
From Pipeline Sprawl to Model Lifecycle Management
As enterprise ML estates grow, traditional pipeline-centric tooling struggles to keep pace with rising complexity. Netflix’s engineering teams describe an environment where numerous datasets, features, pipelines, experiments, and deployed models span multiple squads, making it hard to answer basic questions: Where did this model come from? Which upstream datasets does it depend on? What breaks if a feature changes? Their answer is the Model Lifecycle Graph, an internal architecture focused on model lifecycle management rather than isolated workflows. Instead of treating each pipeline as a self-contained artifact, Netflix elevates ML metadata—datasets, models, evaluations, workflows, and production services—to first-class infrastructure objects. This metadata-first lens reflects a broader shift across enterprise ML systems, where visibility, traceability, and reuse are becoming as important as raw experimentation speed. By explicitly modeling relationships, Netflix aims to reduce operational friction and make ML scaling architecture more predictable and auditable.
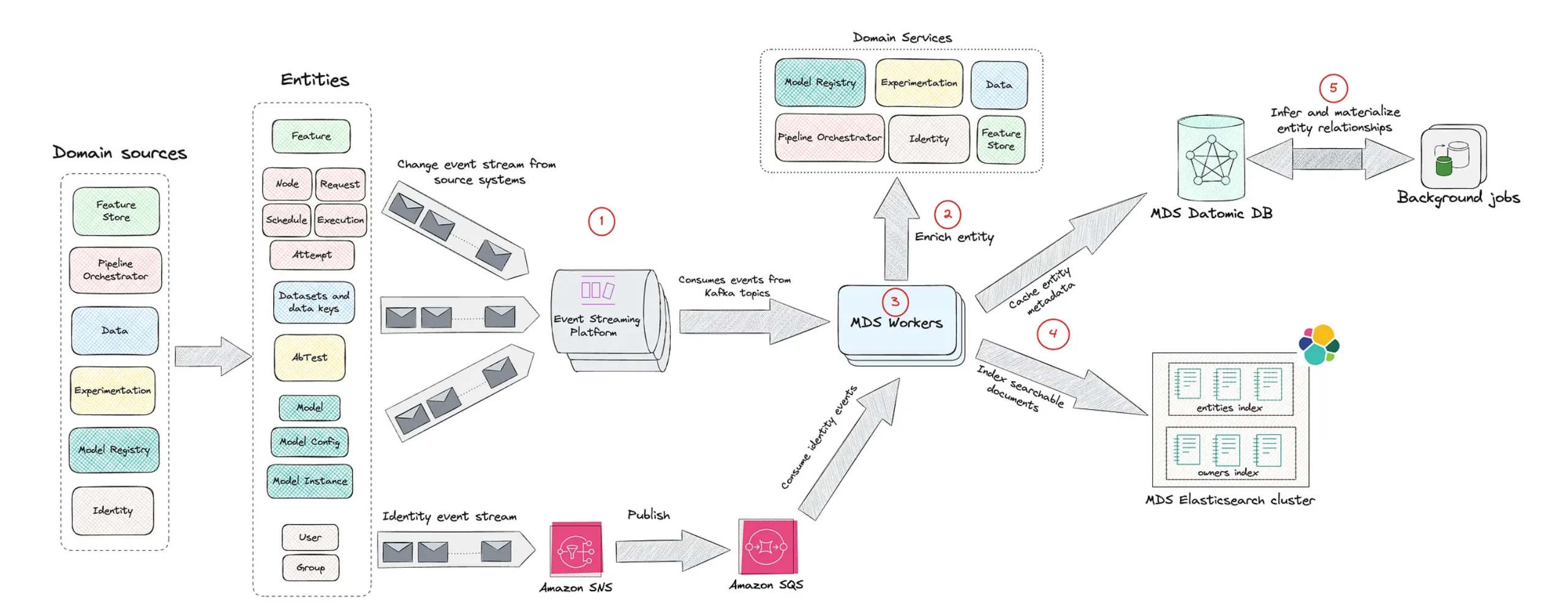
A Graph of Datasets, Features, Models, and Services
The Model Lifecycle Graph represents ML entities as nodes and their interdependencies as edges, replacing linear pipeline views with a connected map of relationships. Datasets, feature sets, models, evaluation runs, workflows, and production systems all appear as graph nodes. Edges describe how a model consumes features, which datasets feed those features, which workflows produced them, and which services ultimately depend on the model’s predictions. This graph-based perspective allows engineers to traverse lineage chains end-to-end, from raw data through model deployment. It also clarifies how independently evolving components interact over time, a critical challenge in enterprise ML systems where changes are constant. By making these dependencies traversable and queryable, the graph underpins more robust ML scaling architecture: teams can reason about the impact of schema changes, identify shared assets, and understand how experimental models relate to production services without relying on tribal knowledge or scattered documentation.
