A Cheaper Contender in the AI Coding Assistant Line-Up
Cursor’s new Composer 2.5 is positioned as a cost‑efficient AI coding assistant, designed for developers who live inside repositories rather than chat windows. The model powers Cursor’s agent-style workflows for writing, editing, and debugging code across multiple files, with a clear emphasis on longer coding jobs and complex instruction chains. Pricing stays aggressive: the standard tier is set at USD 0.50 (approx. RM2.30) per million input tokens and USD 2.50 (approx. RM11.50) per million output tokens, while the faster default tier comes in at USD 3.00 (approx. RM13.80) per million input tokens and USD 15.00 (approx. RM69.00) per million output tokens. Cursor argues that, when combined with higher throughput on difficult tasks, this translates to up to 10x cost efficiency versus earlier models and rival AI development tools, setting up a direct price-performance showdown against premium systems like Claude and GPT.

Kimi K2.5, 25x Synthetic Training, and Targeted RL
Rather than swapping to a new foundation model, Cursor keeps Moonshot’s Kimi K2.5 as the base and instead leans heavily on post‑training to unlock gains. Composer 2.5 was trained on 25 times more synthetic tasks than its predecessor, feeding the model a larger stream of simulated coding workloads before it ever touches a real repository. On top of this, Cursor adds tougher reinforcement-learning environments and targeted textual feedback: short, localized hints are inserted at the exact points in long task rollouts where the model could have done better. This approach aims to tackle the classic RL “credit assignment” problem in long-running coding sessions, while improved behavioral calibration focuses on communication style, effort level, and coding consistency. In theory, developers get an AI coding assistant that plans further, uses tools more reliably, and follows nuanced instructions without paying for a more expensive base model.
Cost Efficiency Benchmarks: Composer 2.5 vs Claude and GPT
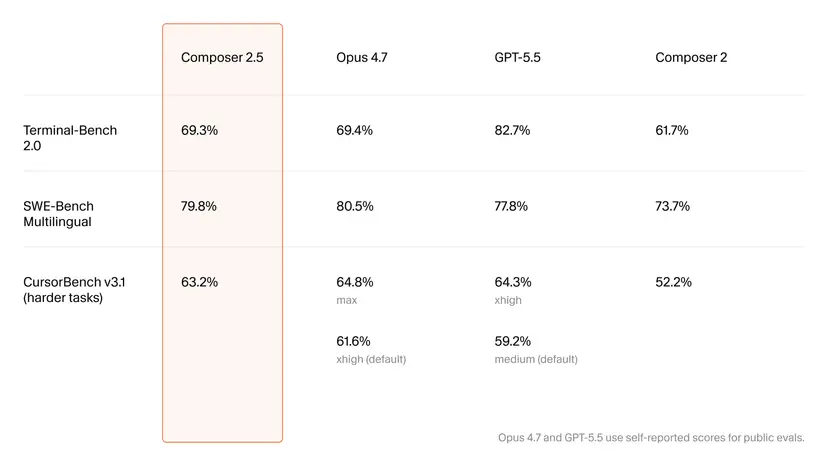
On headline coding benchmarks, Composer 2.5 narrows the gap with top-tier models like Anthropic’s Claude Opus 4.7 and OpenAI’s GPT‑5.5 while undercutting them on AI coding assistant pricing. Cursor reports that Composer 2.5 improved its Terminal-Bench 2.0 score from 61.7% to 69.3%, and its in-house CursorBench v3.1 from 52.2% to 63.2%, marking meaningful gains in code-generation accuracy and agent-style task completion. On SWE-Bench Multilingual, it posts a 79.8% score and even edges past GPT‑5.5 by 2%, though it still trails Opus 4.7 and GPT‑5.5 on several other metrics. When these benchmark jumps are paired with the lower token prices, Cursor claims up to 10x cost efficiency in real workloads. For teams comparing Claude vs GPT vs Cursor, the trade-off becomes clear: slightly lower peak benchmark scores in exchange for significantly cheaper, more frequent usage during everyday development.
Behavioral Calibration and Long-Running Agent Work
Composer 2.5’s most strategic bet is on long-running, multi-step coding sessions—precisely where many AI development tools still stumble. Cursor says targeted reinforcement learning with localized feedback helps the model keep track of plan, context, and tooling over extended trajectories. Behavioral calibration layers on top of this, tuning communication style and effort so the assistant writes clearer explanations, maintains coding conventions, and avoids over- or under-editing large files. Internal tests and early user feedback suggest the model is better at sustained coding tasks and more accurate with tool calls than previous Composer versions. However, comments from early adopters indicate rough edges remain: some report that the agent occasionally slips out of “agent mode” mid-task or loses its place when resuming after interruptions. That underscores how difficult it is to turn benchmarked planning ability into a smooth, uninterrupted coding workflow in real projects.
Real-World Adoption: What Developers Should Test Next
Despite promising cost efficiency benchmarks and aggressive pricing, the decisive question for Composer 2.5 is practical adoption. Benchmarks like Terminal-Bench, SWE-Bench Multilingual, and CursorBench v3.1 measure correctness and completion on curated tasks, but practitioners repeatedly stress that intelligence scores do not automatically translate into productivity. Developers evaluating Cursor against Claude and GPT will want to run live tests on their own repositories: multi-file refactors, framework upgrades, and long-lived branches where consistency and context retention matter more than one-off snippets. Key buying criteria remain architecture, multi-file accuracy, response speed, and cost predictability. Composer 2.5’s ability to perform sustained, repository-scale edits at a lower per-token cost could be compelling if it reliably maintains style and avoids regressions. Until independent, real-world coding performance tests accumulate, Composer 2.5 looks like a high-upside, low-cost bet—but still a bet—for teams choosing their next AI coding assistant.