What Claude Opus 4.8 Is and Why It Matters
Claude Opus 4.8 is Anthropic’s latest flagship AI coding assistant model, designed to handle complex software engineering, reasoning, and autonomous workflow tasks for enterprise AI development teams. Positioned as a major step up from Opus 4.7, it focuses on stronger coding performance, lower hallucination rates, and better self-correction during long reasoning chains. Anthropic says the upgrade is aimed at real-world enterprise environments where AI must work inside existing engineering processes, not just answer chat prompts. That context explains the emphasis on agentic coding and computer-use benchmarks, where Opus 4.8 now posts top-tier scores against rivals from OpenAI and Google. For organisations experimenting with AI in production pipelines—bug triage, patch generation, research tasks—Opus 4.8 signals that Claude is shifting from a conversational assistant into a serious development platform.
Advanced Coding Features Raise the Bar on SWE-Bench and Beyond
The headline change in Claude Opus 4.8 is its agentic coding strength. On SWE-Bench Pro, a demanding benchmark that measures how AI resolves real GitHub issues and produces working patches, Opus 4.8 scored 69.2%, beating Opus 4.7 at 64.3%, OpenAI’s GPT-5.5 at 58.6%, and Google’s Gemini 3.1 Pro at 54.2%. That gain matters because SWE-Bench Pro tests end-to-end behavior: reading unfamiliar repositories, debugging, and editing code so tests pass. In terminal-centric workflows, OpenAI still leads, with GPT-5.5 reaching 78.2% on Terminal-Bench 2.1 versus Opus 4.8’s 74.6%, but Anthropic has closed the gap sharply from Opus 4.7’s 66.1%. For developers, this translates into an AI coding assistant that is better at taking on full tickets in large codebases, not only generating snippets in isolation.
Reasoning, Reliability, and the Push for Enterprise Readiness
Beyond raw coding scores, Claude Opus 4.8 strengthens reasoning and reliability—two traits enterprises now expect from AI development tools. On Humanity’s Last Exam, a multidisciplinary expert-level reasoning benchmark, Opus 4.8 reached 49.8% without tools and 57.9% with tools, surpassing both Opus 4.7 and GPT-5.5. Anthropic also highlights reduced hallucinations: early tests suggest the model is more likely to acknowledge uncertainty instead of inventing unsupported answers. For AI coding assistant deployments, that behavior is key. Teams can accept “I’m not sure” far more easily than a confident but wrong patch merged into production. Combined with effort controls and a faster mode introduced around this release cycle, Opus 4.8’s profile is shifting toward dependable, configurable assistance that can align with internal governance and review practices.
Mythos, BugCrawl, and the Emerging Claude Agent Ecosystem
Claude Opus 4.8 lands alongside signals that Anthropic is building an ecosystem of specialized agents and tools around its models. A notable piece is Claude Mythos, an advanced cybersecurity-focused system moving from restricted access into a broader rollout. According to The Tech Portal, Mythos scanned around 1,000 open-source projects and found more than 23,000 security vulnerabilities within minutes, raising both interest and concern among policymakers. On the development side, internal references describe BugCrawl, a Claude Code feature aimed at general bug-finding: it would pick repositories, pull tickets from systems like GitHub, Jira, or Linear, add tests, propose fixes, and watch rollouts, with warnings about heavy token use. Together with Opus 4.8’s advanced coding features, these moves show Anthropic orienting Claude toward end-to-end software maintenance, not just code generation.