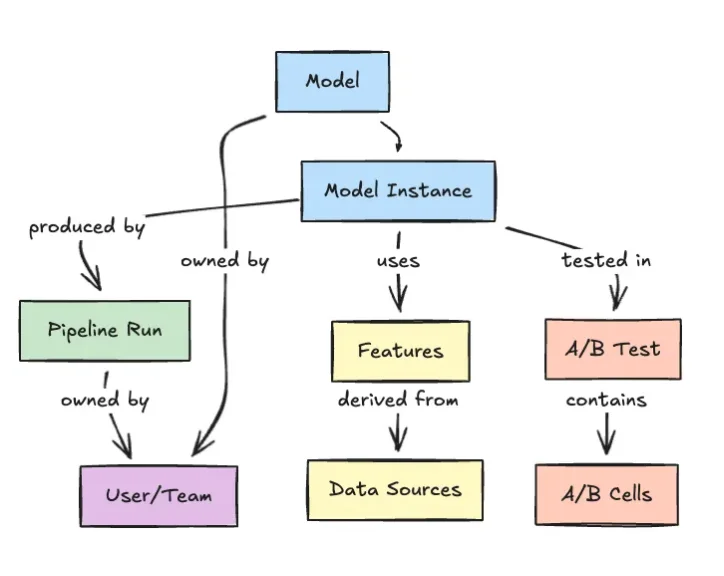
Improving Discoverability, Reuse, and Machine Learning Governance
Beyond dependency mapping, Netflix positions the Model Lifecycle Graph as a foundation for discoverability and machine learning governance. Because every dataset, feature, model, and workflow is represented in a unified graph, teams can search for existing assets, inspect how they are constructed, and see where they are used. This encourages reuse of proven components—such as shared feature sets—rather than repeatedly rebuilding similar logic. At the same time, the graph encodes ownership and operational context, clarifying who maintains which assets and how they are evaluated. That visibility is crucial for governance: it becomes easier to trace the lineage of a model back to its training data, understand evaluation setups, and audit how models propagate into production systems. As organizations embed ML more deeply into business-critical applications, Netflix’s approach suggests that rigorous model lifecycle management and governance must be baked into the architecture, not bolted on later.
Democratizing Enterprise ML Through Self-Service Graphs
Netflix frames the Model Lifecycle Graph as a step toward democratizing ML internally. Rather than concentrating knowledge within a central platform team, the graph enables engineers and data scientists across the organization to self-serve: they can independently discover datasets, understand upstream and downstream dependencies, and plug into existing workflows. This reduces duplicated work while promoting consistent practices around feature reuse, evaluation, and deployment. It also aligns with broader industry trends toward metadata-centric platforms, such as LinkedIn’s DataHub or lineage-focused initiatives like OpenLineage, where graph-based representations underpin internal developer portals and ML platforms. For Netflix, the emphasis is less on flashy new orchestration tools and more on traceability, dependency mapping, and institutional visibility. As enterprise ML systems expand, their experience underscores a key lesson: sustainable ML scaling architecture depends on treating metadata, lineage, and lifecycle governance as core design concerns, with graph-based models providing a natural structural backbone.