From Code Snippets to Full Codebase Restructuring
Scale Labs’ new Refactoring Leaderboard marks a shift from testing AI on toy problems to measuring performance on real-world codebase restructuring. Built as the final pillar of SWE Atlas, the research suite evaluates AI coding agents across the broader software development lifecycle, including codebase comprehension, test writing, and now complex AI code refactoring. Instead of single-file prompts, agents are dropped into production-style repositories where they must interpret existing architecture, edit multiple files coherently, and keep tests green. Refactoring tasks in SWE Atlas demand roughly twice as many lines of code changes and 1.7 times more file edits than the suite’s SWE-Bench Pro tasks, making this benchmark a high-pressure coding agent benchmark for multi-file engineering work. The intent is to see whether agents behave more like dependable software engineers than autocomplete tools, especially when asked to change structure without altering behavior.
What the Refactoring Leaderboard Actually Measures
The Refactoring Leaderboard targets four core patterns of AI code refactoring that mirror common maintenance work in mature systems. Agents are asked to decompose monolithic implementations into smaller units, replace weak interfaces with clearer or more strongly typed abstractions, extract duplicated or misplaced logic into shared modules, and relocate code to improve module boundaries. Each task assesses whether the agent can restructure code while preserving existing behavior. Evaluation blends automated checks with rubric-based review: tests must continue to pass, but reviewers also inspect maintainability, artifact cleanup, avoidance of anti-patterns, and documentation quality. This dual lens exposes a crucial distinction. Many models can technically pass tests yet still leave dead code, stale imports, duplicated logic, outdated comments, or missed call sites. In practice, this “cleanup gap” separates agents that merely achieve correctness from those capable of production-grade codebase restructuring.
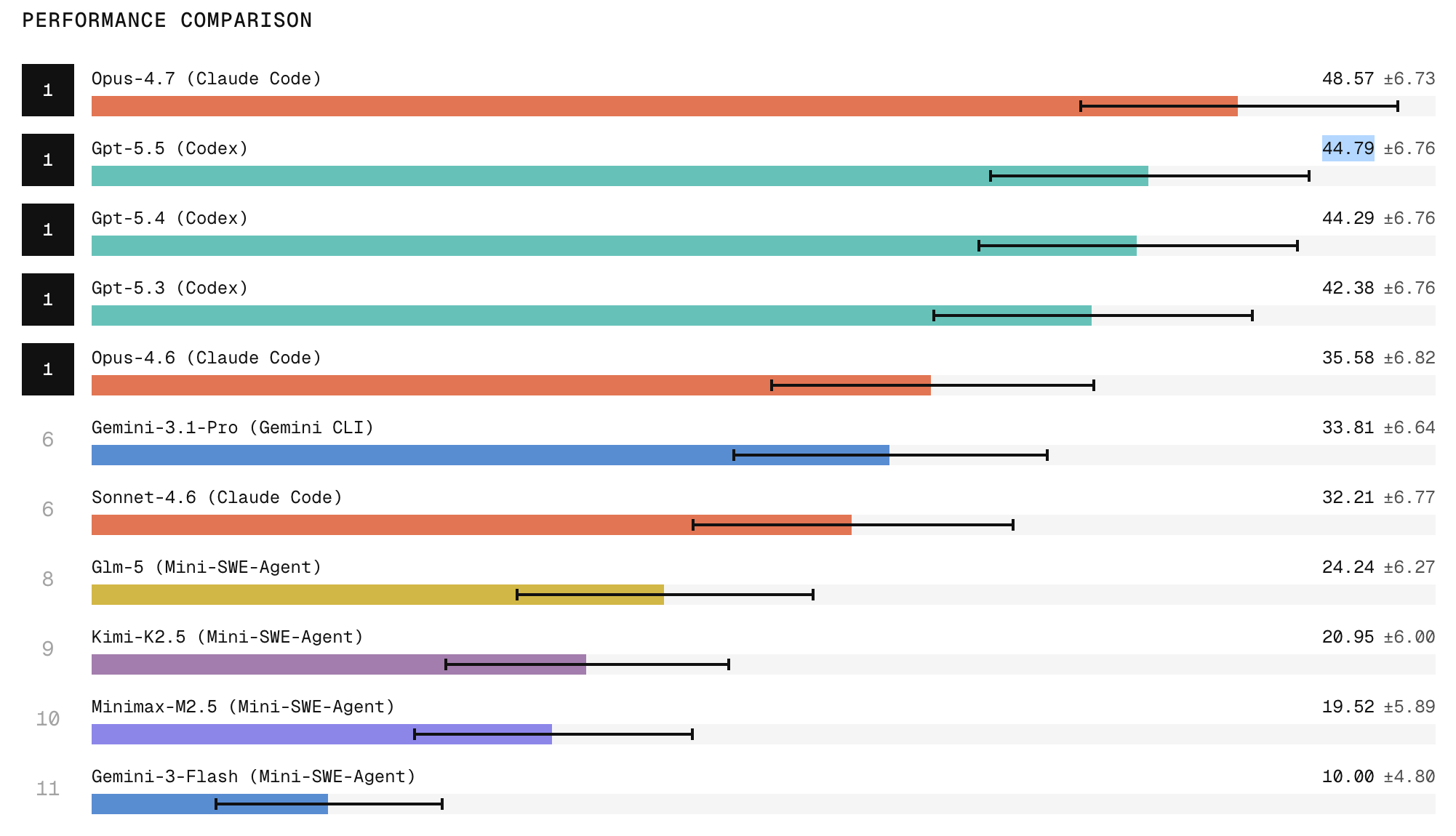
Leaders, Laggards, and the Open-Model Gap
Early results from the Refactoring Leaderboard highlight meaningful separation between today’s AI development tools. Claude Code with Opus 4.7 currently ranks first, with research indicating it produces the strongest refactors among evaluated agents, while ChatGPT 5.5 holds second place. Scale Labs also reports a pronounced gap between frontier closed models and open-weight systems. Open models tend to struggle on tasks demanding