From Model Size to Workflow: A New Era for Efficient AI Agents
Efficient AI agents are intelligent systems that complete multi-step tasks by combining small language models with tools, code, and structured workflows instead of relying on a single large model’s raw knowledge. This shift is changing how teams think about performance: orchestration and runtime design now matter more than scale. Microsoft’s MagenticLite, for example, runs across the browser and local file system in one workflow using purpose-built small models, MagenticBrain for reasoning and Fara1.5 for computer-use tasks. The research bet behind MagenticLite is that “agentic capability depends on tool orchestration and action rather than knowledge alone,” allowing lighter models to stay efficient and keep data on the user’s machine. For edge AI deployment and privacy-sensitive scenarios, these lightweight AI systems point to agents that can run directly on local hardware without constant calls to giant cloud models.

MagenticLite: Small Language Models, Big Agentic Workloads
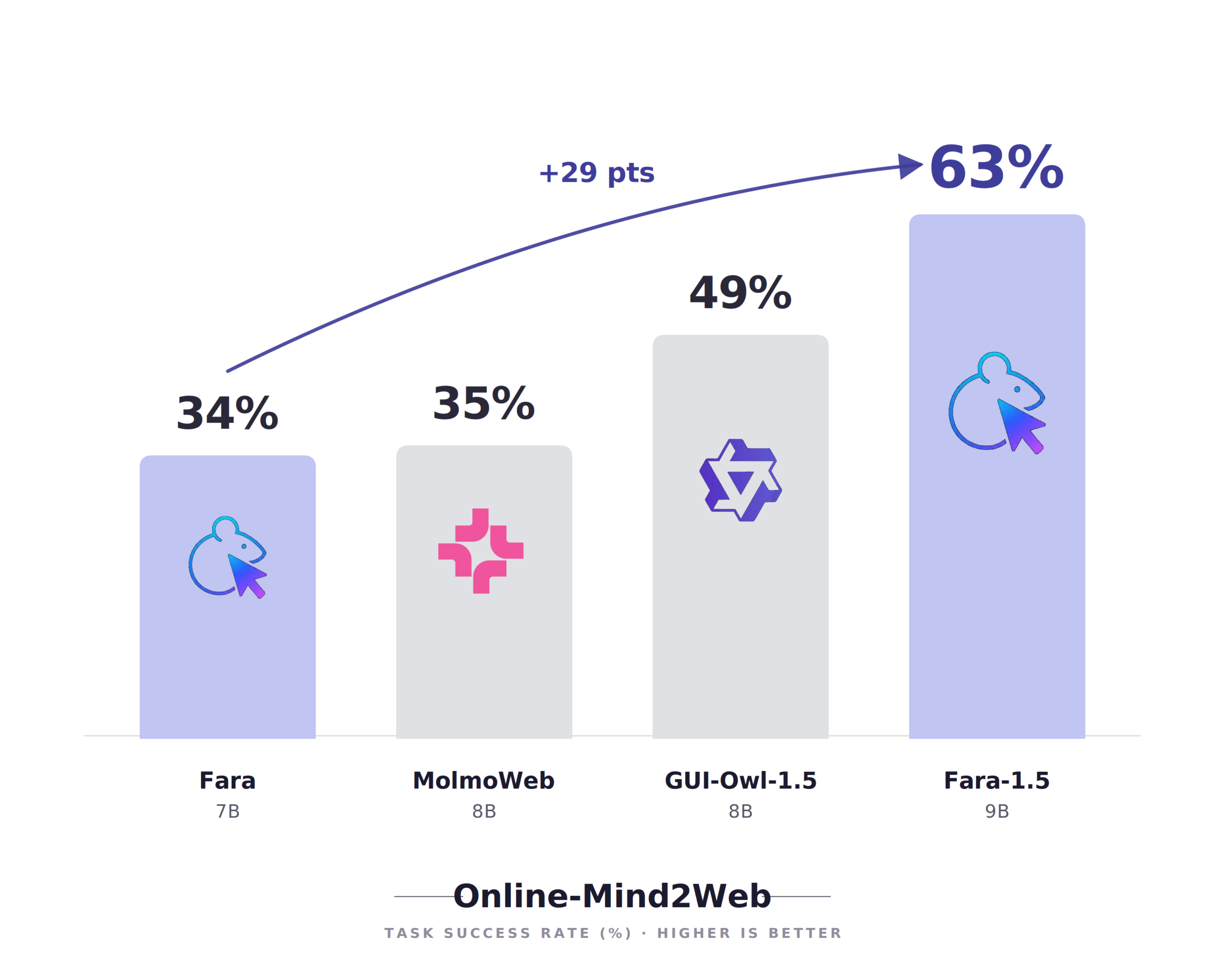
MagenticLite shows how small language models can drive capable, efficient AI agents when the app, models, and harness are designed together. MagenticBrain acts as planner, coder, and delegator, turning vague requests into concrete plans, picking the right tool or sub-agent, writing code, and recovering when tasks fail. Fara1.5, a computer-use model family with a flagship 9-billion-parameter variant, focuses on browser tasks such as filling forms and handling credentialed sites and long-running activity. On the OnlineMind2Web benchmark, Fara‑1.5‑9B achieves