
What Claude Opus 4.8 Is and Why It Matters
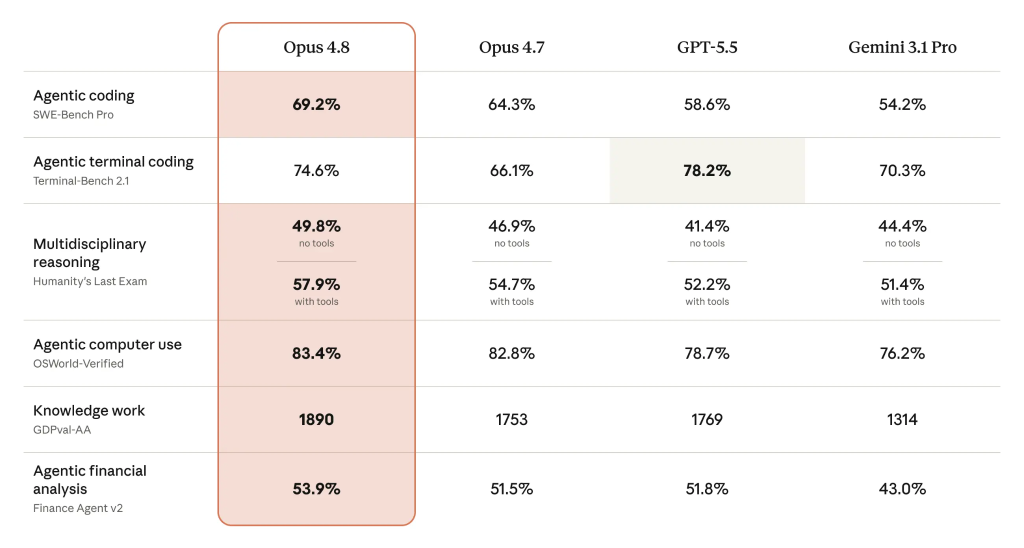
Claude Opus 4.8 is Anthropic’s newest flagship large language model, released on May 28, designed to outperform rival frontier models on AI model benchmarks while giving users tighter control over speed, depth of reasoning, and workflow complexity for coding, analysis, and agentic tasks. Anthropic says Opus 4.8 improves on Claude 4.7 while remaining available at the same price, and early benchmarks indicate it beats GPT-5.5 and Gemini 3.1 Pro across almost all evaluated tasks, with the notable exception of agentic terminal coding where OpenAI’s model still leads. The upgrade targets users who want faster cheaper AI options without sacrificing capability, especially for larger coding jobs and long-running professional work. Combined with new features for effort controls, dynamic workflows, and better honesty in responses, Opus 4.8 positions Anthropic as a top contender in the current wave of advanced general-purpose models.
Effort Controls and Cheaper Fast Mode: More Than a Speed Knob
Effort controls in Claude Opus 4.8 let users adjust how much computation the model spends on a task, trading depth of reasoning for latency and token usage. At higher effort, Claude “will think more frequently and more deeply to give a better response,” Anthropic explains, while low-effort mode returns quicker answers and slows down how fast users hit rate limits. This aligns with demand for faster cheaper AI that can be tuned per request instead of forcing a one-size-fits-all setting. Alongside effort controls, Anthropic has introduced a cheaper fast mode option so users can reserve high-effort reasoning for complex decisions and keep routine queries economical. Together, these controls make Opus 4.8 more predictable for developers and teams who need to balance quality, speed, and budget across a mix of interactive chats, coding sessions, and automated workflows.
Dynamic Workflows and Bigger Coding Tasks
Claude Opus 4.8’s new dynamic workflows, currently in research preview, target a long-standing limitation: handling larger, more structured coding projects inside a single AI session. Anthropic says users can now ask Claude to “plan the work and then run hundreds of parallel subagents in a single session,” after which the system verifies outputs before returning them. This turns the model into a lightweight project manager for complex tasks like multi-file refactors, large feature additions, or wide-ranging codebase audits. In Microsoft Foundry, Opus 4.8 is framed as “designed to support real-world software development tasks, from feature work and debugging to refactoring, migrations, and multi-stage coding projects.” The ability to read and reason across codebases, track dependencies through longer sessions, and continue work with less manual oversight makes it more suitable for sustained development workflows than earlier generations.

Honesty, Reduced Deception, and Deeper Reasoning
Alongside raw performance, Anthropic highlights honesty and reduced deception as core changes in Claude Opus 4.8. The model is described as more transparent about its limits and better at supporting user autonomy and best interests, aiming to lower the risk of confidently wrong or manipulative outputs in sensitive workflows. This emphasis pairs with deeper reasoning abilities across long documents and complex multi-source inputs. According to Microsoft’s Foundry blog, Claude Opus 4.8 is “designed for professional work that requires reasoning across long documents, complex inputs, and multiple sources,” supporting tasks like research synthesis, financial analysis, contract review, and cybersecurity analysis. For enterprises that want explainable, auditable outputs from AI systems, the combination of stronger reasoning, explicit effort controls, and guardrails around deceptive behavior is likely to be as important as headline benchmark wins over GPT-5.5 and Gemini 3.1 Pro.
Enterprise Impact: Claude Opus 4.8 in Microsoft Foundry
The availability of Claude Opus 4.8 in Microsoft Foundry signals its shift from lab model to production workhorse. Foundry provides a unified environment for developers to work with leading models, compare fit against their own data, and move from experimentation to live deployment with enterprise controls. In this context, Opus 4.8 is positioned for coding strength, agentic capability, and deep reasoning in document-heavy tasks, from legal and financial workflows to life sciences and cybersecurity. Microsoft notes that the model is designed to use tools more reliably across multi-step workflows, recover from errors, and maintain coherence over longer periods of work—key requirements for agents that must plan, act, and adapt rather than answer a single question. For teams building complex, longer-running AI applications, these traits may matter more than any one benchmark chart.





