
What DiffusionGemma Is and Why It Looks Different
DiffusionGemma is an experimental 26B mixture-of-experts on-device AI model from Google DeepMind that uses diffusion, rather than standard autoregressive decoding, to generate blocks of text in parallel for much higher text generation speed on local GPU inference. Instead of predicting one token at a time, DiffusionGemma denoises up to 256 tokens per step, refining noisy text into a coherent answer in a process similar to diffusion-based image models. Built on the Gemma 4 architecture, it activates about 3.8 billion parameters per step, so it does not need the full parameter set in memory during inference. Google positions it as a specialist model for latency-sensitive tasks such as inline editing and code infilling, where responsiveness can matter more than absolute benchmark scores.
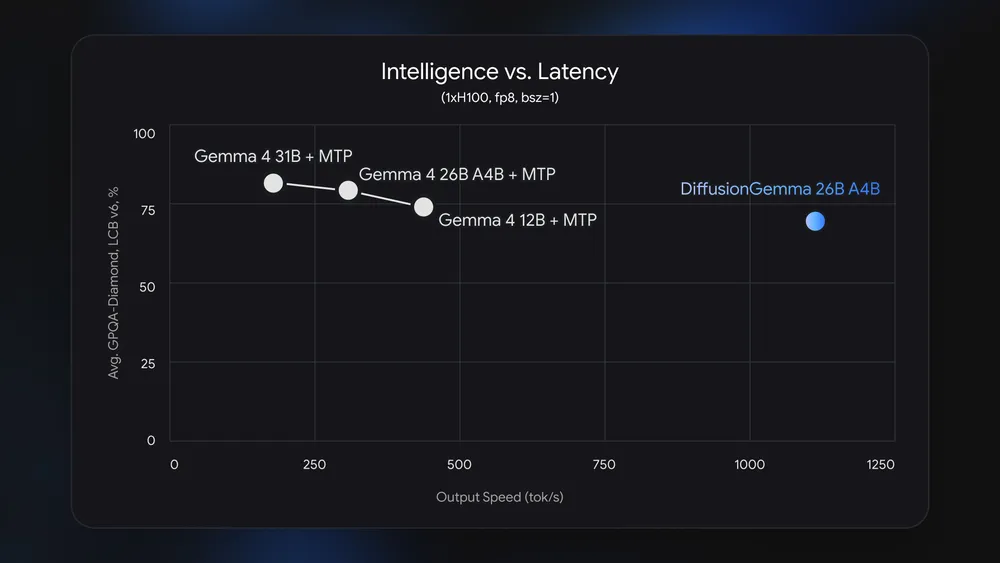
The 4x Speed Tradeoff: Where Performance Matters Less
Google’s own benchmarks show DiffusionGemma underperforming the standard Gemma 4 26B A4B model on quality tests, but that is a deliberate tradeoff for speed. The diffusion head is tuned so that the model can generate more than 1,000 tokens per second on a single Nvidia H100 and run on GPUs with around 18GB of VRAM. For many coding and inline editing flows, the key metric is latency, not a few extra points on a leaderboard. In those situations, a model that responds four times faster can keep you in the flow, while a slower, more accurate one feels laggy. Google is explicit about the split: “For applications that demand maximum quality, we recommend deploying standard Gemma 4,” leaving DiffusionGemma as the lower-latency specialist.

RTX and DGX: Making Real-Time Local Inference Practical
NVIDIA has delivered day-one support for DiffusionGemma across its RTX and DGX platforms, turning the model from an intriguing demo into a practical tool for local GPU inference. According to NVIDIA, H100 GPUs on DGX Stations can reach around 1,000 tokens per second, DGX Spark systems hit about 150 tokens per second, and DGX Station offers “the fastest in-class local inference.” The model is open-weight under an Apache 2.0 license and already integrated with Hugging Face Transformers, vLLM, and Unsloth. That stack means developers can plug DiffusionGemma into existing workflows while keeping everything on-device. For RTX 5090 and 4090 owners, this makes high-throughput text generation speed attainable without specialized datacenter infrastructure, moving serious DiffusionGemma performance into deskside machines.

Why Local Speed Matters for Everyday Developer Workflows
For developers, the key promise of DiffusionGemma is fast, on-device AI models that keep up with interactive work. Code infilling, inline documentation, and natural-language search across repos all benefit from near-instant responses. With up to 4x faster throughput than equivalent autoregressive models on the same hardware, DiffusionGemma can support smooth real-time suggestions instead of occasional bursts of generated text. Running locally on RTX desktops or DGX Spark removes cloud round-trips, per-token metering, and data sharing concerns, which is important for proprietary codebases and private documents. The model’s design — parallel denoising of 256 tokens with all-to-all attention — is well suited to editing and rewriting spans inside long contexts rather than only appending new tokens, which aligns directly with editor-style workflows in IDEs and productivity tools.

An Experimental Architecture for Latency-Sensitive On-Device AI
DiffusionGemma is still experimental, but its architecture hints at where latency-sensitive on-device AI might go next. Instead of pushing parameter counts ever higher, it focuses on a diffusion head, sparse activation through mixture-of-experts, and efficient formats such as BF16 and NVFP4 to keep local GPU inference fast. Context lengths up to 256K tokens open the door to agents that can read entire codebases or large document sets while still returning answers in real time. Because the model is open and runs without cloud dependency on RTX and DGX hardware, teams can test agentic loops, local copilots, and domain-specific fine-tuning without rewriting their infrastructure. Even if standard Gemma 4 remains the pick for maximum accuracy, DiffusionGemma’s performance-first design shows how future models may prioritize latency and interactivity as much as raw benchmark scores.






