What Claude Opus 4.8’s Effort Selector Does
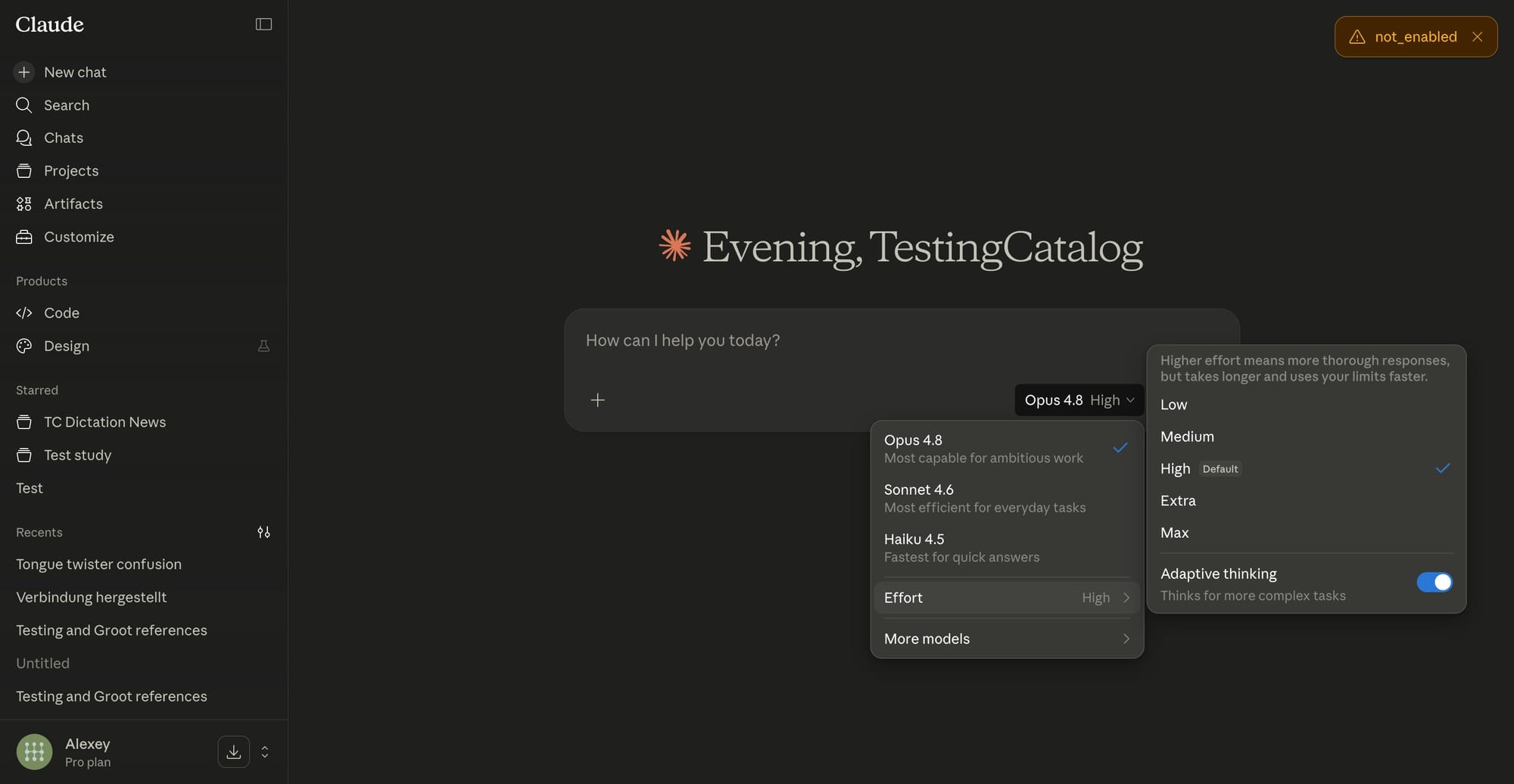
Claude Opus 4.8’s effort selector API is a control that lets developers choose how intensively the model reasons about a task, trading response speed and cost against depth and accuracy in a consistent, configurable way. Instead of a single fixed behavior, Opus 4.8 exposes multiple effort levels so you can align the model’s work style with your application’s needs. At a high level, lower effort prioritizes fast mode performance and cheaper runs, while higher effort spends more compute on multi-step reasoning, self-checking, and error detection. Anthropic reports that Opus 4.8 is much less likely to miss coding issues and is better at pointing out possible mistakes in its own work, which means effort settings are not only about latency but also about AI coding reliability and how much safety margin you want for critical workflows.
Fast Mode: When Speed and Cost Matter Most
Fast mode in Claude Opus 4.8 is designed for high-throughput tasks where approximate answers are acceptable and latency is the main constraint. According to Anthropic, “fast mode now delivers responses at 2.5 times the previous speed at a third of the former cost,” making it a strong default for tasks like quick Q&A, UI assistants, and non-critical log or document summarization. With the effort selector API, you can route easy, repetitive calls to fast mode while reserving deeper modes for harder problems. This mode still benefits from Opus 4.8’s improved judgment but does less internal checking, so it suits scenarios where humans are already reviewing outputs: draft generation, brainstorming, early-stage code scaffolding, or bulk text processing pipelines that will be filtered or validated downstream.
Higher Effort: Accuracy, Reliability, and Self-Checks
Higher effort levels in Claude Opus 4.8 tell the model to spend more time reasoning, exploring alternatives, and self-checking its own work before responding. Anthropic notes that Opus 4.8 is around four times less likely than its predecessor to leave coding issues unmentioned, and early users have reported that it performs more rigorous self-checks and improves AI coding reliability in agentic and legal applications. Use higher effort for code that will run in production, complex refactors, security-sensitive changes, or any domain where hidden mistakes are costly. These settings are also useful for multi-step reasoning tasks such as chain-of-thought planning, policy interpretation, or subtle data analysis. You pay with higher latency and resource usage, but you gain a more careful model that is better at identifying flaws, flagging uncertainty, and reducing unreported errors.
Effort Control, Dynamic Workflows, and Parallel Workloads
Effort control becomes even more powerful when combined with Claude Opus 4.8’s dynamic workflows and parallel processing patterns. For coding in Claude Code, Anthropic explains that “Claude can plan the work and then run hundreds of parallel subagents in a single session,” and with Opus 4.8 those agents can run for longer and verify their outputs before returning results. In practice, you can design a system where low-effort agents rapidly explore options or generate drafts, while higher-effort passes validate, de-duplicate, and correct the most promising outputs. This pattern suits large codebases, broad test generation, or wide document reviews. The effort selector API lets you tune each stage of the workflow separately, so you can use fast mode performance for breadth and high effort for depth without rewriting your overall pipeline.
Designing an Effort Strategy for Your Stack
To get the most from Claude Opus 4.8, treat effort selection as an application-level policy, not a one-off toggle. Start by classifying your calls by risk and time sensitivity: non-critical or user-facing chat replies can default to fast mode, while critical functions like code migration, compliance checks, and legal drafting use higher effort. Next, define routing rules in your backend so the effort selector API is driven by metadata such as task type, user role, or project stage. You can also adopt a two-pass pattern: generate in fast mode, then re-check or finalize in higher effort for a subset of cases, such as high-impact code changes or ambiguous model answers. Over time, log latency, error rates, and review effort so you can rebalance speed accuracy tradeoffs as your workloads and tolerance for risk evolve.




