What RTX Spark Is and Why 2x Local AI Matters
RTX Spark is NVIDIA’s new Windows PC platform that combines a Blackwell-based RTX GPU, up to 1 petaflop of AI compute, and 128GB of unified memory to run powerful local AI agents with minimal dependence on the cloud. Instead of sending prompts to remote servers, RTX Spark runs models directly on RTX hardware, turning laptops and compact desktops into personal AI computers. The headline claim is a 2x boost in local AI inference performance for leading agentic models in llama.cpp and vLLM, driven by features like multi-token prediction and programmatic dependent launch. According to NVIDIA, these optimizations double throughput on Qwen 3.6 and 3.5 27B and lift 35B models by 1.6x on GeForce RTX 5090, which means snappier chatbots, faster code assistants, and more responsive RTX PC agents that keep your data on your own machine.
OpenShell: Secure Local AI Agents on Windows
NVIDIA OpenShell for Windows supplies the missing runtime layer that lets AI agents act on your behalf without giving up control. Built on new Windows security primitives, it adds identity, containment, and policy controls so agents can run under strict permissions and clear boundaries. Users can decide what an agent may access, which apps it can control, and which actions are off limits. OpenShell can route prompts to local models when privacy is vital, and disguise personal information when a task needs a cloud model. Hermes Agent and OpenClaw are already integrating this stack, enabling secure RTX PC agents that can automate Office workflows, coordinate cross-app tasks, and search local files semantically. Paired with RTX Spark, OpenShell makes NVIDIA OpenShell Windows deployments a default path for developers who want local AI inference performance without sacrificing security or user trust.
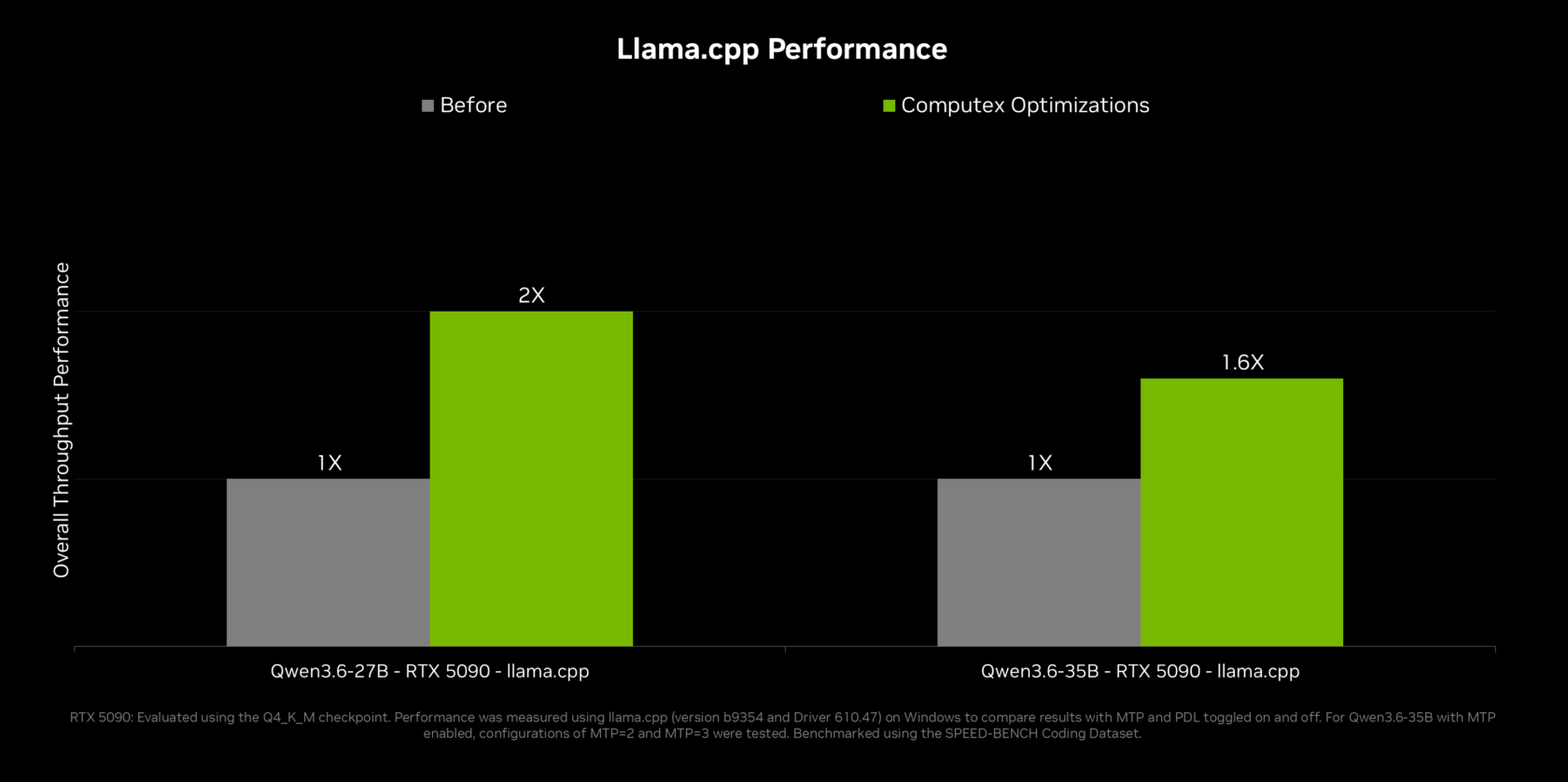
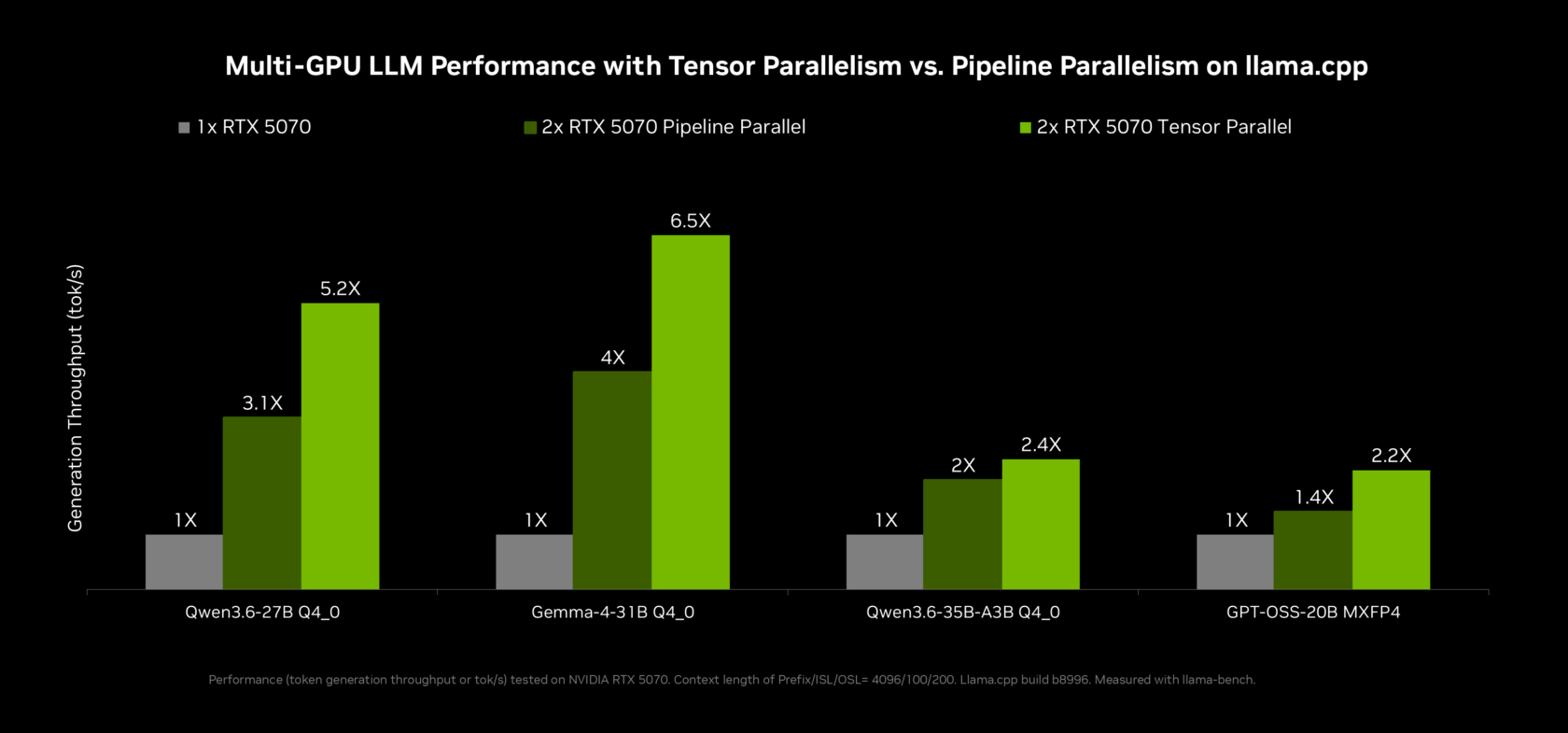
Llama.cpp Acceleration and Multi-GPU Gains
RTX Spark is as much about software as hardware, and llama.cpp acceleration is central to the story. NVIDIA has worked with the llama.cpp community to add multi-token prediction, where a smaller draft model proposes several tokens at once for the main model to verify in one pass, cutting decoding time. Programmatic dependent launch and other kernel-level tricks further shrink latency. For power users with multi-GPU rigs, tensor parallelism in llama.cpp delivers up to 2x effective memory and 