
The Hidden Costs of Agentic AI: Tokens, Recompute and Sloppy Specs
As AI agents take on longer, multi-step tasks, their biggest costs are no longer just model size or headline benchmark scores. Teams now wrestle with three invisible drains: vague or contradictory specifications that send coding agents down the wrong path, chat-style context handling that reloads the same information in every call, and GPU clusters that repeatedly recompute work because they cannot share state efficiently. Together, these problems inflate AI inference costs, reduce token consumption efficiency, and erode GPU utilization efficiency. Analysts are increasingly calling for a shift from raw model performance to token economics, focusing on how systems retain, reuse, and synchronize context during inference. The latest wave of tooling—Amazon’s Kiro Requirements Analysis, OpenSquilla’s open-source agent runtime, and MinIO’s MemKV context store—attacks these structural issues directly, promising leaner token bills, fewer wasted GPU cycles, and more predictable cost envelopes for agentic AI at scale.
AWS Kiro: Proving Requirements Before Agents Write a Single Line of Code
Amazon Web Services is extending its Kiro AI coding tool with a Requirements Analysis feature that aims to cut waste before it even reaches the GPU. The system combines large language models with an SMT solver, translating natural-language software requirements into formal logic and then mathematically proving whether those requirements contain contradictions or gaps. In typical agent workflows, vague prompts lead to ambiguous plans, forcing coding agents to make hidden assumptions that developers only uncover after tokens have been spent generating and reviewing faulty code. By catching flawed specs upfront, Requirements Analysis helps teams avoid entire branches of wasted agent activity: no speculative implementations of incompatible requirements, fewer rework cycles, and tighter prompts that generate less slop. For organizations treating AI agent cost optimization as a design goal, this shift from post-hoc debugging to pre-flight verification directly reduces redundant processing and downstream token usage.
OpenSquilla: Routing, Caching and Four-Tier Memory to Reduce Token Consumption
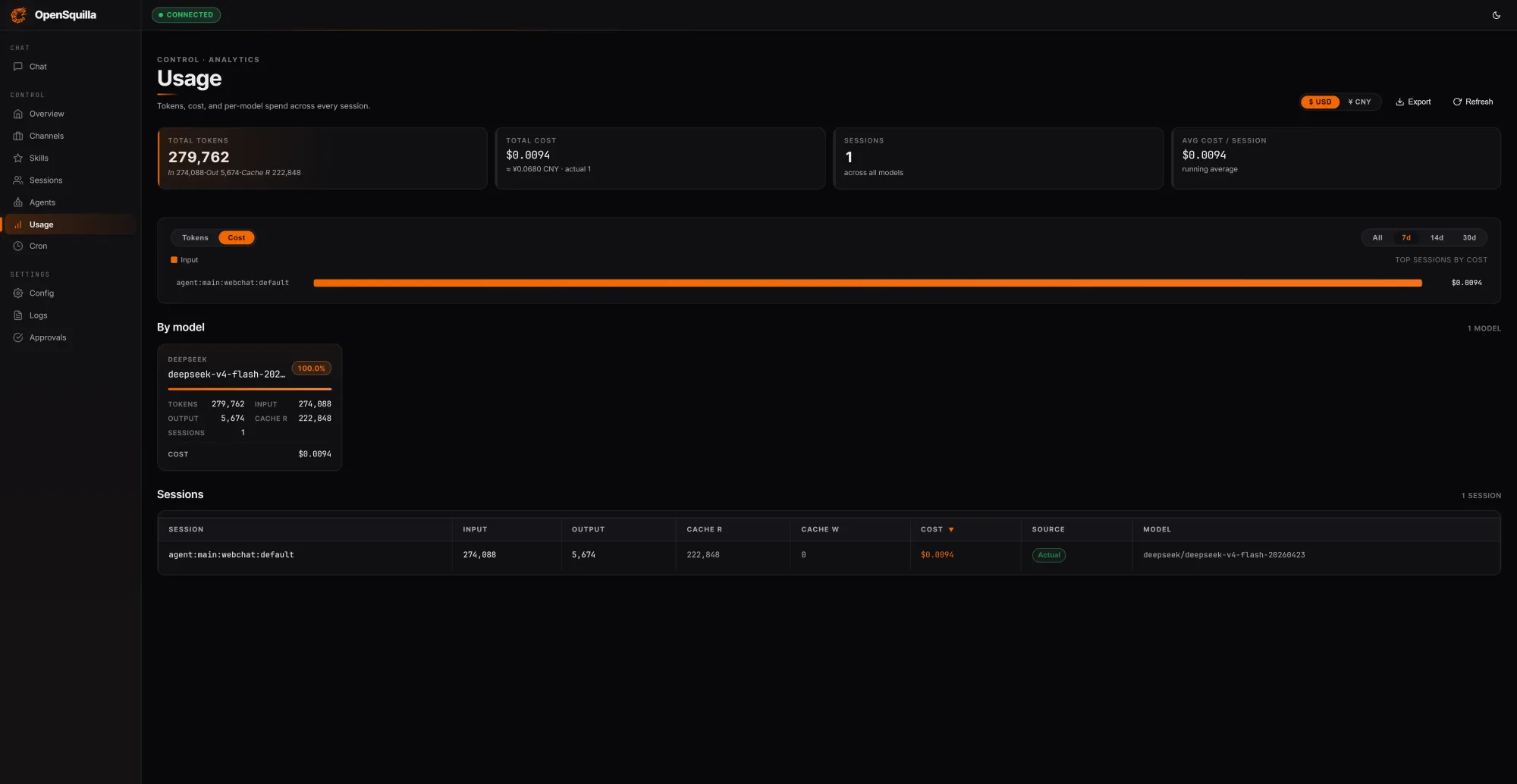
