
AI Vulnerability Detection Moves From Experiment to Infrastructure
AI vulnerability detection is the use of large language models and related AI systems to autonomously analyze code and infrastructure, identify software security flaws, and in some cases generate working exploit proofs that help teams prioritize and fix the most dangerous issues before attackers can abuse them. Anthropic’s Project Glasswing, powered by the Claude Mythos Preview model, shows how quickly this is moving from pilot projects into core security infrastructure. About 50 partners have already used Mythos to uncover more than 10,000 high- or critical-severity vulnerabilities in software that underpins cloud platforms, browsers, and other critical services. This turns AI from a theoretical risk into a practical defensive tool. At the same time, the scale of findings means discovery is no longer the scarcest resource in open-source security; the real challenge is validating, disclosing, and patching what the AI uncovers.

Inside Project Glasswing’s 10,000+ Discovered Flaws
Project Glasswing gives select organizations early access to Claude Mythos Preview to scan both proprietary and open-source software. Anthropic reports that partners have found hundreds of serious vulnerabilities each, with some seeing more than a tenfold increase in bug discovery rates compared with earlier models. In its open-source security campaign, Mythos scanned over 1,000 projects and flagged 23,019 potential issues, including 6,202 high- or critical-severity flaws. Subsequent human analysis confirmed 1,726 of these as valid vulnerabilities, with 1,094 rated high or critical. One standout case is a WolfSSL certificate forgery bug, tracked as CVE-2026-5194 with a CVSS score of 9.1, which could let attackers pose as trusted services. According to Anthropic, “the relative ease of finding vulnerabilities compared with the difficulty of fixing them amounts to a major challenge for cybersecurity.”

Strengths: From Bug Candidates to Exploit Chains at Scale
What sets Mythos apart from traditional scanners is not only how many software security flaws it finds, but how deeply it reasons about them. When Cloudflare ran Mythos on more than fifty internal repositories, the model surfaced around 2,000 bugs, including 400 high- or critical-severity problems in critical-path systems. Mythos can construct exploit chains by linking low-severity issues into a practical, higher-impact attack path. It can also generate and iterate on proof-of-concept code in a controlled environment, compiling and running exploits to confirm that a suspected flaw is genuinely exploitable. This behavior looks less like a noisy static analysis engine and more like the methodical work of an experienced security researcher. For partners, that means fewer hypothetical problems and more actionable critical vulnerabilities that can be prioritized in patch sprints and integrated into ongoing defensive programs.
Limits: Guardrails, False Positives, and Human Bottlenecks
Project Glasswing also highlights clear limits in AI-driven security scanning. Even in a less restricted configuration, Mythos Preview shows inconsistent “organic” refusals: it might decline to build a demonstration exploit in one run, then agree if the request is phrased differently or the environment changes, even when the code is identical. This inconsistency makes it hard to rely on AI safety guardrails alone when doing legitimate security work. The numbers also show a sizeable gap between candidates and confirmed issues: of 6,202 high- or critical-severity flags in open-source projects, only 1,094 were validated at that severity after review. That is a large volume of triage work. The true bottleneck shifts from finding bugs to human analysis, coordinated disclosure with maintainers, and timed patch releases, as seen in the 97 upstream fixes and 88 advisories so far.
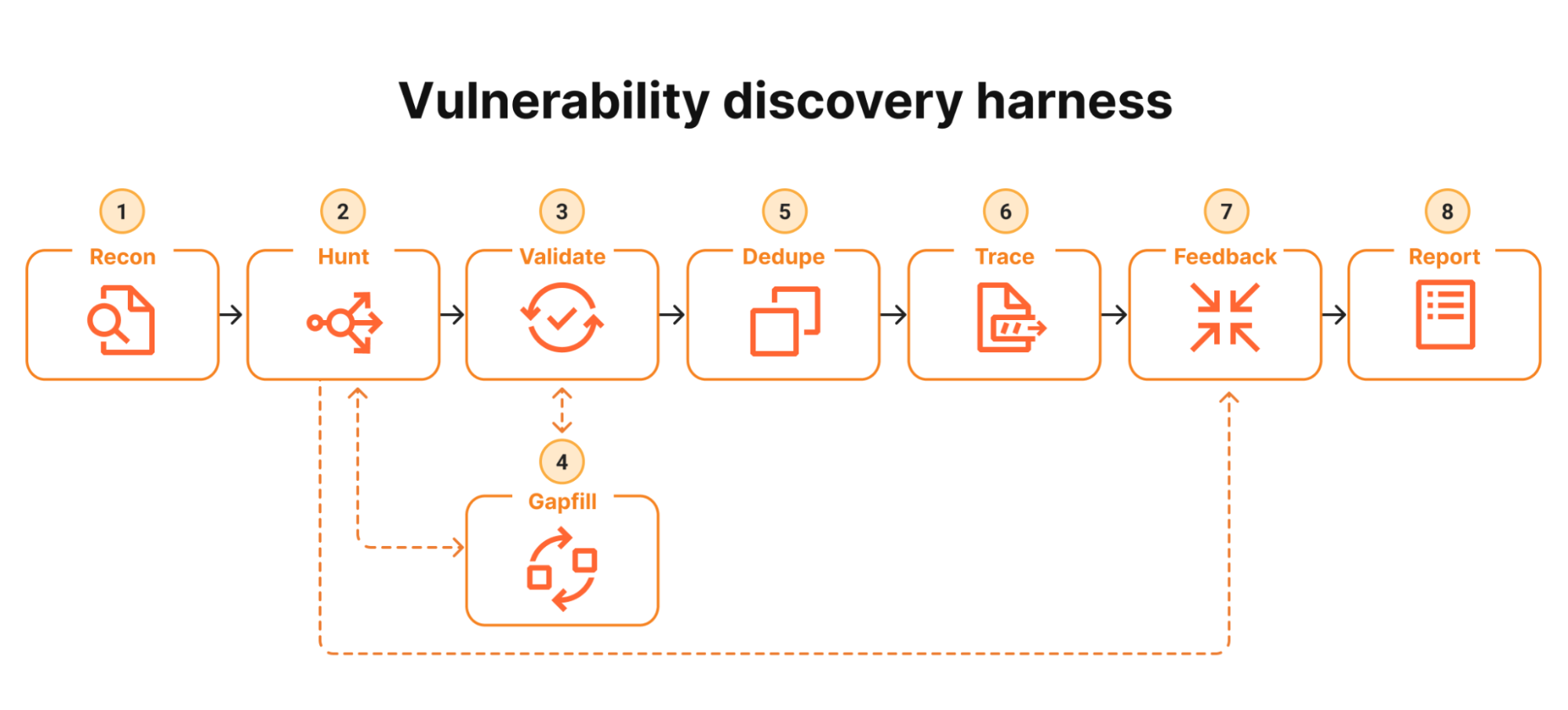
What Comes Next for Open-Source Security and Mythos
The Glasswing experience suggests AI vulnerability detection will become a constant background process for critical open-source security projects rather than an occasional audit. As Mythos and similar security-focused LLMs mature, they are likely to be integrated more tightly into developer workflows and coding assistants. Anthropic’s broader Claude family already includes code-focused capabilities, and Mythos appears to be evolving toward deeper Claude Code integration that could bring exploit reasoning and patch suggestions directly into IDEs and CI pipelines. That could shorten the feedback loop from discovery to fix, which is now the main pain point for partners racing to patch high-impact findings. For security teams, the lesson is clear: AI will not replace human experts, but it is changing their job from hunting for a few rare bugs to managing a continuous stream of serious vulnerabilities across live infrastructure.





