AI Coding Agents Are Colliding with Developer Tool Pricing
AI coding agents are software assistants that combine large language models, tooling integrations, and workflow logic to read codebases, plan changes, run commands, and generate code in multi-step development sessions while aiming to reduce repetitive manual work across repositories and terminals. Within 72 hours, Cursor, Anthropic, and Alibaba each shifted this category by pairing new coding agent features with lower effective price floors. Cursor’s Composer 2.5 pushed proprietary coding capability toward cheaper per-task economics, while Anthropic’s Claude Managed Agents expanded where and how agents can run inside customer environments. Alibaba’s Qwen 3.7 Max API added another high-end model choice to the mix. At the same time, DeepSeek-native tools such as Reasonix show how cache-first designs compete on API cost reduction rather than headline model size. For developers, the market is no longer about access alone; it is about the tradeoff between capability, control, and developer tool pricing.
Cursor’s Composer 2.5 Targets Cost per Coding Task
Cursor’s Composer 2.5 puts pricing and performance at the center of the AI coding agents race. Built on the open-source Kimi K2.5 base and trained on 25 times as many synthetic coding tasks as its March predecessor, the model is designed to push more work per dollar. The standard tier is priced at USD 0.50 (approx. RM2.30) per million input tokens and USD 2.50 (approx. RM11.50) per million output tokens, with a faster variant at USD 3.00 (approx. RM13.80) input and USD 15.00 (approx. RM69.00) output. According to Developer-Tech, “Composer 2.5 scores around 63% accuracy at roughly USD 0.50 (approx. RM2.30) per task, while Claude Opus 4.7 at its default setting scores comparably at approximately USD 7 (approx. RM32.20) per task.” Even if independent tests adjust these numbers, the gap pressures rivals to rethink their developer tool pricing.
Anthropic and Alibaba Push Enterprise and Model Choice, Not Just Price
Anthropic’s Code with Claude London announcements show that capabilities around control and data perimeter are becoming as important as raw model strength. Self-hosted sandboxes, now in public beta, let Claude Managed Agents execute tools, run code, and write files inside a customer’s own infrastructure while Anthropic keeps the orchestration loop. MCP tunnels, in research preview, route encrypted traffic through a lightweight gateway so agents can call private systems without public endpoints. Both features are experimental, but they narrow a long-standing gap for teams that want agents near sensitive systems. Alibaba’s Qwen 3.7 Max API, released through Alibaba Cloud Model Studio, adds another high-end model option for developers who want a broad model portfolio rather than a single vendor dependency. Together, these moves show that competitive pressure is widening from headline benchmarks to deployment models, internal connectivity, and long-run ownership costs.
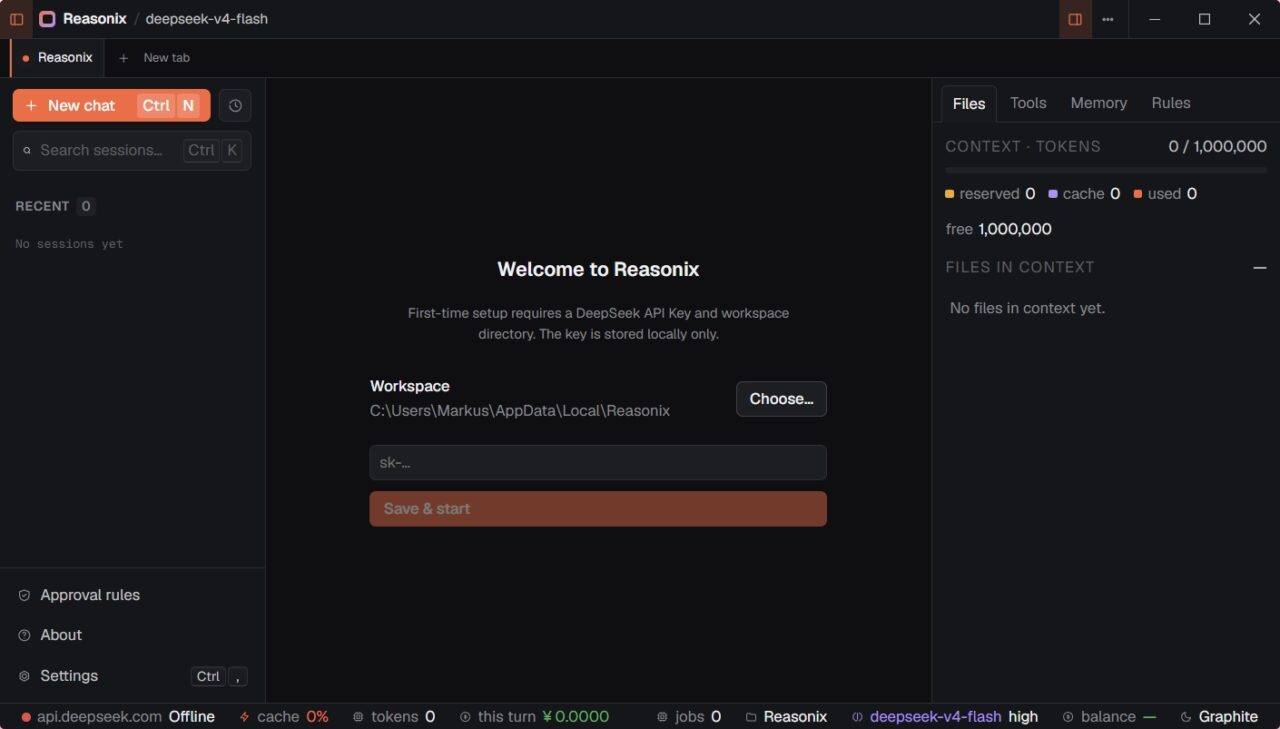
Reasonix and DeepSeek Prefix Caching Shift Focus to API Cost Reduction
Reasonix highlights another front in the AI coding agents race: making long-running workflows cheaper rather than chasing the largest model. The open-source, terminal-first assistant is built as a DeepSeek-native AI coding agent that uses prefix caching to avoid reprocessing unchanged context in extended shell sessions. The project targets developers who keep reusing the same repository context and commands, where token waste adds up quickly. In the project’s own single-day study on May 1, 2026, active use cost about USD 12 (approx. RM55.20) instead of about USD 61 (approx. RM280.60), though those savings are still self-reported. Reasonix combines MCP support, plan mode, and a cache-first loop under an MIT license, making it appealing to teams that want to tune and extend their own stack. For workflows that stay inside one long session, cache-first design becomes a direct API cost reduction strategy rather than a niche optimization.
Choosing Between Agents: Pricing Tiers, Features, and Workflows
For developers, the wave of releases from Cursor, Anthropic, Alibaba, and DeepSeek-native tools forces more careful cost-benefit analysis. Composer 2.5’s low per-token rates appeal to those who want frontier-level coding help at a lower effective price per task. Anthropic’s self-hosted sandboxes and MCP tunnels target teams that value control over where tools run and how agents reach internal systems, even if features remain in beta. Alibaba’s Qwen 3.7 Max API expands choice for teams building multi-model backends. Reasonix shows how a cache-first loop and plan mode can trim repeated-token spending in long terminal workflows. Developers need to map these coding agent features against specific use cases: dense, time-boxed tasks versus long sessions, strict infrastructure boundaries versus cloud-managed convenience, open-source extensibility versus integrated platforms. The most cost-effective option is less about a universal “best agent” and more about aligning pricing tiers and capabilities with the real shape of daily coding work.





