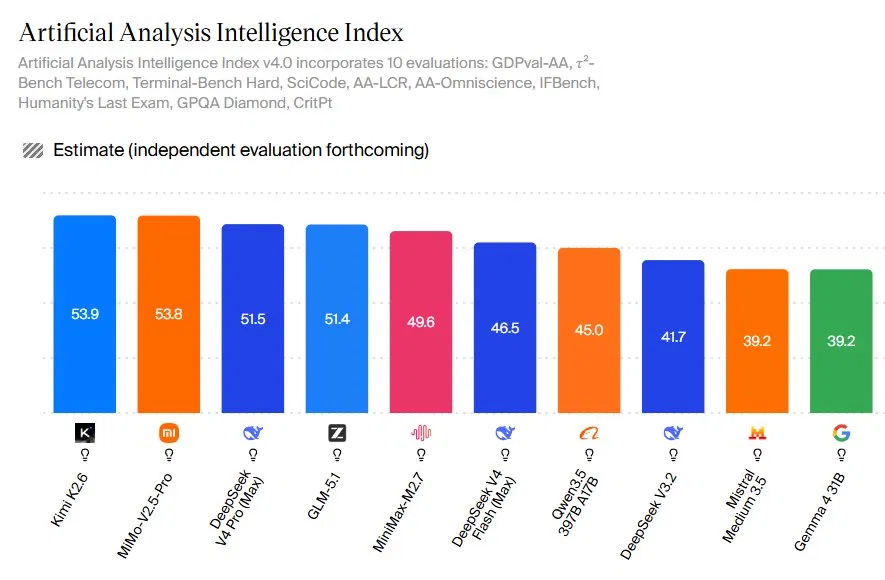
What It Means for Open-Source AI to Match Frontier Models
Open source AI models are publicly released neural networks whose weights and usage rights are available to developers, enabling them to self-host, customize, and integrate high-level AI capabilities without relying on a single vendor. In specific workloads, these models now reach or approach the quality of top proprietary frontier systems. The Artificial Analysis Intelligence Index v4.0 scores models across 10 evaluations that cover reasoning, coding, agent-style tasks, and knowledge, and the current open-source leaderboard shows how far they have come. Kimi K2.6 tops the chart with a score of 53.9, followed closely by MiniMax’s MMo‑V2.5‑Pro at 53.8. DeepSeek V4 Pro, GLM‑5.1, and other leaders sit only a few months behind the highest-end commercial APIs, making open-source a realistic choice for targeted, production workloads rather than an experimental fallback.
Frontier-Level Performance: Where Open-Source Now Competes
For many developers, the main question in AI model comparison is no longer “can open-source compete?” but “on which tasks does it win?”. DeepSeek V4 Pro, a 1.6 trillion-parameter Mixture-of-Experts model with 49B active parameters, leads all tested models on coding with a Codeforces rating of 3206, ahead of GPT‑5.4 and Gemini‑3.1‑Pro. Moonshot AI’s Kimi K2.6 shows standout agent behavior: Vercel reported over 50% improvement on its Next.js benchmark versus K2.5, and the model refactored an 8‑year‑old financial matching engine over 13 hours using more than 1,000 tool calls. GLM‑5.1 reaches the highest Agentic Index among open weights at 63, with a 56 percentage‑point reduction in hallucination rate. These figures show that, for coding, long-horizon agents, and instruction following, frontier model alternatives in open-source can already match or exceed many closed systems.
Cost Effective AI: When Open-Source Wins on Budget
Performance alone does not decide which open source AI models to use; cost effective AI is often the real tie-breaker. DeepSeek V4 Flash illustrates this clearly: at 284B total parameters with 13B active, it is designed as an efficiency-focused alternative to V4 Pro, scoring 46.5 on the Intelligence Index while being significantly faster and cheaper to run. According to the benchmark suite, “Flash comes in at USD 113 (approx. RM520) to run the full Intelligence Index benchmark suite, versus USD 1,071 (approx. RM4,940) for V4 Pro.” DeepSeek V3.2 is even cheaper at USD 71 (approx. RM330) for the same suite. These concrete numbers show why many engineering teams now treat open models as the default choice: they can self-host, scale, and tune without paying premium API rates for every experiment or workload spike.
Choosing the Right Model for Your Use Case
Selecting frontier model alternatives starts with a clear view of your primary workload. For long-context agents and complex tool use, Kimi K2.6, MMo‑V2.5‑Pro, and MiniMax‑M2.7 are attractive, since they specialize in agent tasks and long-horizon toolchains that include shells, browsers, retrieval, and code. If coding is central, DeepSeek V4 Pro offers top-tier programming performance, while DeepSeek V4 Flash and V3.2 trade some peak capability for lower cost and faster inference. Qwen 3.5 39B A1TB stands out for instruction following; its wider family has been taking market share on platforms such as OpenRouter, and the flagship variant is Apache 2.0, easing commercial deployment. Mistral Medium 3.5 and Gemma 4 31B provide lighter options for teams that value self-deployable, efficient models, including multimodal support in Gemma’s case, and want to run AI on more modest hardware.
How to Use Benchmarks to Compare Open and Proprietary Models
To compare open-source AI models with proprietary APIs, start with published benchmarks that align with your tasks. The Artificial Analysis Intelligence Index v4.0 offers a single score across 10 evaluations, but the sub-scores for reasoning, coding, and agentic behavior are often more useful for real deployments. GLM‑5.1, for example, pairs a 51.4 overall score with the highest Agentic Index among open-weight models, while Qwen 3.5 scores 76.5 on IFBench, beating GPT‑5.2 on instruction following. Use these numbers as a filter, then validate with your own evaluation sets that mirror your prompts, tools, and latency constraints. Finally, factor in licensing: Apache 2.0 models such as the Qwen 3.5 flagship simplify on-premise and commercial use, turning high-benchmark scores into practical, long-term frontier model alternatives.





