Padding Overhead: Why Your GPU Is Multiplying Zeros
Hardware-aware sequence packing for LLM inference is the practice of rearranging variable-length token sequences so they fit GPU-friendly layouts that minimize padding, align with tensor-core tile sizes, and keep both compute units and memory bandwidth busy instead of wasting cycles on padded zeros. Traditional batching keeps tensors rectangular by padding every sequence in a batch to the maximum length, so an 80‑token prompt and a 2000‑token prompt both become 2000 tokens. The GPU then spends a large fraction of its time performing multiplications and memory transfers on those padded tokens, which is equivalent to paying for empty work. In many production settings this padding overhead dominates, turning high-end GPUs into devices that burn energy and wall-clock time without affecting model outputs. LLM inference optimization therefore starts with a blunt question: how much of each forward pass is real computation, and how much is avoidable padding waste?
From Ragged Text to Packed Ribbons: The Core Idea
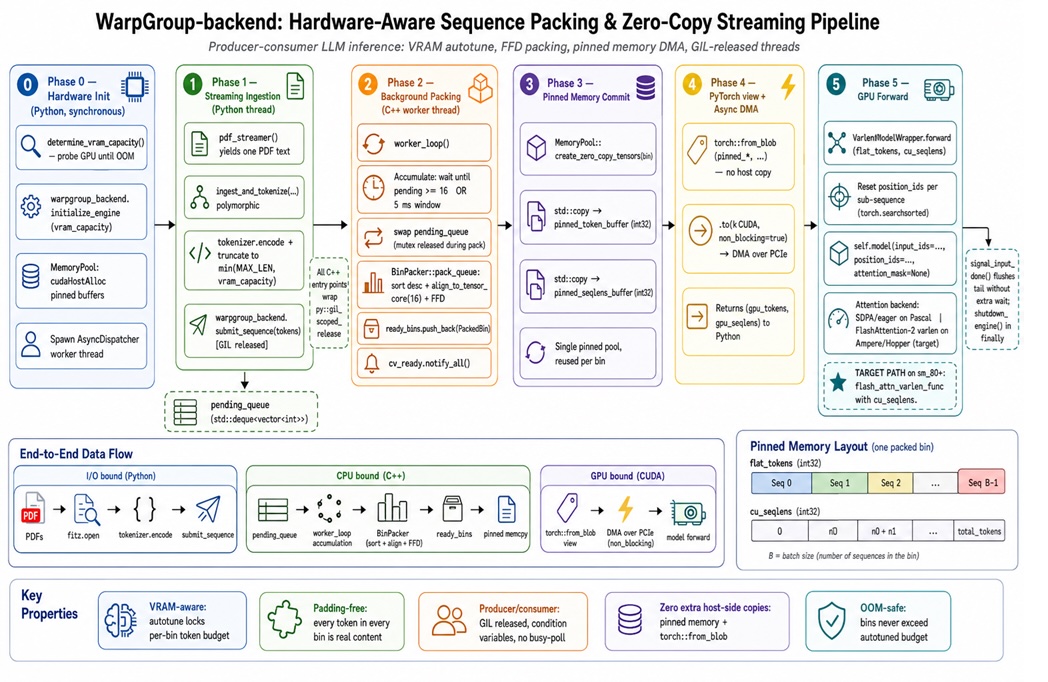
Instead of padding every sequence to the longest one, modern GPU sequence packing treats all prompts as slices of a single long ribbon. Variable-length attention kernels, such as FlashAttention’s varlen interfaces, only allow tokens from the same sequence to interact, but they no longer require rectangular inputs. The packing problem moves to the host: we must decide which sequences share a ribbon, in what order, and up to what total token budget. A classic bin-packing strategy like First-Fit Decreasing sorts sequences by length, then drops each into the first bin that has room. This yields near-optimal packing in O(n log n) time and slashes padding overhead. According to the WarpGroup-Backend write-up, replacing naive padding with packed ribbons delivered up to 2.08× throughput on an H100 and 5.89× on a GTX 1080.
Making Packing Hardware-Aware: VRAM Limits and 16-Token Alignment
Hardware-aware optimization adds GPU-specific constraints to bin packing. First, the effective bin size is not a static number; usable VRAM depends on model size, KV-cache growth, allocator fragmentation, and runtime quirks. A practical approach is to probe capacity at startup: repeatedly attempt larger total token counts until the device runs out of memory, then back off with a safety margin. This empirical step anchors LLM inference optimization in the reality of the deployed system. Second, tensor cores favor sequence-related dimensions that are multiples of 16 (or 8, depending on datatype and architecture). Rounding sequence lengths up to these tile boundaries slightly reintroduces padding, but it improves memory coalescing and GEMM shapes downstream. Aligning bins to these friendly sizes means the GPU spends more time in its fastest kernels and less time in awkward edge cases where warps and memory transactions are underutilized.
Why a C++ Backend Beats Python in the Hot Path
Packing sequences efficiently is a streaming systems problem, not just an algorithm choice. Python’s global interpreter lock means tokenization, queuing, packing, and GPU feeding contend for the same interpreter thread, turning what should be a producer–consumer pipeline into a serialized queue. Moving the core packing logic into a C++ backend changes this picture. The Python side tokenizes and hands integer sequences across a language boundary, where a C++ dispatcher maintains a thread-safe queue, sorts and packs bins, and manages pinned-memory buffers for asynchronous DMA transfers. Crucially, the C++ code releases the Python GIL, so tokenization and packing can run in parallel. This design keeps GPUs fed without stalls and avoids out-of-memory crashes by respecting measured VRAM limits. In cumulative effect, smarter packing, alignment, and concurrency yield substantial throughput gains across large inference workloads.