1.8x compute scaling across two equivalent GPUs, making larger models practical on consumer systems. ComfyUI gains a new classifier-free guidance method and the option to split model chains across GPUs, again improving local AI inference performance. Together, these upgrades push llama.cpp acceleration from hobbyist-tier experiments toward serious, responsive RTX PC agents that can handle complex reasoning, content generation, and creative pipelines locally.
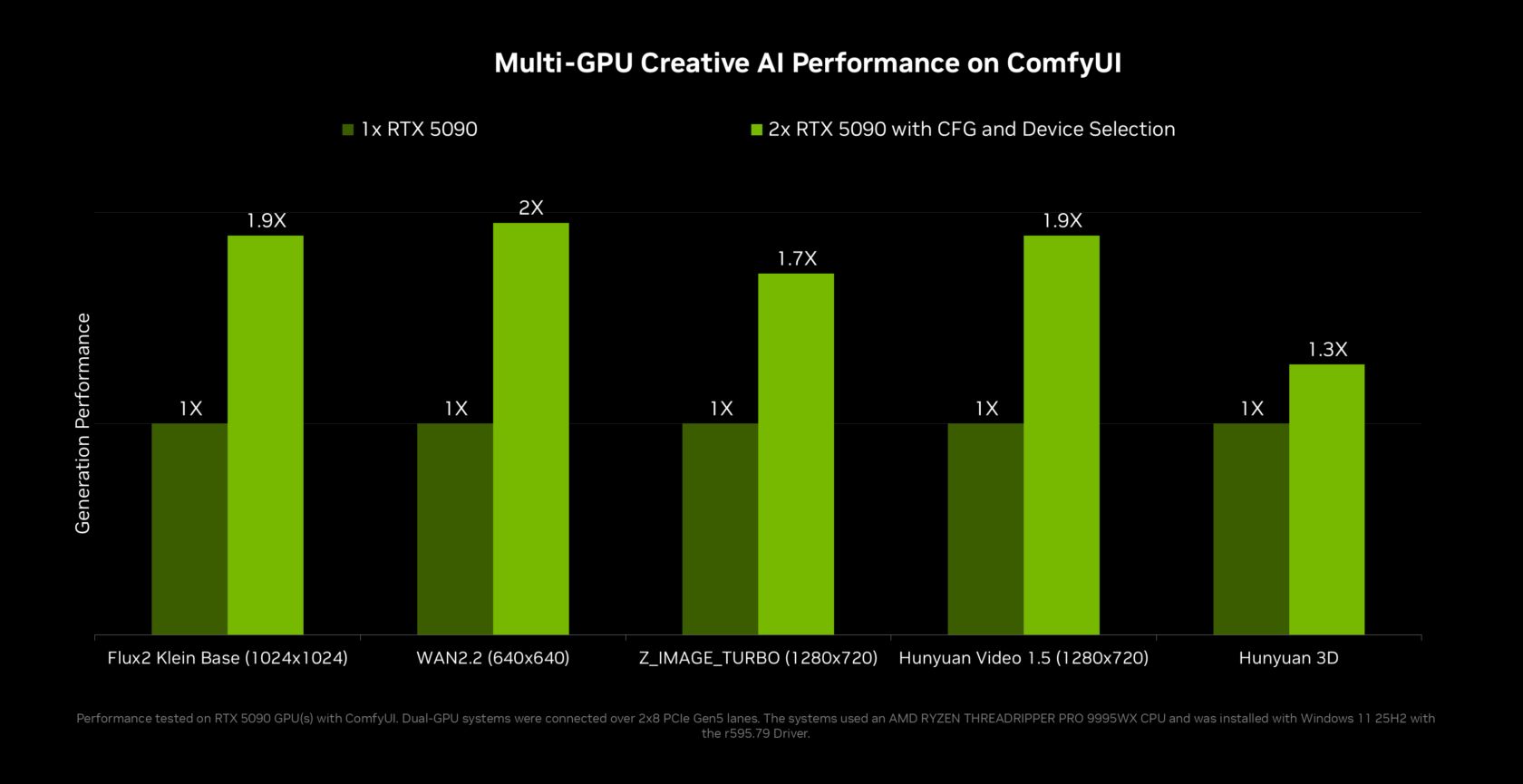
Adobe, Creators, and the Shift to Local AI Workflows
RTX Spark is arriving alongside a wider app refresh that assumes AI is local by default. Adobe is rearchitecting Photoshop and Premiere to integrate RTX Spark, combining the platform’s 128GB unified memory and petaflop-class compute with new performance and memory optimizations in their creative tools. That means AI-assisted editing, frame interpolation, and generative features can run on-device, reducing round trips to cloud services and smoothing timelines for editors working with large assets. Blender is adding DLSS 4.5 Ray Reconstruction, while NVIDIA’s RTX Video Frame Generation and Broadcast updates round out a creative stack built around RTX Spark local AI. For creators, this translates to fewer waiting spinners and more responsive tools; for enterprises, it offers a path to deploy RTX PC agents in workflows where latency, bandwidth limits, or confidentiality make cloud-only AI a bad fit.
ARM-Class Efficiency and the Future of Personal AI PCs
RTX Spark systems are designed as thin laptops with all-day battery life and efficient desktop PCs, bringing an ARM-like efficiency profile—similar to what users expect from Apple Silicon—to the Windows ecosystem. By integrating CPU, GPU, and AI accelerators in a single superchip and pairing them with NVIDIA’s CUDA, RTX, and AI stack, these PCs can sustain local AI workloads without constant fan noise or charger dependence. Local AI inference performance gains mean that everyday tasks, from language assistants to RTX PC agents that drive automation, can run offline and avoid cloud latency. Privacy benefits follow: sensitive documents, code, or media stay on-device, even when models are large. As OEMs like ASUS, Dell, HP, Lenovo, Microsoft Surface, and MSI prepare RTX Spark hardware, the line between desktop-class AI rigs and travel-ready laptops blurs, hinting at a future where personal AI runs wherever your main PC goes.





