
From Pipeline Sprawl to Graph-Native Machine Learning Infrastructure
As enterprise ML systems mature, organizations amass sprawling collections of datasets, models, features, experiments, and serving endpoints. Traditional pipeline-centric tooling often treats these as isolated artifacts, making it hard to answer basic questions: where did this model come from, which datasets does it rely on, and what breaks if an upstream table changes? Netflix’s Model Lifecycle Graph responds to this scaling pain by elevating metadata to a first-class concern. Instead of viewing ML production scaling as merely adding more compute, the company reframes it as a problem of modeling relationships. By capturing machine learning infrastructure as a web of interconnected entities, Netflix aims to improve discoverability, governance, and reuse. This graph-centric mindset aligns with a broader industry shift toward metadata-driven model lifecycle management, where understanding context and lineage is just as critical as optimizing training jobs or inference throughput.
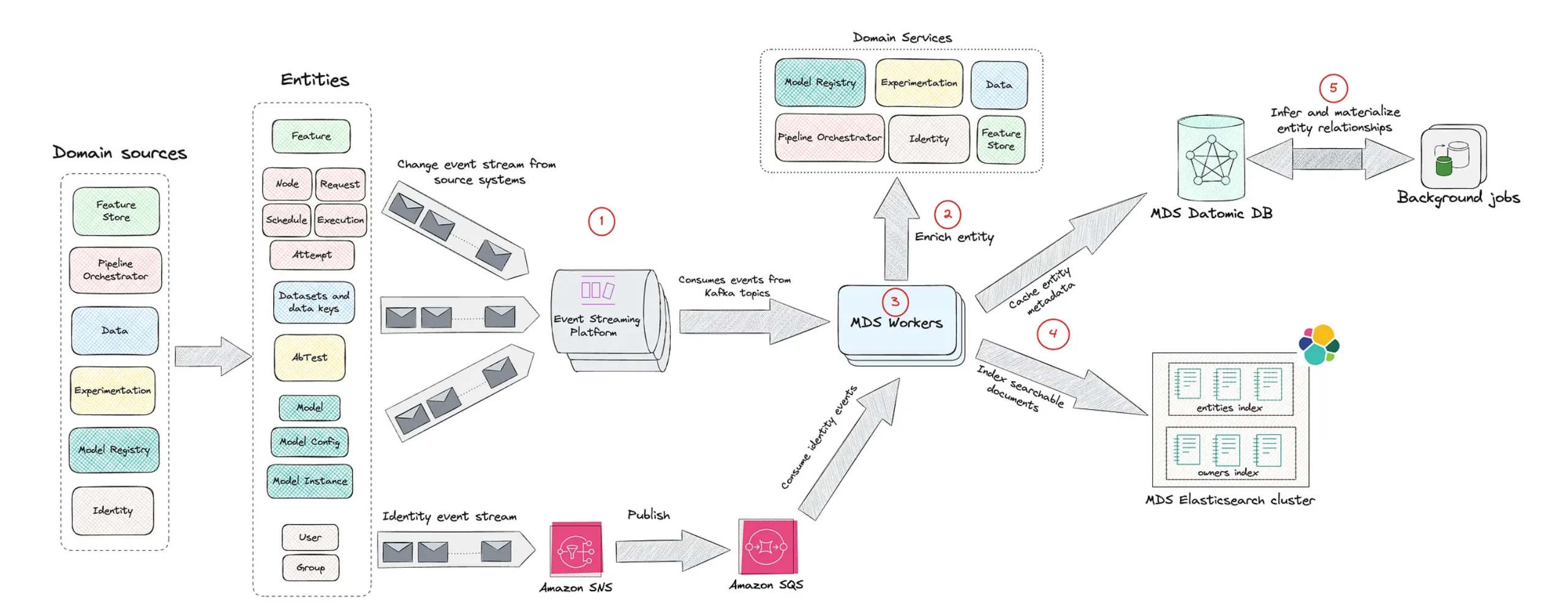
Inside Netflix’s Model Lifecycle Graph: Nodes, Edges, and Lineage
Netflix’s Model Lifecycle Graph represents ML assets—datasets, features, models, evaluations, workflows, and production services—as nodes, with edges describing how they depend on or feed into one another. This turns what used to be a set of disconnected pipeline stages into a navigable graph of enterprise ML systems. Engineers can traverse upstream to see which raw data or feature pipelines a model depends on, or downstream to learn which workflows and applications consume its predictions. This representation makes impact analysis far more precise: a planned schema change on a dataset node immediately reveals affected models and services. It also boosts reuse, as teams can discover existing features or evaluation workflows by exploring graph neighborhoods instead of rebuilding components from scratch. In effect, the graph becomes a living, organization-wide map of model lifecycle management, capturing how ML assets evolve and interact over time.
Solving Lineage, Dependency, and Workflow Challenges at Enterprise Scale
At scale, enterprise ML systems rarely fail because a single model is misconfigured; they fail because complex, loosely coupled dependencies are opaque. Netflix’s graph-based architecture tackles recurring production challenges by making these relationships explicit. Model lineage becomes a query instead of an investigation: teams can trace a deployed model back through training workflows, evaluation runs, feature definitions, and raw datasets in one connected view. Dependency management also improves, since shared features or datasets appear as hub nodes whose downstream consumers are easy to enumerate and notify before changes. Workflow coordination benefits as well, because scheduling, retraining, and rollout pipelines can be reasoned about in terms of graph paths rather than ad hoc documentation. Combined, these capabilities reduce surprise regressions, shorten incident resolution times, and allow ML production scaling to proceed without losing control over governance, compliance, and reliability.
Superhuman and Databricks: A Case Study in High-Throughput Inference
While Netflix focuses on modeling relationships, the Superhuman–Databricks collaboration highlights the serving side of machine learning infrastructure. Superhuman runs a custom large language model that powers real-time grammar correction for over 40 million daily users. The model handles more than 200,000 queries per second, each with roughly 50 input and 50 output tokens, while maintaining end-to-end latency under one second at P99 and stringent reliability guarantees. After outgrowing a DIY stack based on vLLM, Superhuman adopted Databricks model serving to modernize its platform. Joint engineering work introduced a custom load balancer using the “power of two choices” algorithm, aggressive yet stable autoscaling based on per-pod concurrency, and image acceleration techniques that cut pod startup times via lazy-loading container images. Together, these optimizations demonstrate what robust, production-grade ML infrastructure looks like when model lifecycle management is paired with finely tuned, high-throughput inference systems.