broad repository exploration, structural edits that touch many files, and strict behavior preservation, all of which are essential for safe AI code refactoring. The leaderboard makes these differences visible, turning anecdotal impressions into a comparative coding agent benchmark. For engineering teams, this transparency helps clarify which tools are more likely to handle complex refactors, and where open solutions still lag in robustness, coordination, and code hygiene when applied to large-scale, production-style repositories.
Reliability: The Hidden Constraint on Autonomous Agents
Beyond raw capability, Scale Labs emphasizes reliability as the central constraint on deploying AI coding agents in unattended workflows. When models attempt the same refactoring task three times, they are two to three times more likely to succeed at least once than to succeed consistently across all three runs. That gap means a model may look impressive in a demo, yet remain too inconsistent for automated production pipelines. The Refactoring Leaderboard therefore measures not just peak performance but repeatability under similar conditions. Findings show agents still struggle with consistent cleanup, artifact removal, and holistic understanding of large codebases. For teams considering AI development tools for codebase restructuring, this highlights a practical takeaway: today’s strongest models can be powerful copilots but still require human oversight to ensure that structural changes are safe, maintainable, and reliably reproducible.
Toward a New Standard for AI Code Refactoring
By framing evaluation around realistic engineering workflows, Scale Labs’ SWE Atlas positions AI agents as potential teammates rather than mere code generators. The Refactoring Leaderboard in particular addresses one of the hardest problems in software automation: modifying architecture without introducing regressions. As organizations confront sprawling legacy systems, they increasingly need tools that can assist with long-term codebase restructuring, not only new feature scaffolding. A public leaderboard offers a shared reference point for comparing AI development tools on that dimension, helping teams choose agents that can navigate complex repositories, respect design constraints, and keep tests passing while improving structure. The early results, with Opus 4.7 at the top and a visible gap to open models, suggest rapid progress but also underline that consistency and engineering-quality output still lag behind peak capabilities—an important reality check for anyone planning to automate refactoring at scale.