From Being Overshadowed to Mounting a Comeback
Cursor was an early standout among AI coding tools, but momentum shifted as Claude Code and other rivals surged ahead in coding use-cases. Anthropic’s Claude Opus family, bundled into Claude Code, reportedly brings in massive enterprise adoption, leaving Cursor in the awkward position of paying Anthropic for inference while competing with them. That squeeze has pushed Cursor toward owning more of its stack. Composer 2.5 is the sharpest expression of that strategy so far: an in-house tuned model designed to close the performance gap with top-tier assistants while resetting the economics of code generation performance. Instead of swapping base models, Cursor doubles down on tuning the open-source Kimi K2.5 checkpoint, betting that better post-training and agent design can reclaim relevance in long, complex coding jobs where it had been losing share to Claude.

Benchmarking Against Claude Opus and GPT: Close Enough to Matter
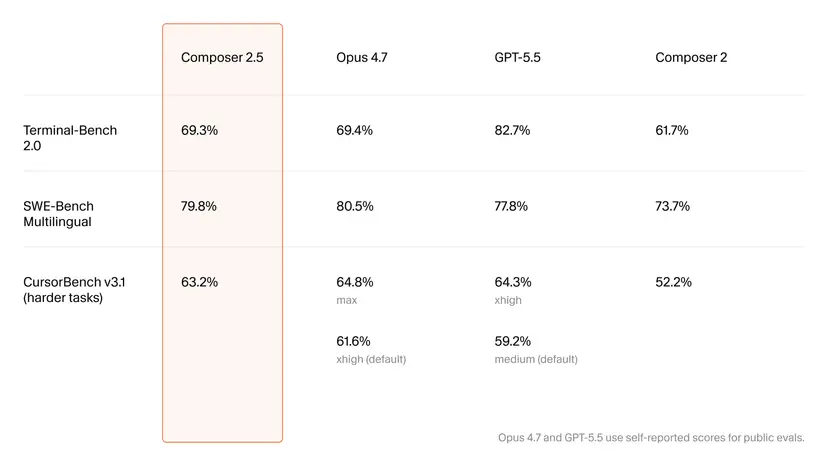
On headline benchmarks, Composer 2.5 now sits in the same conversation as Claude Opus 4.7 and GPT-5.5. Cursor reports a 79.8% score on SWE-Bench Multilingual, narrowly trailing Opus 4.7’s 80.5% while edging ahead of GPT-5.5’s 77.8%. On Terminal-Bench 2.0, Composer 2.5 clocks in at 69.3%, effectively tied with Opus 4.7’s 69.4%, though GPT-5.5 still leads at 82.7%. Cursor’s own harder-task benchmark, CursorBench v3.1, shows the company’s model at 63.2%, compared with Opus 4.7’s 64.8% at max settings and 61.6% on its default, and GPT-5.5 at 59.2%. These numbers don’t dethrone the incumbents, but they mark a significant leap over Composer 2 and place Composer 2.5 as a credible Claude Opus alternative for developers who care about both code generation performance and price.

Targeted Reinforcement Learning and 25x Synthetic Tasks
Instead of replacing its base with a new large model, Cursor kept Moonshot Kimi K2.5 and invested heavily in post-training. Composer 2.5 was trained on roughly 25 times more synthetic tasks than its predecessor, a scale-up aimed squarely at complex, multi-step coding work. Cursor adds targeted reinforcement learning with localized textual feedback, allowing the model to receive fine-grained corrections during long rollouts rather than only at the end of a task. This is paired with more complex RL environments and improved behavioral calibration to refine communication style, effort allocation, and consistency across files. The result, according to Cursor’s internal testing and early user feedback, is a coding agent that better follows nuanced instructions, maintains project context during extended sessions, and handles tool calls more reliably—all critical for long-running refactors and multi-file changes that stress weaker AI coding tools.
Cost Efficiency: Up to 10x Gains to Undercut Rivals
Composer 2.5’s most aggressive play is economic. Cursor positions the model as delivering near-Opus-level performance at a fraction of the price, claiming up to 10x cost efficiency improvements over previous Composer versions. Standard Composer 2.5 is priced at USD 0.50 (approx. RM2.30) per million input tokens and USD 2.50 (approx. RM11.50) per million output tokens. A faster default variant is available at USD 3.00 (approx. RM13.80) per million input tokens and USD 15.00 (approx. RM69.00) per million output tokens. These tiers are designed to give teams predictable, scalable cost efficiency coding options while Cursor gradually weans itself off external providers. By aligning strong benchmarks with materially lower token rates, Cursor is signaling that its long-term strategy is to compete less on absolute quality and more on the quality-to-cost ratio in day-to-day development.
Real-World Stakes: Long-Running Agents and Cursor’s Next Move
Benchmarks alone won’t decide whether Composer 2.5 can displace Claude in developers’ daily workflows. Cursor’s own users and community critics note that high scores on SWE-Bench or Terminal-Bench do not always translate into clean, context-aware pull requests. The real test will be live multi-file refactors, long-running agents that keep specifications straight, and whether generated code genuinely reduces cleanup work. Composer 2.5 is explicitly designed for those scenarios, with improved long-horizon reliability and behavioral calibration to stay aligned with existing codebases. Cursor is also collaborating with SpaceXAI on a larger, more compute-intensive model, suggesting that Composer 2.5 is a stepping stone rather than an endpoint. For now, though, it marks a clear comeback attempt: using targeted reinforcement learning, massive synthetic training, and aggressive pricing to reinsert Cursor into the top tier of AI coding tools.