state-of-the-art results among models in its size class and nearly doubles the earlier Fara‑7B’s web navigation performance. This system-level design keeps workflows on the local file system, reinforces human oversight through explicit approvals, and highlights how agent orchestration can stretch small models much further than raw parameter counts suggest.
Webwright: Turning Browser Workflows into Rerunnable Code
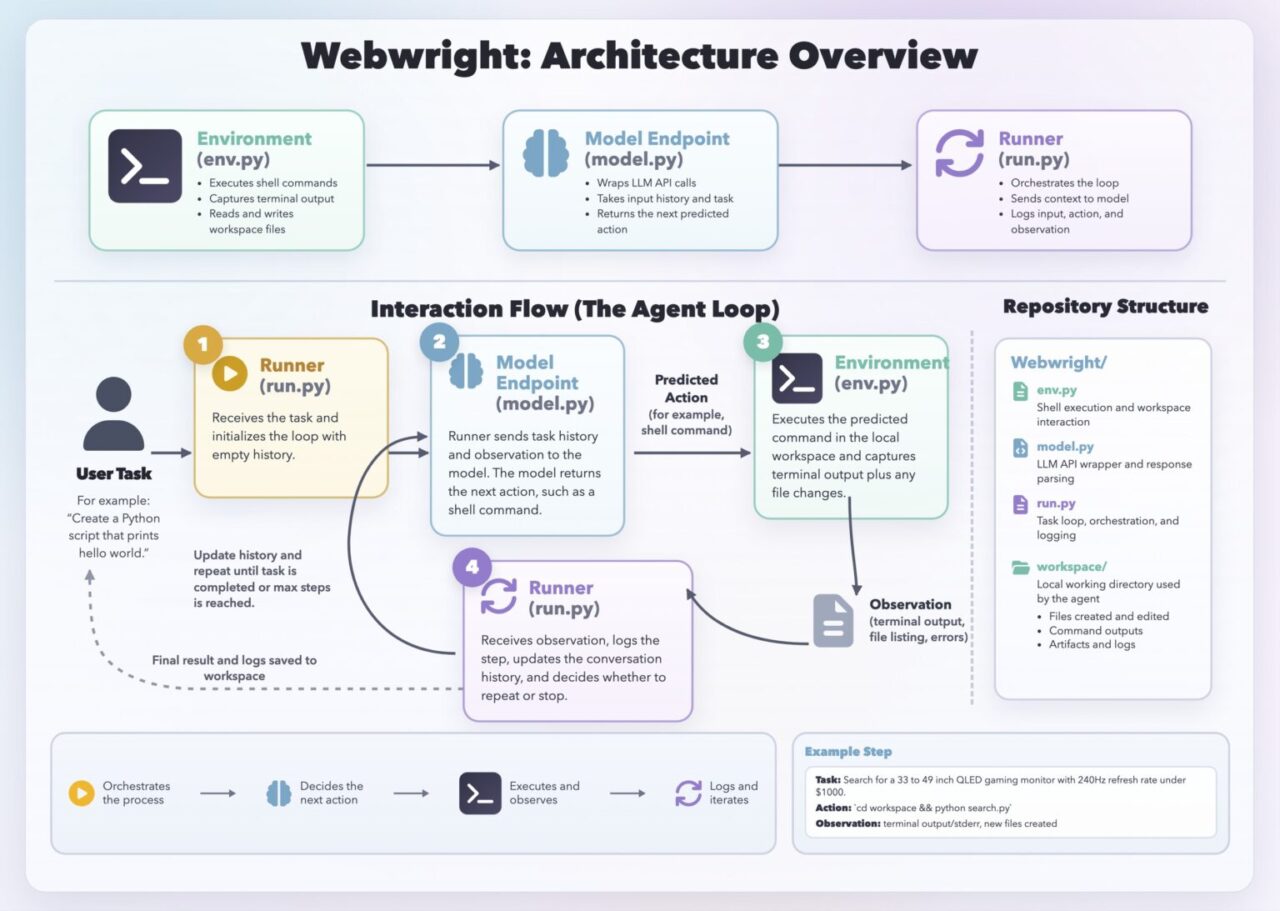
Microsoft’s Webwright framework pushes efficient AI agents further by converting browser interaction into rerunnable code. Instead of tying progress to an opaque browser session, Webwright represents an agent’s work as Playwright scripts, bash commands, saved files, logs, and screenshots in a terminal workspace. When a task fails, developers rerun and debug that code rather than reconstruct a workflow from scratch, improving reliability and shortening iteration cycles. According to Microsoft, Webwright reaches 60.1% on the Odysseys benchmark, a 26.6-point gain over a base GPT‑5.4 score of 33.5%. This performance lift comes from workflow design, not bigger models. By treating the browser as a controllable environment from the command line, Webwright makes agent orchestration explicit, testable, and versionable—qualities that matter more than model size when building dependable automation for complex web tasks.
Managed Runtimes: Infrastructure Becomes the Quiet Differentiator
