
What the Next-Gen OpenSearch Serverless Actually Is
Amazon’s next generation of OpenSearch Serverless is a fully managed search and vector engine that separates storage and compute to deliver 20x faster resource provisioning, true scale-to-zero, and lower costs for spiky AI workloads. This redesign targets the new traffic patterns created by AI agents, coding assistants, and search-heavy applications that see sudden demand spikes followed by quiet periods. AWS now positions OpenSearch Serverless as a core piece of AI search infrastructure rather than only a classic enterprise search and observability tool. Engineers can create text and vector search backends via the web console, AWS SDK, or CLI, with CloudFormation support on the roadmap. In practice, the service aims to give teams a way to handle rapid, unpredictable AI demand without keeping clusters over-provisioned or paying for idle OpenSearch Capacity Units when agents are dormant.
Inside the New AWS Serverless Architecture
The NextGen architecture introduces a shared storage layer that fully decouples data from compute, turning OpenSearch Capacity Units (OCUs) into stateless workers. With data stored outside the OCU, new capacity can come online in seconds because there is no disk bootstrap phase; the storage is mounted directly when an OCU starts. According to AWS, this change makes resource provisioning 20 times faster than the earlier OpenSearch Serverless architecture and enables efficient scale down, since idle OCUs can be dropped without touching user data. The design also adds new endpoint options: per-collection endpoints for one-to-one access and per-account regional endpoints that route to any collection via headers, improving connection pooling and TLS session reuse. Collection groups now sit at the center of configuration, defining whether workloads run on the Classic or NextGen model and letting teams share compute capacity across multiple collections.
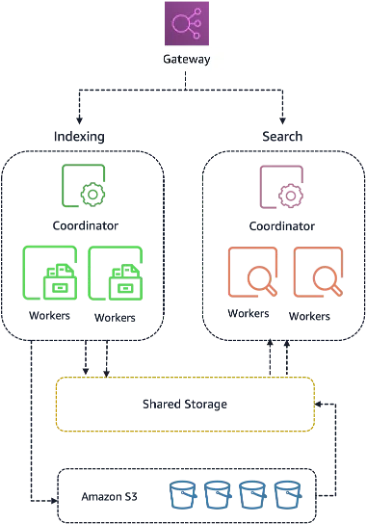
Why Separating Storage and Compute Matters for AI Search
For agentic AI and retrieval-heavy applications, traffic is spiky and unpredictable: coding agents may fire large search bursts, then sit idle. Historically, search systems tied data and compute together, so clusters had to stay warm and over-provisioned to avoid slow restarts. AWS’s new OpenSearch Serverless architecture breaks this pattern by separating storage and compute, so collections can scale down “all the way to zero when nothing's happening,” as Tia White, director of OpenSearch at AWS, explains. When demand picks up, stateless OCUs can spin back in seconds, addressing the cold-start pain that previously made search a bottleneck for AI experiments. This behavior is crucial for AI search infrastructure that serves agents, RAG pipelines, and hybrid text–vector workloads, where the right balance is rapid elasticity, predictable performance, and not paying for dormant capacity between inference bursts.
Proprietary Storage and the AI Performance Trade-Off
Although OpenSearch remains an open-source project under the Linux Foundation, the storage engine behind NextGen OpenSearch Serverless is now a proprietary AWS layer. White notes that some logic in the new serverless system is available in the open source project, but the custom-built storage tier is part of Amazon’s intellectual property and there are currently no plans to release it. The goal is to tune this storage for mega-scale AI demands, where high-throughput vector search, fast indexing, and rapid failover matter more than strict portability. This move echoes earlier tensions between cloud providers and database vendors such as Elastic, MongoDB, and MariaDB over how much value can sit in managed services versus community code. For enterprises, the trade-off is clear: a more opinionated, AWS-optimized storage layer in exchange for higher OpenSearch Serverless performance under AI-heavy, search-intensive workloads.
Developer Experience and the Race for Agentic AI Infrastructure
Beyond architecture, the release leans heavily into developer workflows and agent-led development. OpenSearch Serverless now integrates with Vercel, so teams can spin up serverless collections from the Vercel console without switching tools. It also powers OpenSearch Launchpad inside Kiro, AWS’s agentic coding IDE, where agents help plan and configure search architectures end-to-end. AWS has contributed OpenSearch Agent Skills that let developers manage collections from AI-assisted coding platforms such as Claude Code, Cursor, and Codex. On the AWS side, an “Express” create flow in the console hides many configuration details, shortening time-to-deployment. Together, these changes position OpenSearch Serverless as a key AWS serverless architecture component for AI agents, competing with Elasticsearch Serverless, Postgres plus pgvector, and specialist vector databases, but with a focus on dynamic resource provisioning speed and tight integration into modern AI development environments.