From Chatbot to Enterprise AI Development Platform
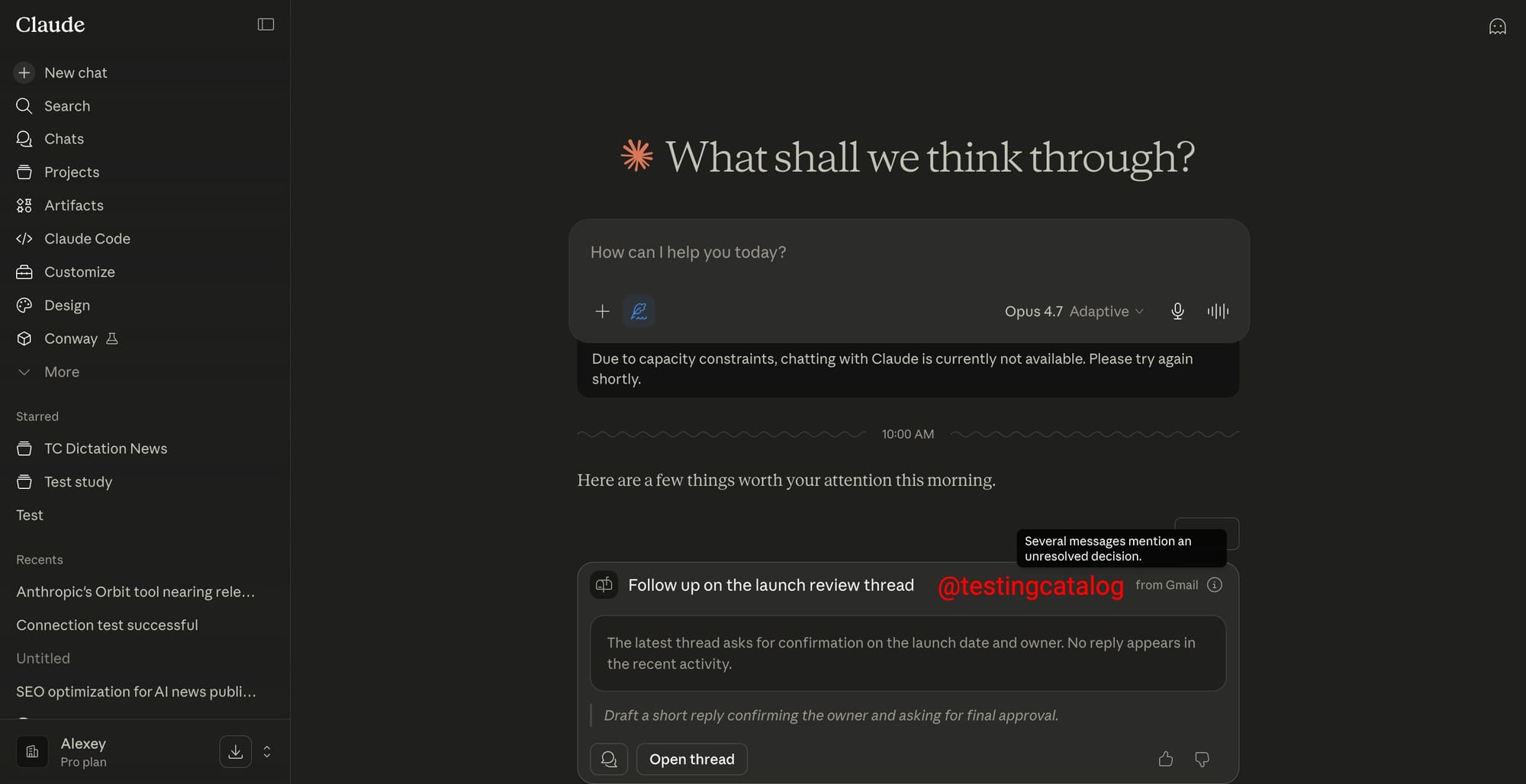
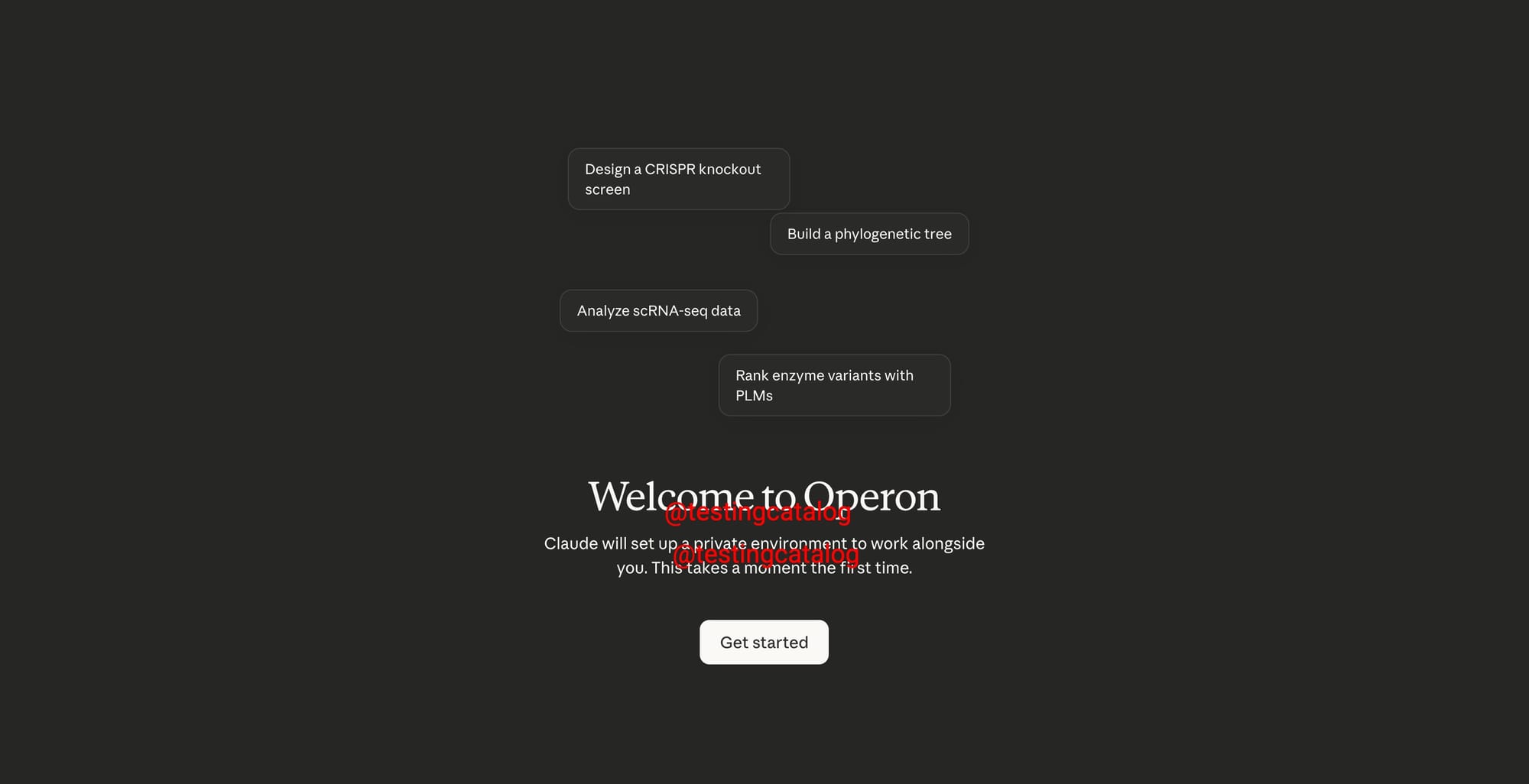
Looking a few weeks ahead, hints from product strings suggest Opus 4.8 is only the base layer of a broader enterprise AI development platform. Conway, an always-on managed-agent environment, is expected to let users connect integrations, install skills, and arrange tools as tabs—ideal for persistent coding and workflow agents powered by Opus-grade models. Orbit aims to surface proactive insights from systems like Gmail, Slack, GitHub, and Drive, while Operon targets life sciences work as a dedicated desktop mode alongside Claude Chat and Claude Code. A shared file-based memory layer and a refreshed security dashboard would give enterprises more continuity and oversight over AI behavior. In this context, Claude Opus 4.8’s coding and reasoning gains are not isolated metrics; they are the engine for a competitive, multi-agent AI coding assistant stack designed for production use.