OpenSquilla’s new open-source, self-hostable AI agent runtime is built around a blunt observation: most agents pay for tokens they do not need to spend. In a local test, three prompts spanning factual lookup, technical summarization, and competitive analysis processed 279,762 tokens at a session cost of USD 0.0094 (approx. RM0.044). Crucially, 222,848 tokens—about 80% of inputs—were served from cache by reusing context instead of reloading it each turn. An ML classifier scores each request by complexity, routing simple queries to cheaper models and disabling deep reasoning on lightweight tasks so teams avoid overpaying for extended chain-of-thought. Skills are loaded on demand rather than stuffed into every context window, and quota hooks plus per-call cost tracking flag overspend early. Underneath, a four-tier memory design—working, episodic, semantic, and procedural—gives agents structured, reusable context, further cutting AI inference costs for long-horizon workflows.
MinIO MemKV: Killing the Recompute Tax with Shared Context Memory
MinIO’s MemKV tackles a different but related inefficiency: GPUs repeatedly recomputing the same context because they cannot share it efficiently across replicas or clusters. As agentic systems perform multi-step reasoning, context often gets discarded near the GPU, forcing models to rebuild it from scratch—a phenomenon MinIO labels the “recompute tax.” MemKV provides a flash-backed, petabyte-scale context memory tier, accessed end-to-end over high-speed Ethernet RDMA, designed to persist and share context at production concurrency. Benchmarks published by the company cite 95%+ better GPU utilization and about 50% lower cost per token when the recompute tax is minimized. Executives describe MemKV as “context-as-a-service”: a durable, addressable state layer that every agent and inference replica can read and update, much like a database row rather than a disposable cache entry. For teams optimizing GPU utilization efficiency, this shifts state management out of the serving layer and into an explicit context fabric.

Designing Agentic Systems for Cost-Aware Performance
Taken together, these tools signal a broader architectural shift in AI agent cost optimization. Kiro’s Requirements Analysis reduces waste at the specification tier, keeping agents from generating entire code paths that should never have been explored. OpenSquilla attacks token economics in the runtime itself, combining model routing, caching, and cognitive-style memory to reduce token consumption by 60–80% versus single-model baselines, while giving teams real-time visibility into AI inference costs. MinIO’s MemKV extends the stack down to GPU-adjacent infrastructure, treating context as durable state so clusters avoid structural drag from recompute. For engineering leaders, the throughline is clear: controlling costs in agentic AI is less about squeezing another percent out of a single model and more about orchestrating specs, memory, and hardware so work is done once, reused widely, and never recomputed without a reason.