What Gemini 3.5 Flash Is and Why Its Speed Leap Matters
Gemini 3.5 Flash is Google’s latest frontier-scale AI model that combines frontier-level reasoning with a four-times faster token output rate than rival models, making it a high-speed default engine for coding, multi-step agents, and consumer assistants across Google’s ecosystem. Built to remove the usual trade-off between latency and quality, it now powers the Gemini app and AI Mode in Google Search by default. Benchmarks show that it beats Gemini 3.1 Pro on agentic tasks such as long-horizon developer workflows, multi-step tool calls, and chart reasoning. According to the Artificial Analysis index, Gemini 3.5 Flash occupies the top-right quadrant where frontier intelligence meets high output speed. For users, that means fewer multi-second pauses when generating long documents or running complex workflows. For developers, it means faster AI inference at scale, with reduced fragility in pipelines that depend on tight response time budgets.
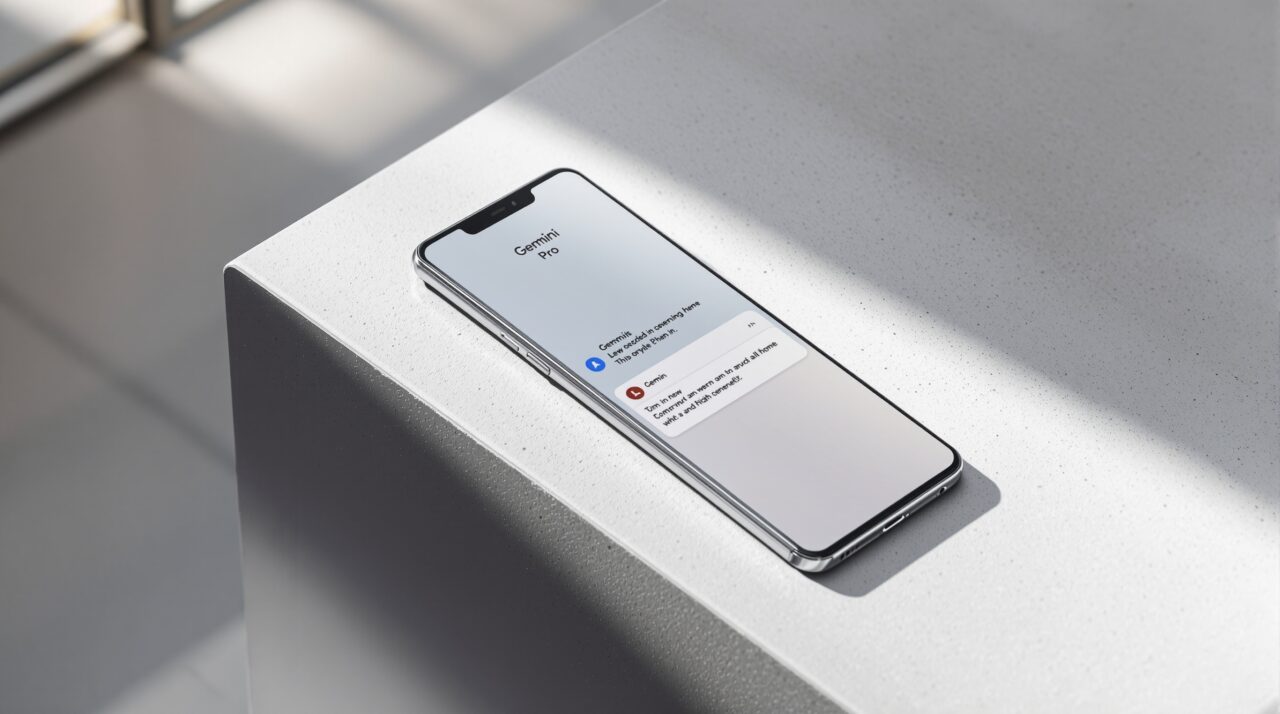
AI Model Performance Comparison: Benchmarks Behind the 4x Speed
Gemini 3.5 Flash’s speed story is backed by a broad AI model performance comparison rather than a single headline stat. Google reports that the model is 4x faster on output speed than other frontier models while still posting frontier-level scores. On Terminal-Bench 2.1, it reaches 76.2% for long-horizon command line tasks, and on GDPval-AA it scores 1656 Elo for agent decision quality. Its 83.6% on MCP Atlas highlights strong multi-step tool-calling and coordination, and 84.2% on CharXiv Reasoning shows solid chart and figure interpretation. This places 3.5 Flash in a rare position: high intelligence without sacrificing throughput. In practical terms, the model can build pages, summarize long documents, or orchestrate multiple subagents faster than competitors, narrowing the gap between prompt and response and making faster AI inference a baseline rather than a premium feature.
Speed in the Wild: From Gemini Spark to Enterprise Agents
The most visible impact of Gemini 3.5 Flash speed gains shows up in emerging agentic applications. Google is debuting Gemini Spark, a personal AI agent built on 3.5 Flash that runs in the background and acts on a user’s behalf under their direction. Because the agent depends on rapid decisions and follow-up actions, the 4x speed gain greatly reduces friction; the delay between recognizing a task and completing it shrinks. Enterprises are already building on this. Macquarie Bank is piloting workflows that process 100-plus page customer documents and output structured recommendations with low latency. Shopify is running parallel subagents for merchant growth forecasts across global markets, while Salesforce is integrating 3.5 Flash into Agentforce for multi-turn, multi-subagent automation. These examples show how faster output transforms agents from slow, batch-like tools into near real-time collaborators.
Gemini Rate Limits Reset and the Antigravity Performance Patch
Alongside the speed push, Google shipped a refined Gemini 3.5 Flash variant within the Antigravity platform and completely reset usage quotas for both free and paid developers. The reset followed problems with a prior “low-effort” variant that cut token consumption by about 45% but weakened output quality and structural consistency on complex analytical tasks. Varun Mohan, a director at Google DeepMind over Antigravity, said the updated model handles difficult reasoning and heavy workloads such as software programming more reliably. Google also clarified that the Low, Medium, and High effort categories are limited to Antigravity and will not appear as toggles in consumer products. The Gemini rate limits reset is framed as a courtesy, giving developers a clean slate to test the improved model while Google monitors feedback, including requests for a visual usage tracking bar to make quota consumption clearer.

How Faster AI Inference Changes Developer and User Workflows
A 4x boost in Gemini 3.5 Flash speed does more than shave seconds off casual chats; it reshapes how people design workflows. For everyday users, drafting long emails, reports, or code now feels closer to typing with autocomplete than waiting for a batch job. Long-form reasoning, document analysis, and multi-step planning complete earlier, encouraging more iterative interactions instead of one-off prompts. Developers gain even more. Lower latency per token lets them chain more steps in an agent without blowing through response time budgets, and it makes parallel subagents practical for real-time applications. Workflows that were previously scheduled, like document reviews or multi-market forecasts, can run interactively. As Gemini 3.5 Pro enters testing for deeper reasoning tasks, Flash’s speed sets a baseline: high-throughput, low-latency AI is becoming the default expectation, not an edge case.