
A Speed-Focused Model That No Longer Trades Quality for Latency
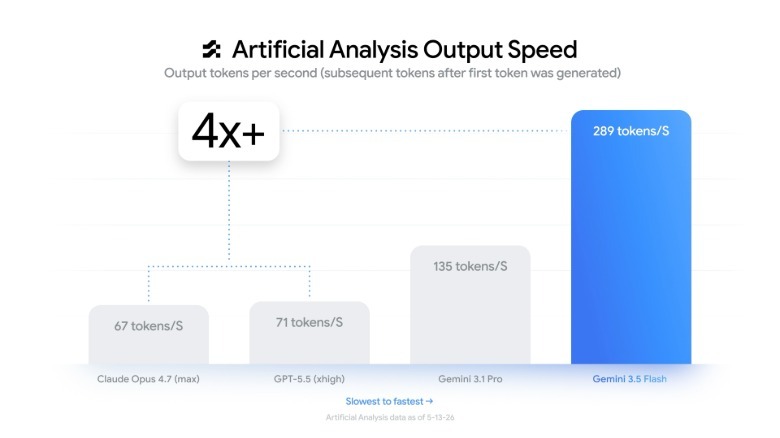
Gemini 3.5 Flash is Google’s latest speed-optimized AI model, unveiled at Google I/O and already rolling out as the default in the Gemini app and AI Mode in Search. Google positions it as a breakthrough in the “speed versus quality” tradeoff: Gemini 3.5 Flash reportedly runs four times faster than comparable frontier models in output tokens per second while delivering frontier-level intelligence. It even surpasses the earlier Gemini 3.1 Pro on key coding and agentic benchmarks, despite being the lighter, faster tier in the Gemini lineup. That balance of performance and latency is what makes Gemini 3.5 Flash stand out. Instead of being merely a quick answer engine, it is engineered as a flagship model alternative that can keep up with demanding workloads, yet respond quickly enough to power real-time applications and interactive tools that users expect to feel instantaneous.
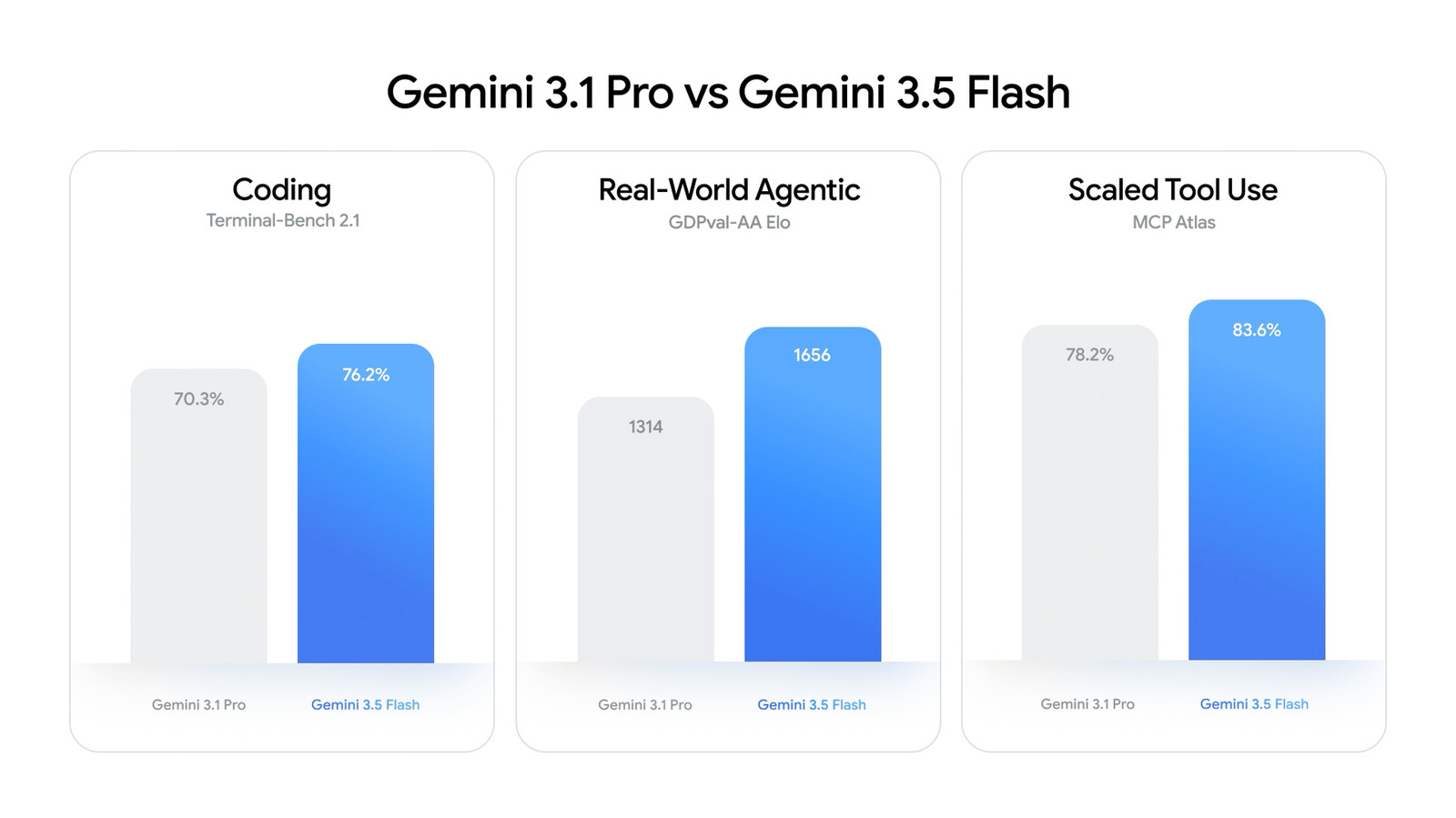
Coding Powerhouse: How Gemini 3.5 Flash Targets Developers
For developers, Gemini 3.5 Flash is positioned as Google’s strongest AI model for code generation, refactoring, and tool use so far. Google reports that it outperforms Gemini 3.1 Pro on challenging coding benchmarks such as Terminal-Bench 2.1, scoring 76.2 percent, and MCP Atlas scaled tool use, where it reaches 83.6 percent. It also posts 84.2 percent on CharXiv Reasoning, highlighting improved multimodal understanding that can benefit documentation, UI prototyping, and data analysis. Crucially, these gains arrive without sacrificing speed: in terms of output throughput, Gemini 3.5 Flash can stream responses about four times faster than other frontier models, making it highly suitable for IDE integrations, chat-based pair programming, and continuous integration bots. Available via the Gemini API, Google AI Studio, and Android Studio, it gives teams a high-performance AI model coding performance option that feels more like a live collaborator than an offline batch tool.
Built for Agentic AI Capabilities and Long-Horizon Tasks
