
From Handy Script Writer to Methodological Partner
AI code generation has moved from novelty to daily reality for many students, analysts, and data scientists. Tools like ChatGPT now draft Python functions, translate scripts between R and Stata, and help debug opaque error messages. Yet there is a crucial leap between automating a helper function and implementing a full causal inference workflow. Quantitative researchers increasingly ask whether ChatGPT can handle Difference-in-Differences, Inverse Probability Treatment Weighting, or Regression Discontinuity, and do so consistently across Python, R, and Stata. A recent study by Winberg and co-authors, based on examples from the textbook Causal Inference: The Mixtape, reframes the question: not “can AI write code?” but “can we trust the code it writes for serious research?” Their work, combined with emerging AI reliability testing frameworks, signals a shift toward treating AI as a sophisticated but fallible collaborator that must be checked, not blindly obeyed.
Inside the ChatGPT Causal Inference Benchmark
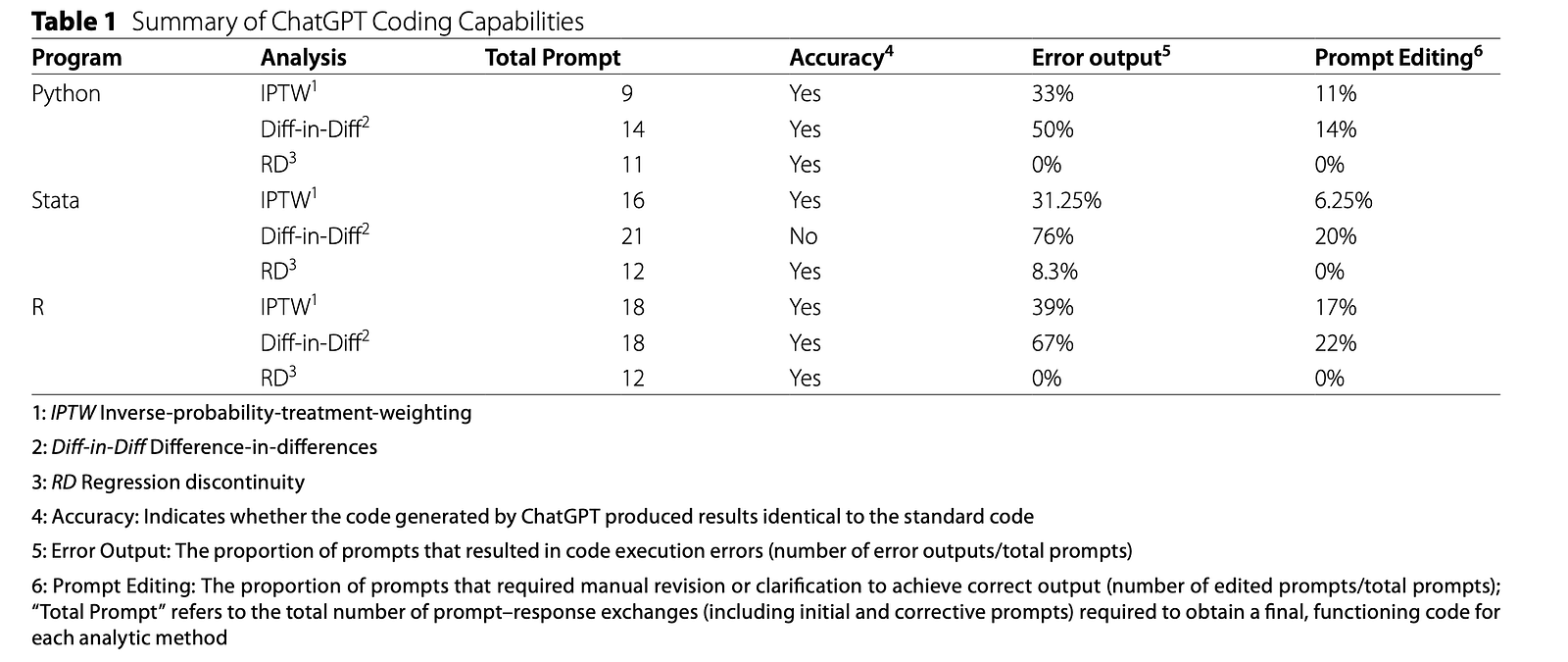
Winberg and colleagues evaluated ChatGPT-4.0 Pro on realistic econometric problem sets rather than toy examples. Using publicly available data and reference solutions from Causal Inference: The Mixtape, they asked ChatGPT to implement Difference-in-Differences, IPTW, and Regression Discontinuity in Python, R, and Stata. Importantly, they compared not just whether the code ‘looked right’ but whether it reproduced benchmark outputs when executed in R 3.6.0, Stata 18, and Python 3.13. The prompts went beyond single model calls, asking for dynamic treatment effects, data preparation, figure generation, and complete workflows. Four experienced econometricians crafted and refined these prompts, mirroring how real researchers iterate with AI: request code, run it, handle errors, and ask for fixes. This structured, multi-language design exposes both the promise and gaps of ChatGPT coding accuracy in demanding, method-heavy tasks.
What Mixed Results Mean for ChatGPT Coding Accuracy
The study’s design highlights that AI code generation can be impressively helpful yet far from infallible. ChatGPT often produced syntactically valid scripts and could approximate standard causal workflows, especially when prompts were precise and iterative feedback was provided. However, correctness in appearance did not always translate into correct econometric implementation or benchmark-matching numerical results. Subtle issues in model specification, data handling, or interaction terms could lead to analyses that run without errors but misrepresent the intended design. Including Stata underscored that performance can vary by language and ecosystem. For developers and applied researchers, the lesson is clear: ChatGPT coding accuracy is good enough to accelerate routine coding and exploratory work, but not yet reliable enough to bypass domain expertise, replication against reference code, or systematic output checks when methodological nuance truly matters.
A Control Method for AI Reliability Testing
Parallel to these coding benchmarks, new control methods aim to make AI outputs more trustworthy before they ever go live in critical systems. Master’s student Panagiotis Kalogeropoulos, working with lecturer–researcher Herman Jurjus, developed a framework that acts as a double safety check for AI-generated instructions. In their approach, an AI first produces code from a human prompt; this code is then evaluated by the system itself, which generates a risk assessment from multiple stakeholder perspectives. Only after human review of that assessment is the code approved or rejected for use. Presented at a NASA Formal Methods workshop, this method targets high‑risk domains such as self-driving systems or medical equipment, where organizations want the benefits of generative AI without surrendering control to a “black box.” It exemplifies structured AI reliability testing designed to surface hidden dangers before deployment.
Toward Practical Automated Code Verification
Together, the causal inference benchmark and the control framework point toward a pragmatic future for AI-assisted development. For research software, AI code generation is most trustworthy when its outputs can be compared against known reference implementations, reproduced across languages, or validated with test datasets and expected results. Automated code verification pipelines that execute AI-generated scripts, compare key statistics to benchmarks, and flag discrepancies can turn subjective code review into an objective check. In higher-risk environments, layered safeguards—self-assessment by AI, multi-model panels, and human sign‑off—provide additional control. Developers should treat AI as an accelerator, not an autopilot: use it to draft and refactor, then lean on testing frameworks to decide when its contributions are safe to accept and when manual inspection, methodological expertise, or traditional formal verification remains absolutely essential.