What Google’s AI Overview Is—and Why Spelling Matters
Google’s AI Overview is a Gemini-powered feature that generates brief, AI-written summaries at the top of search results, reshaping how people find and trust information by answering queries directly instead of sending users to underlying web pages. Designed to save time and reduce clicks, these summaries now act as many users’ first—and sometimes only—interaction with a topic. That makes the accuracy and basic literacy of AI search responses more than a cosmetic issue. When a system that claims to synthesize the web for you cannot spell common words, it raises doubts about how carefully it handles more complex tasks such as interpreting domain-specific jargon, summarizing research, or answering health and finance questions. Spelling should be the easy part of AI search reliability. The fact that it is not hints at deeper LLM accuracy issues built into how these models work.
From Glue on Pizza to ‘Astronomical’ Misspellings
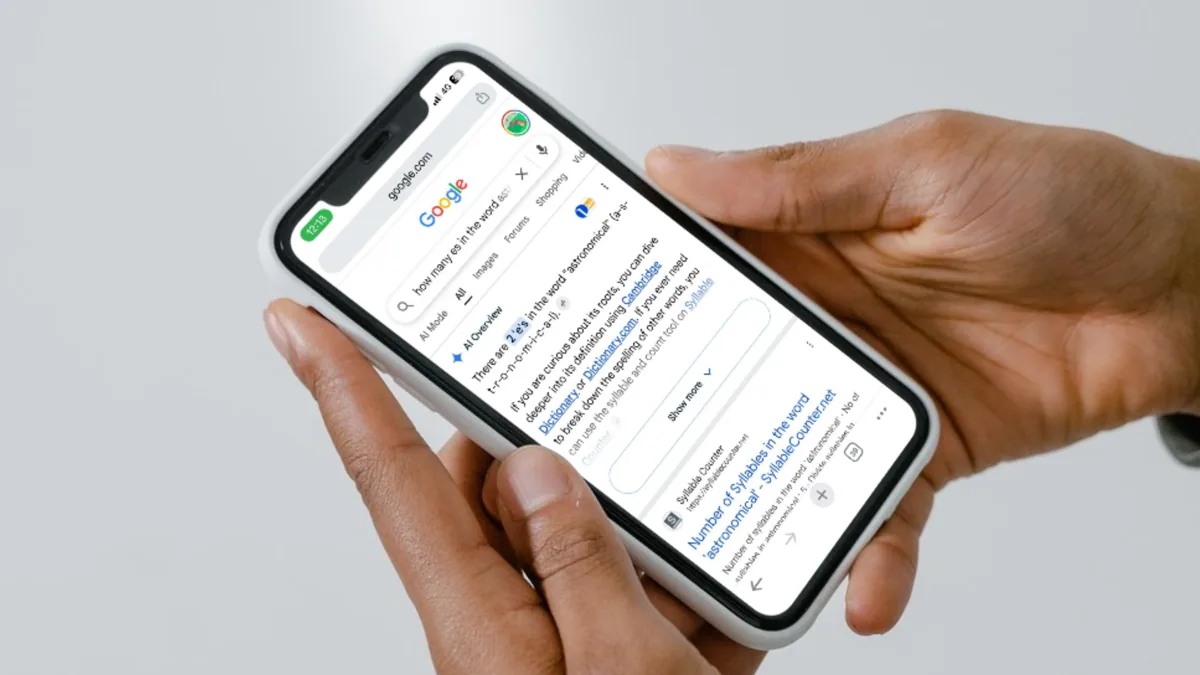
Google AI Overview launched with high-profile hallucinations, including telling users to drizzle “glue on pizza,” and prompted criticism over unreliable answers. While Google has improved the system since 2024, it still trips over basic questions. Mashable notes that Google’s AI tools went viral for mishandling the spelling query “how many r’s are in the word strawberry?” and the problem has not gone away. This week, X user Naomi Rohatyn asked, “How many e’s in the word astronomical?” and AI Overview replied, “There are exactly 2 ‘e’s in the word ‘astronomical’ (a-s-t-r-e-n-o-m-i-c-a-e-l).” The answer is wrong on both the letter count and the spelling. According to Mashable, the same failure appears with many four-syllable words, suggesting a pattern rather than a one-off glitch. For users, such errors make Google search quality feel unstable and experimental.
Why Large Language Models Struggle With Letters
The misspellings are not because Google’s models have never ‘seen’ the right word; they arise from how large language models process text. LLMs like Gemini read and generate language as tokens—chunks that often correspond to whole words or parts of words—rather than as sequences of individual letters. When asked to count letters or spell out a word step by step, the model is forced into a task that does not match its internal representation. Mashable’s reporter asked Gemini to explain, and it responded that it views “apple” as a single token, not five separate letters, and therefore does not naturally “spell” in a human sense. This mismatch leads to confident but flawed outputs such as “a-s-t-r-e-n-o-m-i-c-a-e-l.” The episode highlights a key LLM accuracy issue: models can sound fluent while failing at structured, low-level tasks users assume are trivial.
Trust, Clicks, and the Stakes for Google Search Quality
Spelling mistakes might seem harmless, but they carry real product risks for Google. AI Overviews appear above traditional links, and Mashable points out that users are less likely to click through when an AI summary is present. That means the summary’s reliability shapes both user understanding and traffic sent to publishers. When that summary includes obvious errors, users may doubt not only the AI Overview but the surrounding results and Google search quality overall. The pattern of Google AI Overview errors—hallucinated facts, then recurring misspellings—suggests gaps in quality assurance and guardrails for production-grade AI. If Google cannot consistently catch misspelled common words in its flagship search experience, it raises harder questions: how thoroughly are answers in sensitive areas being checked, and what happens when mistakes are subtle enough that users cannot spot them?
What These Errors Reveal About LLMs in Production
The “astronomical” incident is a small failure with large implications. It shows that even as AI Overviews “improved its accuracy dramatically” since launch, core limitations of LLMs remain. Models trained for pattern-based language prediction are being asked to behave like precise reference tools, but they lack deterministic control over details such as spelling and counting. At scale, that gap becomes a product issue, not an edge case. For Google, the challenge is to match the speed of AI deployment with stronger quality checks, evaluation focused on letter-level and fact-level tasks, and clear signals when an answer may be unreliable. For users, the lesson is that AI search reliability is uneven: fluent summaries can still contain basic errors. Until the underlying systems and safeguards change, AI Overviews will keep exposing how fragile language models can be once they leave the lab.





