
What MiniMax M3 Is and Why It Matters
MiniMax M3 model is a frontier AI system designed to combine a 1 million token context window, native multimodal input, and high-end coding performance so developers can build long-running, software-focused AI agents that work across large repositories, visual artifacts, and complex workflows in a single model. MiniMax M3 enters a landscape where frontier AI models are judged less on chat quality and more on whether they can work inside real codebases, call tools, and recover from errors across long sessions. Unlike earlier chatbot-centric releases, M3 is positioned as infrastructure for coding AI agents, automation pipelines, and multimodal AI models rather than a standalone assistant. Its arrival signals that competition around long-context, developer-grade models is widening, and that non-US labs now aim to be part of daily engineering stacks rather than distant leaderboard entries.
1 Million Token Context and the Cost of Long Memory
The headline feature of MiniMax M3 is its 1 million token context window, which puts it alongside leading frontier AI models in sheer working memory. MiniMax also cites a 512,000-token guaranteed minimum context, giving teams a practical floor for planning long-horizon coding and agent tasks. However, the more important claim is how M3 tries to make such context usable. The model uses a Grouped-Query Attention backbone plus MiniMax Sparse Attention, a design described as cutting per-token compute at million-token scale while speeding prefill and decoding. According to MiniMax’s published figures, “at million-token scale, M3 delivers 9.7x faster prefill and 15.6x faster decoding versus M2.” If those gains hold in independent tests, long-context agents could scan large repositories or long ticket histories without prohibitive latency and infrastructure cost, turning 1 million token context from a demo feature into a daily tool.
Native Multimodal Support and Agent Workflows
Beyond its 1 million token context, the MiniMax M3 model is built as a native multimodal AI model that accepts text, images, and video as input while returning text output. MiniMax’s launch materials present this as a way for development teams to keep source files, screenshots, diagrams, and other visual references inside one workflow instead of switching models. M3’s multimodal capabilities are tightly linked to MiniMax Code, an agent product that can break tasks into multi-stage workflows, run producer–verifier loops, and control a computer using the same model. That framing puts MiniMax alongside coding tools like Claude Code and other coding AI agents from major labs, where the value arises from the model plus its surrounding agent framework. If M3 can reliably combine code understanding with UI interaction and visual context, it could reduce the need for separate OCR, vision, and coding stacks in enterprise environments.
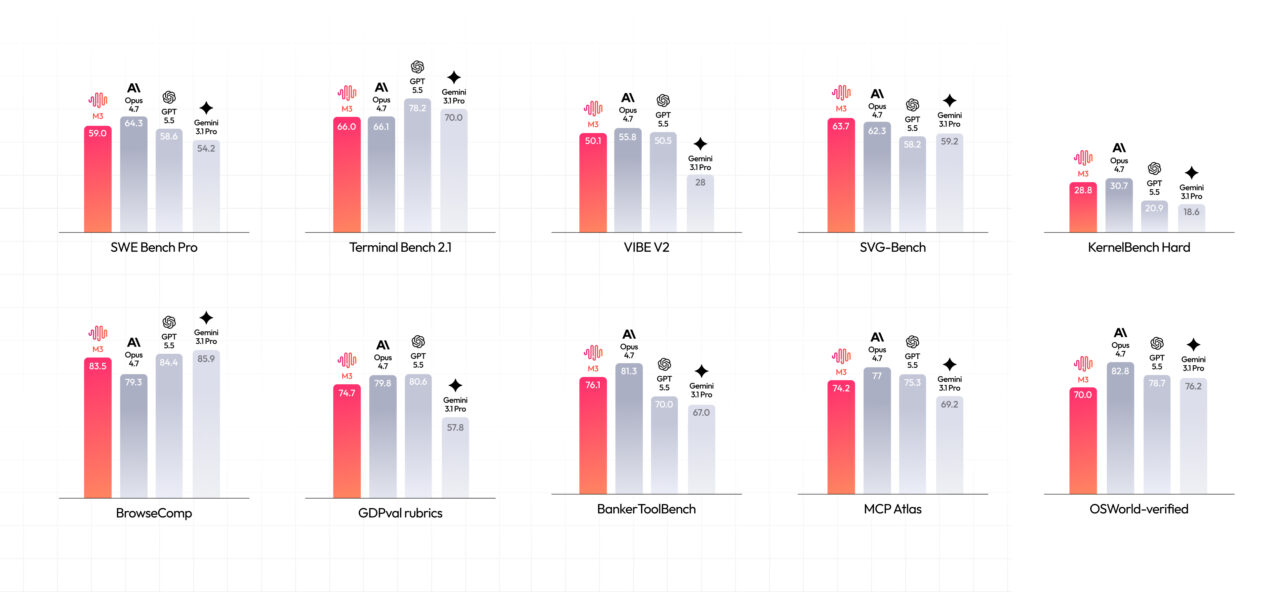
Coding Benchmarks and the Frontier Model Race
MiniMax is pitching M3 as a serious coding engine, but the benchmark story is nuanced. The company reports 59.0% on SWE-Bench Pro, 66.0% on Terminal-Bench 2.1, 34.8% on SWE-fficiency, 28.8% on KernelBench Hard, and 74.2% on MCP Atlas, and claims M3 beats GPT-5.5 and Gemini 3.1 Pro on SWE-Bench Pro while approaching Claude Opus 4.7. It also cites a top score on Claw-Eval, an autonomous agent benchmark. These numbers position M3 among frontier AI models for software work, yet MiniMax discloses that several runs used its own infrastructure and agent scaffolding, including Claude Code, Mini-SWE-Agent, or Terminus. That transparency underlines the need for external evaluation: independent runs, ideally using open weights, will show whether M3’s coding AI agents perform as promised on messy, internal codebases rather than curated benchmark suites.
Developer Adoption and Enterprise Infrastructure Decisions
From a market perspective, M3 is a test of whether a non-US frontier AI lab can become part of the standard developer toolchain. The model is available through MiniMax Code, token plans, and API services, exposed via OpenAI-compatible endpoints so teams can wire it into existing tools with fewer changes. MiniMax has also promised to release M3’s weights and a technical report within 10 days of launch, which could shift it from a closed API option to an open-weight foundation that enterprises can self-host or customize. For CTOs and platform teams, the choice is less about a single benchmark and more about fit: can M3’s 1 million token context, multimodal support, and coding performance reduce integration complexity, keep latency acceptable, and give enough control over data residency and deployment? If yes, it becomes a credible alternative in long-term AI infrastructure planning.





