
What Fugu Ultra Is and Why It Matters
Fugu Ultra is a multi-agent orchestration system from Sakana AI that coordinates a pool of language models through a single OpenAI-compatible API, aiming to deliver frontier-level performance without relying on one gigantic model. Instead of a monolithic frontier AI model, Fugu Ultra acts as a conductor: it can assign subtasks across several expert LLMs, including versions of itself, and merge their outputs into a single answer. The system targets demanding, multi-step workflows in engineering, science, cybersecurity, and research where long context, consistency, and thoroughness matter more than raw token-per-second speed. By wrapping this complexity behind a familiar API, Sakana lowers the switching cost for teams already building on OpenAI-style endpoints. This design directly questions the idea that only vast compute budgets and single supersized models can reach the top of modern AI benchmarks.

Multi-Agent Orchestration vs Monolithic Frontier Models
Sakana’s approach rests on the idea that AI model orchestration can rival or exceed monolithic frontier AI models. The Fugu Ultra model does not lock into fixed roles for each agent; instead, it dynamically routes tasks among a pool of models and composes their results. Under the hood, research like TRINITY and Conductor informs how Fugu assigns Thinker, Worker, and Verifier roles over multiple turns and learns natural-language coordination strategies. This means workflows are not hand-designed but discovered through reinforcement learning, allowing patterns humans might miss. Multi-agent orchestration has strategic advantages: it can reuse existing models, adapt as new ones arrive, and avoid the cost curve of ever-larger single models. For smaller labs, this offers a credible route to competitive systems without matching the compute scale of frontier labs, reframing the race as one of coordination rather than sheer size.
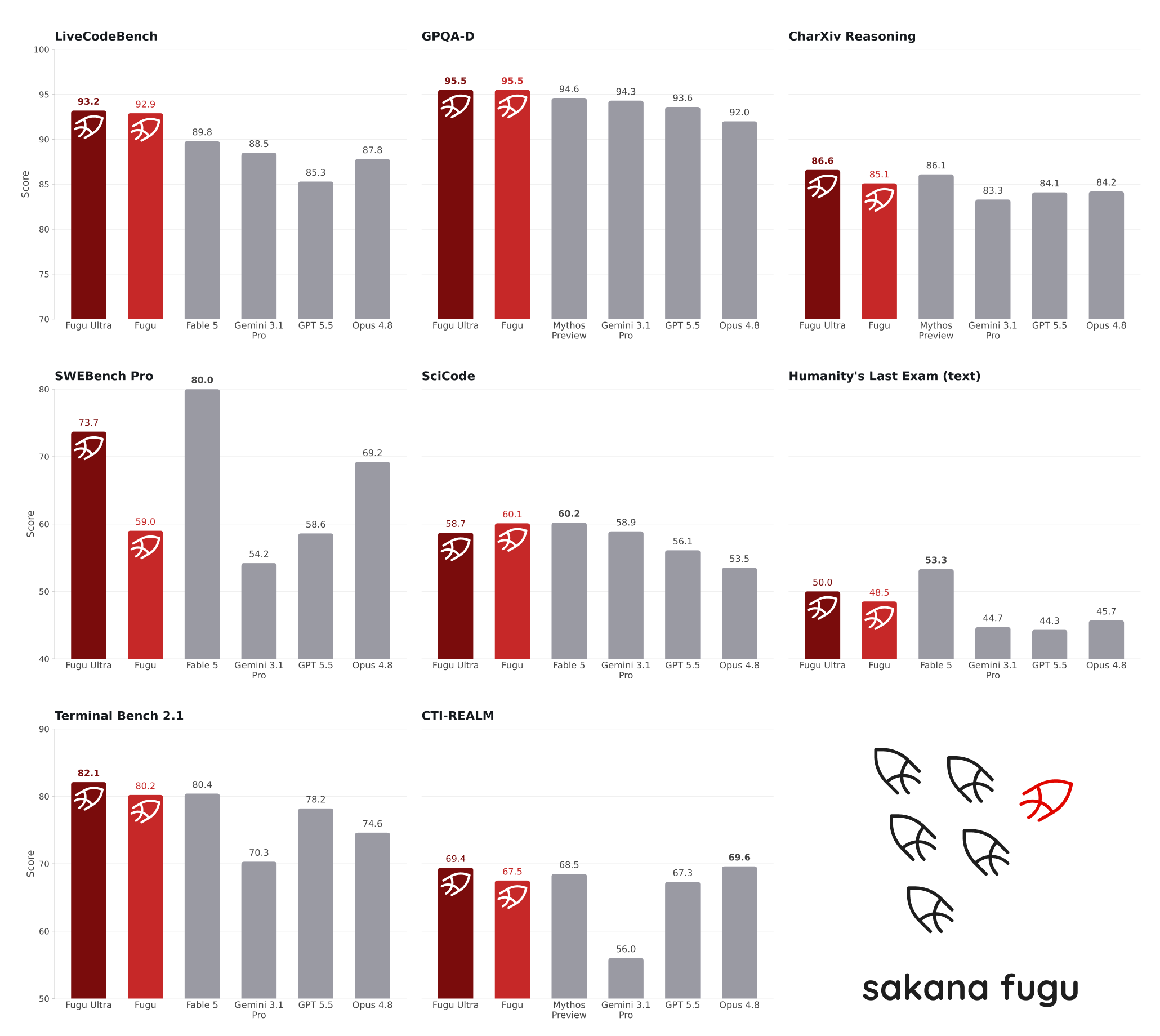
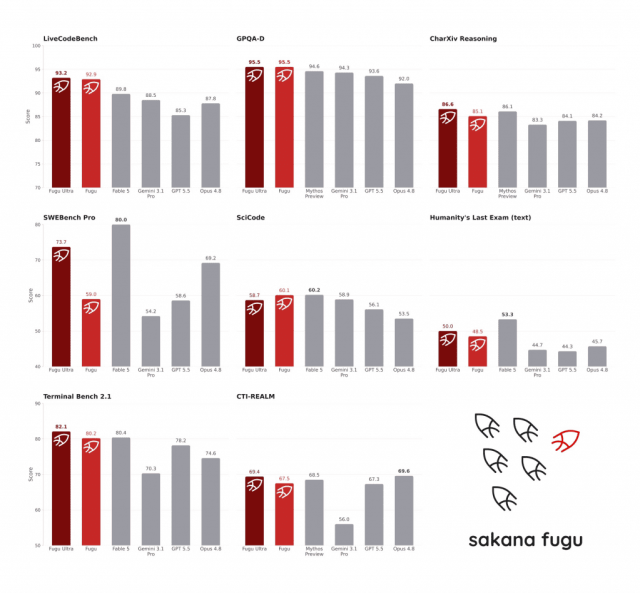
Benchmark Performance and Early Real-World Results
On public benchmarks, Fugu Ultra’s multi-agent orchestration delivers results close to the best frontier AI models. According to OfficeChai, “On SWE-Bench Pro, Fugu Ultra scores 73.7, ahead of Claude Opus 4.8’s 69.2 and GPT-5.5’s 58.6.” It also posts 93.2 on LiveCodeBench, beating Gemini 3.1 Pro’s 88.5, and reaches 50.0 on Humanity’s Last Exam, essentially matching Opus 4.8’s 49.8. Qualitative