
From Chatbots to Real-Time Voice APIs
OpenAI’s latest release is a clear signal: voice is becoming a first-class interface for apps and workflows. The company has added three new low-latency audio models to its real-time voice API: GPT-Realtime-2, GPT-Realtime-Translate, and GPT-Realtime-Whisper. Together, they target production-grade voice agent development, live translation AI, and streaming transcription rather than simple, linear chat. Instead of waiting for users to finish speaking, these models are built to respond as audio arrives, making it possible to build assistants that feel conversational and responsive. They can reason through complex tasks, keep up with fast speakers, and transcribe speech continuously. For developers, this means you can now wire voice directly into business workflows: routing customer calls, driving voice-to-action flows in apps, or powering system-to-voice alerts that speak to users based on live data. Voice AI is no longer a demo feature; it’s becoming an operational layer.

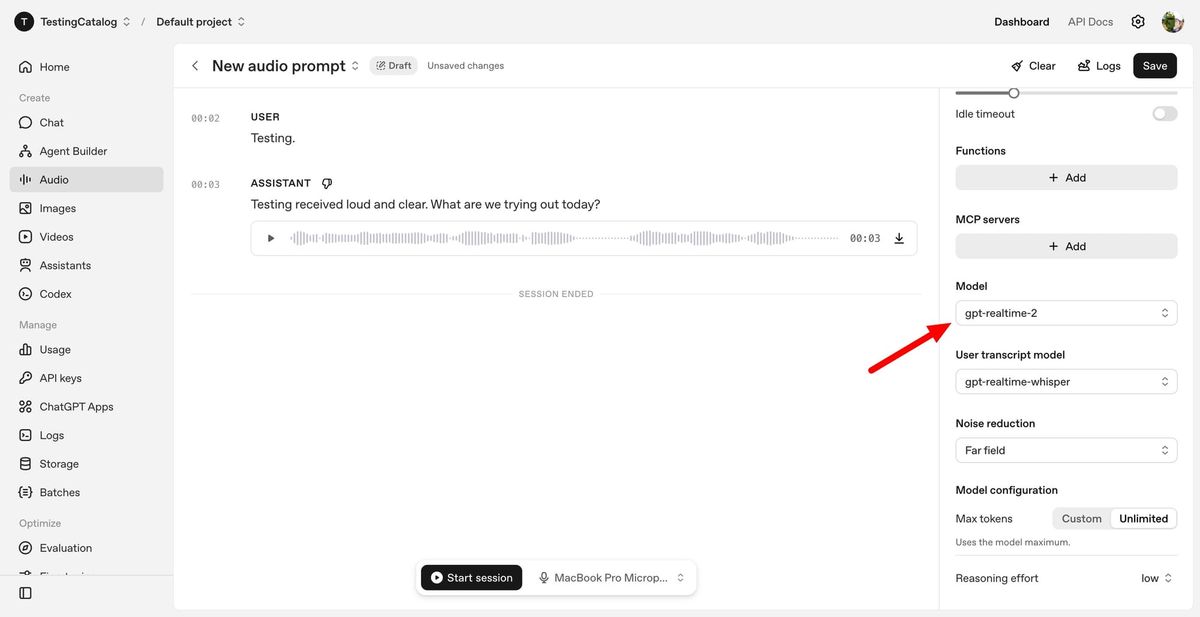
GPT-Realtime-2: The Core Engine for Voice Agents
GPT-Realtime-2 is the flagship model for spoken interaction and the centerpiece of the new real-time voice API. Built with GPT-5-class reasoning, it is designed for live conversations where users interrupt, correct themselves, and change direction mid-task. The model can manage context over a 128K token window, a jump from the previous 32K, allowing your voice agents to remember longer sessions, multi-step workflows, and detailed user preferences. For developers, the crucial feature is controllable reasoning effort. You can tune the model from minimal to xhigh reasoning, trading off latency against depth of analysis depending on the use case. In practice, that lets you favor low-latency responses for lightweight queries and dial up deeper reasoning for complex voice-driven workflows. Support for short spoken preambles like “let me check that,” parallel tool calls, and explicit verbal error recovery makes agents feel less brittle and more like capable, guided assistants.
GPT-Realtime-Translate: Live Translation AI for Multilingual Voice Apps
GPT-Realtime-Translate is built for live multilingual conversations, enabling developers to add live translation AI directly into voice products. It supports speech input in over 70 languages and output in 13 languages, keeping pace with speakers even when they talk quickly, shift topics, or use domain-specific terms. This is crucial for contact centers, cross-border sales teams, education platforms, and live events where latency must stay low and meaning cannot be lost. Beyond basic text output, the model can provide real-time translations alongside transcripts, making it suitable for scenarios such as bilingual customer support or live-localized video streams. Early experiments from companies in telecom and media show how you can overlay live translations on top of existing audio experiences. For developers, this means you can build voice-to-voice flows—where each participant speaks their native language—without resorting to batch translation or separate localized content pipelines.
GPT-Realtime-Whisper: Streaming Transcription for Voice-Driven Workflows
GPT-Realtime-Whisper brings streaming transcription to the API, letting you convert speech to text as it happens instead of waiting for full recordings. This low-latency model is a fit for live captions, meeting notes, and any workflow where you want to trigger actions based on what is being said right now. Because it processes audio incrementally, you can drive real-time voice dashboards, highlight extraction, or downstream automations that react mid-conversation. In a production environment, streaming transcription unlocks new patterns: voice-to-action flows where spoken instructions immediately update CRM entries, ticketing systems, or internal tools; or system-to-voice loops where recognized phrases prompt contextual spoken responses. Combined with GPT-Realtime-2, you can move beyond simple dictation and build voice interfaces that both understand and act. The result is a foundation for robust voice agent development that integrates smoothly into existing business systems.
Designing and Integrating Production-Ready Voice Experiences
To bring these models into production, treat them as infrastructure for real-time voice rather than isolated chatbots. Start by choosing the right combination: GPT-Realtime-Whisper for streaming transcription, GPT-Realtime-Translate for multilingual flows, and GPT-Realtime-2 for reasoning and orchestration. Architect your system so audio is ingested, transcribed, and passed to your business logic or tools while responses are streamed back as synthesized speech. For low-latency voice agent development, pay attention to reasoning levels, timeouts, and tool-call patterns. Use lower reasoning for quick replies and higher settings where correctness matters more than speed. Design conversational states that can handle interruptions and corrections gracefully, leveraging the models’ improved context management and error recovery cues. Finally, monitor latency and turn-taking behavior in real-world traffic; voice interfaces succeed when they feel natural, fast, and reliable enough to handle everyday business workflows without human intervention.