While small language models and local-first designs grab attention, the most significant shift in agent tooling is arguably managed runtimes. Google’s repositioning of Antigravity, Anthropic’s Claude Managed Agents, and AWS Bedrock AgentCore all share the same idea: move the agent loop, sandbox, state, and credential scoping into a managed service. Instead of hand-writing orchestration code, developers describe models, tools, and skills in configuration files like AGENTS.md and SKILL.md, then call a single API to run agents in a remote Linux sandbox. With three vendors shipping similar capabilities in six weeks, managed AI agent runtimes are turning into table stakes. The differentiator is no longer who has the largest model, but who provides the most reliable, flexible infrastructure for running teams of efficient AI agents in production without fragile, custom glue code.

Why Developers Now Care More About Workflows Than Model Size
Together, MagenticLite, Webwright, and the major cloud runtimes show a clear pattern: developers are optimising for workflow efficiency and deployment flexibility. Lightweight AI systems built around specialized, smaller models offer faster inference, lower latency, and reduced compute overhead, which matters for interactive agent experiences and edge AI deployment. Tool-aware orchestrators like MagenticBrain, browser specialists such as Fara1.5, and code-first frameworks like Webwright minimize wasted cycles by focusing each model on a narrow task and making every step reproducible. Managed runtimes from Google, Anthropic, and AWS further standardize the agent loop so teams can plug in different models as needs and costs change. As a result, the practical power of an AI agent now depends less on having the biggest model and more on having clear workflows, replayable automation, and infrastructure that gets out of the way.