolt Ready for Large Local LLMs?
Taken together, OWC Stack AI and MSI’s Blue AI Worker show a clear direction: edge AI processing is becoming standard, not a hobby project. Stack AI chases bigger models by stretching effective VRAM, while Blue AI Worker stretches value by filling otherwise idle GPU cycles with agents that summarize screens, capture highlights, or sort inventories. For anyone eyeing local LLM inference on a laptop, the key question is not whether Thunderbolt can add capacity, but whether the bandwidth gap keeps response times acceptable as model sizes grow. In the near term, this tech looks best suited to mid‑sized models and task‑specific agents rather than giant, frontier‑scale LLMs. Still, as software stacks mature and GPUs integrate smarter memory tiering, plugging in a Thunderbolt box to “upgrade” your model size could become as normal as adding external storage.





