
What DiffusionGemma Is and Why It’s So Fast
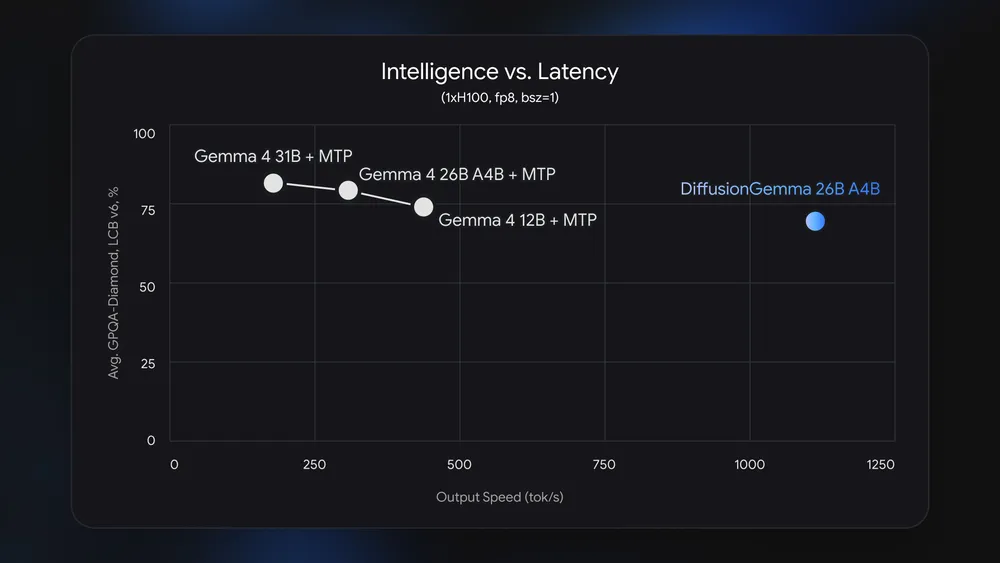
DiffusionGemma is an experimental 26B-parameter text diffusion model that uses a parallel diffusion architecture for on-device text generation, trading some benchmark performance for much faster local GPU inference in latency-sensitive scenarios. Instead of writing tokens one by one like a standard autoregressive large language model, it lays out a noisy block of text and then refines the entire block over multiple denoising steps. In each step, DiffusionGemma updates 256 tokens in parallel, which turns the generation process into a compute-heavy workload rather than a memory-bandwidth-bound one. This is why it can use modern GPUs more efficiently for model speed optimization. Google reports that DiffusionGemma can reach more than 1,000 tokens per second on a single Nvidia H100 and over 700 tokens per second on an RTX 5090, delivering up to 4x faster throughput than standard Gemma models in low-concurrency on-device settings.
How Parallel Text Diffusion Changes Local GPU Inference
Most large language models generate text left-to-right, committing each token before predicting the next. That pattern limits parallelism and makes local GPU inference depend heavily on memory bandwidth. DiffusionGemma replaces this with a diffusion architecture borrowed from image generators like Stable Diffusion. It starts with a full canvas of random tokens, then repeatedly denoises the sequence until it converges on coherent text. All tokens attend to each other at every step, which is well-suited to GPUs that have ample compute but limited bandwidth. Because the workload is compute-bound, consumer cards can keep their cores busy instead of waiting on memory transfers. According to Google’s DeepMind team, this design enables over 1,000 tokens per second on an H100 in single-request scenarios, and NVIDIA’s measurements suggest similar gains on RTX and DGX platforms, with DGX-class systems hitting around 150 tokens per second per stream in multi-user environments.

The Quality Trade-Off Versus Standard Gemma 4
The speed comes at a cost: DiffusionGemma underperforms Gemma 4 26B A4B on standard language benchmarks. Google is clear that the model is an experimental path for on-device text generation, not a drop-in replacement when output quality is the top priority. The mixture-of-experts design activates only about 3.8B of its 26B parameters during inference, helping it run in 18GB of VRAM but also narrowing the capacity used per step. For tasks that depend on fine-grained reasoning, subtle stylistic control, or long-form consistency, the traditional autoregressive Gemma 4 remains the safer option. DiffusionGemma focuses on model speed optimization and low latency, so you should expect more occasional artifacts, less polished phrasing, and weaker performance on demanding benchmarks. In short, treat it as a performance-oriented tool: excellent when timing dominates, second-best when absolute quality and reliability matter most.

Best-Fit Use Cases: Where Latency Beats Perfection
DiffusionGemma’s design shines in workflows where latency trade-offs favor speed over maximum quality. The model updates all tokens together, so it fits code infilling and inline editing: cases where the system must rewrite or extend an existing span in one go, then let the user quickly assess and tweak the result. Google highlights code assistants, developer tools, and document editors as target scenarios, along with more structured domains like amino acid sequences and mathematical graphs, where global attention across a block of tokens helps maintain structure. In these settings, generating usable output in tens of milliseconds is often more valuable than squeezing out a few extra benchmark points. For background drafting, rapid prototyping, or interactive UI features that need snappy on-device text generation, the 4x speed boost can outweigh the loss in polish, especially on consumer RTX GPUs or DGX Spark systems serving many short requests.

A New Path for On-Device AI Beyond Compression
DiffusionGemma signals a shift in how vendors think about on-device AI optimization. Until now, most efforts to speed up local GPU inference focused on model compression techniques such as quantization, pruning, or smaller parameter counts. DiffusionGemma keeps a large open-weights model but changes the generation algorithm itself, turning sequential prediction into parallel refinement. This opens a second axis for model speed optimization: not only how big the model is, but how it computes its outputs. Crucially, the diffusion architecture exploits the excess compute in modern GPUs without demanding huge memory bandwidth, which is exactly where many consumer and workstation cards have headroom. For teams building latency-sensitive tools—code editors, design apps, local copilots—DiffusionGemma suggests a future where multiple specialized generation schemes coexist, each tuned for different latency trade-offs rather than a single “best” text model design.