Gemini 3.5 Flash is explicitly designed for agentic AI capabilities, moving beyond answering questions to taking action across complex workflows. Google describes it as ideal for long-horizon agentic tasks, where an AI must plan, build, and iterate through many steps. Benchmarks like GDPval-AA, where the model scores 1656 Elo, illustrate its strength in multi-step decision-making. Under supervision, Gemini 3.5 Flash can reliably execute multi-step workflows and coding pipelines while sustaining frontier-level performance. Partners, including financial institutions, have reportedly used it to compress multi-week workflows into a fraction of the time. Integrated with Google’s Antigravity agent-first development platform, the model can coordinate multiple subagents in parallel, orchestrating everything from codebase maintenance and test generation to report drafting and data pipeline updates. By embedding action orientation into the core model, Google is signaling that AI agents—not just chatbots—are now central to its roadmap.

From Search to Enterprise: A New Default for Latency-Sensitive Workloads
Gemini 3.5 Flash is not just a developer tool; it is being pushed as Google’s new default AI model across consumer and enterprise surfaces. Billions of users will encounter it first in the Gemini app and AI Mode in Search, where faster response times and richer, more interactive outputs—like dynamic web UIs and graphics—are critical. On the enterprise side, the model is generally available via the Gemini Enterprise Agent Platform and Gemini Enterprise, enabling organizations to plug high-speed, agentic AI into operations that are highly latency-sensitive, such as customer support, fraud detection workflows, or internal knowledge agents. It also powers Gemini Spark, a personal AI agent that runs continuously to take actions on a user’s behalf under their direction. By pairing Gemini 3.5 Flash speed with robust safeguards and interpretability tools, Google aims to make advanced autonomous capabilities accessible without demanding flagship-level infrastructure from every team.