
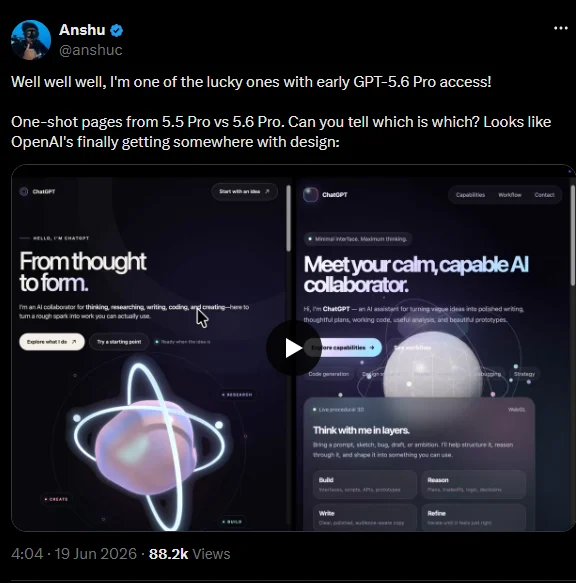
What GPT-5.6 Is—and Why This Leak Matters
GPT-5.6 is a rumored next-generation OpenAI language model with three tiers, a reported 1.5 million token context window, and major gains in reasoning and coding aimed at long, complex tasks that current GPT-5.5 systems struggle to handle.
If these leaks hold, GPT-5.6 is less a routine upgrade and more a strategic reset of how large models are packaged, priced, and used. Reports say OpenAI may launch it as early as next week, with some rumors pointing to June 25 and suggesting it is already being quietly tested through GPT-5.5 Pro sessions. In other words, some developers might already be using GPT-5.6 without knowing it. That stealth approach is smart: real workloads are the best way to tune a model that claims better AI reasoning performance, coding reliability, and long-context understanding.
The main takeaway: if GPT-4 was about getting a good assistant, GPT-5.6 looks aimed at becoming an actual teammate for complex projects.

Three OpenAI Model Tiers: Mini, Standard, Pro
The most striking business move in the GPT-5.6 release rumors is the three-tier lineup: GPT-5.6 Mini, Standard, and Pro. This is not just branding; it signals a deliberate push toward matching different performance levels—and likely prices—to specific workloads and budgets. Mini will almost certainly target lightweight tasks and cost-sensitive users, Standard will be the default workhorse, and Pro will be the high-gear engine for demanding developers and enterprises.
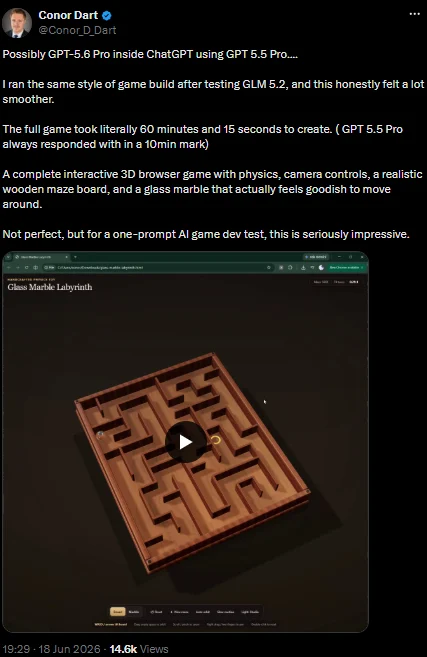
Functionally, this tiering is OpenAI’s answer to the reality that not every chat, script, or app needs the strongest model, but serious coding and agent tasks absolutely do. Testers already report that the newer model produces stronger first attempts and needs fewer corrections compared to existing GPT-5.5 variants, even when surfaced behind a GPT-5.5 Pro label. In plain terms: Pro looks like a stealth upgrade meant to prove its value before OpenAI announces any pricing shifts.
Given rising competition and pressure on token costs, this three-tier approach is how OpenAI keeps premium performance without scaring away smaller teams.
The 1.5M Token Context Window Is the Real Breakthrough
The headline spec is the rumored jump from a 1 million token context window to 1.5 million tokens. That might sound abstract, but it transforms what developers and users can do in a single request. A 1.5M-token context window means GPT-5.6 can keep far more of a project in “working memory” at once: whole codebases, book-length documents, long-running conversations, or multi-file research projects.
This is the first time the promise of ‘load the entire repo and reason about it’ starts to look practical instead of aspirational. Reports suggest that with this expanded token context window, GPT-5.6 can process larger codebases, longer conversations, extensive research documents, and complex workflows in a single session without constant re-uploading or manual summarizing. That matters not only for convenience but for correctness: less chopping and summarizing means fewer chances to lose nuance or context along the way.
If this spec ships as rumored, long-context AI stops being a demo feature and becomes a daily tool for serious engineering and research.

Reasoning, Coding, and the Trade-Off with Speed
Under the hood, GPT-5.6 appears to aim squarely at past weaknesses in logic-heavy tasks and software engineering workflows. Early feedback says it better understands complex instructions, plans multi-step tasks, and solves difficult problems with fewer mistakes. Reports even mention a bump in an internal “Juice Value” parameter from 768 to 960, suggesting more internal compute devoted to reasoning per request.
For developers, the claimed improvements are concrete: better code understanding, stronger planning, and more reliable execution across multi-step development tasks, including agent-based coding workflows and software benchmarks. Testers say projects that once needed multiple revisions and 20–40 minutes of back-and-forth can now be completed more efficiently. In return, responses often arrive slower; users report the model spends more time “thinking” before replying, and some note that the delay is offset by higher-quality outputs that need fewer corrections.
The real bet here is clear: OpenAI is prioritizing quality over raw speed, and for serious work that looks like the right decision.
What Comes Next for GPT-5.6 and Its Users
The latest wave of rumors started because many ChatGPT users noticed the system suddenly felt smarter in reasoning, coding, and creative tasks, and some testers believe this is due to stealth A/B testing of GPT-5.6 through GPT-5.5 Pro. Several rumors point to June 25 as a possible launch date, but OpenAI has not confirmed the model, its specs, pricing, or release schedule.
This uncertainty sits within an intense race in AI, where rival models are pushing coding and agent capabilities and token costs are under pressure. If the leaks prove accurate, GPT-5.6’s combination of a 1.5M-token context window, three OpenAI model tiers, and stronger AI reasoning performance could be a decisive move for developers and enterprises. For everyday users, it likely means smarter responses, better context awareness, and fewer corrections—at the cost of waiting a bit longer for complex answers.
Until the announcement lands, the rational stance is cautious optimism: plan for GPT-5.6 by designing workflows around long-context and slower, higher-quality responses—but do not rewrite your stack based on rumors alone.