tests mirror those numbers: in an AutoResearch setup on a single H100 GPU, Fugu Ultra achieved the best mean validation score versus three frontier baselines. Early users report that it maintains persona consistency through long code reviews or security assessments and surfaces more issues over extended sessions. These results suggest that carefully orchestrated teams of models can stand shoulder-to-shoulder with top single models on both controlled benchmarks and open-ended research tasks.
API Compatibility, Pricing, and Vendor Flexibility
A key part of Fugu Ultra’s pitch is practicality. Everything flows through one OpenAI-compatible API, so developers can swap in the Fugu Ultra model without redesigning their stack or juggling multiple providers. Sakana offers two tiers under this interface: a standard Fugu for everyday coding and chat, and Fugu Ultra for long-horizon tasks like paper reproduction, Kaggle-style competitions, and patent or literature analysis. Pricing is agent-aware: when one agent runs, users pay that model’s normal rate; when several coordinate, Sakana charges a single rate based on the top-tier model rather than stacking fees. Fugu Ultra is fixed at USD 5 (approx. RM23) per million input tokens and USD 30 (approx. RM138) per million output tokens, doubling for contexts above 272K tokens. Enterprises can also exclude specific models from the pool, giving them fine control over vendors and data residency constraints.
What Fugu Ultra Signals for the Future of AI Development
Fugu Ultra strengthens the case that multi-agent orchestration is a viable alternative to scaling a single frontier AI model. Sakana frames this as a path toward AI sovereignty, letting organizations reach near-frontier performance while avoiding single-vendor dependence or export-control bottlenecks. Because the agent pool can evolve, each new model added potentially lifts system performance without retraining everything from scratch. This modularity fits Sakana’s broader research direction, which emphasizes extracting more value from existing models rather than brute-force scaling. For the wider ecosystem, Fugu Ultra sets a precedent: smaller labs can compete at the frontier by innovating in coordination, routing, and workflow design instead of chasing the largest model alone. If this trend continues, the most capable AI systems may look less like isolated giants and more like carefully managed collectives of specialized models.





