What AI-Powered Code Generation Really Means for Productivity
AI-powered code generation is the use of machine learning models to write, modify, and review production-grade software code so that human engineers can focus more on design, integration, and decision-making while still owning quality and architecture. The debate is no longer about whether such tools exist, but whether they produce reliable engineering productivity gains beyond vendor marketing. Vendors promote productivity increases based on controlled trials that often omit real-world constraints like legacy systems, complex review processes, and shifting requirements. Engineering leaders now face pressure to commit large budgets to AI developer tools while lacking independent coding productivity metrics or a consistent AI code generation benchmark. That gap is starting to close as new data sources, from public performance indices to internal usage statistics, expose how AI-generated code performs under production-like conditions rather than in short, sanitized experiments.
Inside Navigara’s OSS Performance Index and ETV Metric
Navigara’s 500 OSS Performance Index is a live AI code generation benchmark that tracks engineering output across Microsoft, Meta, OpenAI, Vercel, Google, and Cloudflare. Instead of counting commits or lines of code, it uses Engineering Throughput Value (ETV), a deterministic scoring system applied to every merged file change. ETV weighs structural complexity, the surface area of code a developer needed to understand, the feature graph position in the wider architecture, and whether a change fixes defects introduced by others. According to Navigara, average engineering output across the six organizations rose 124.8% over a trailing 90-day window, while still showing a six-fold spread between the highest and lowest performers. Growth, maintenance, and fixes are reported in separate, non-additive buckets, which helps prevent gaming the metrics and gives leaders a cleaner view of where AI developer tools comparison efforts should focus.
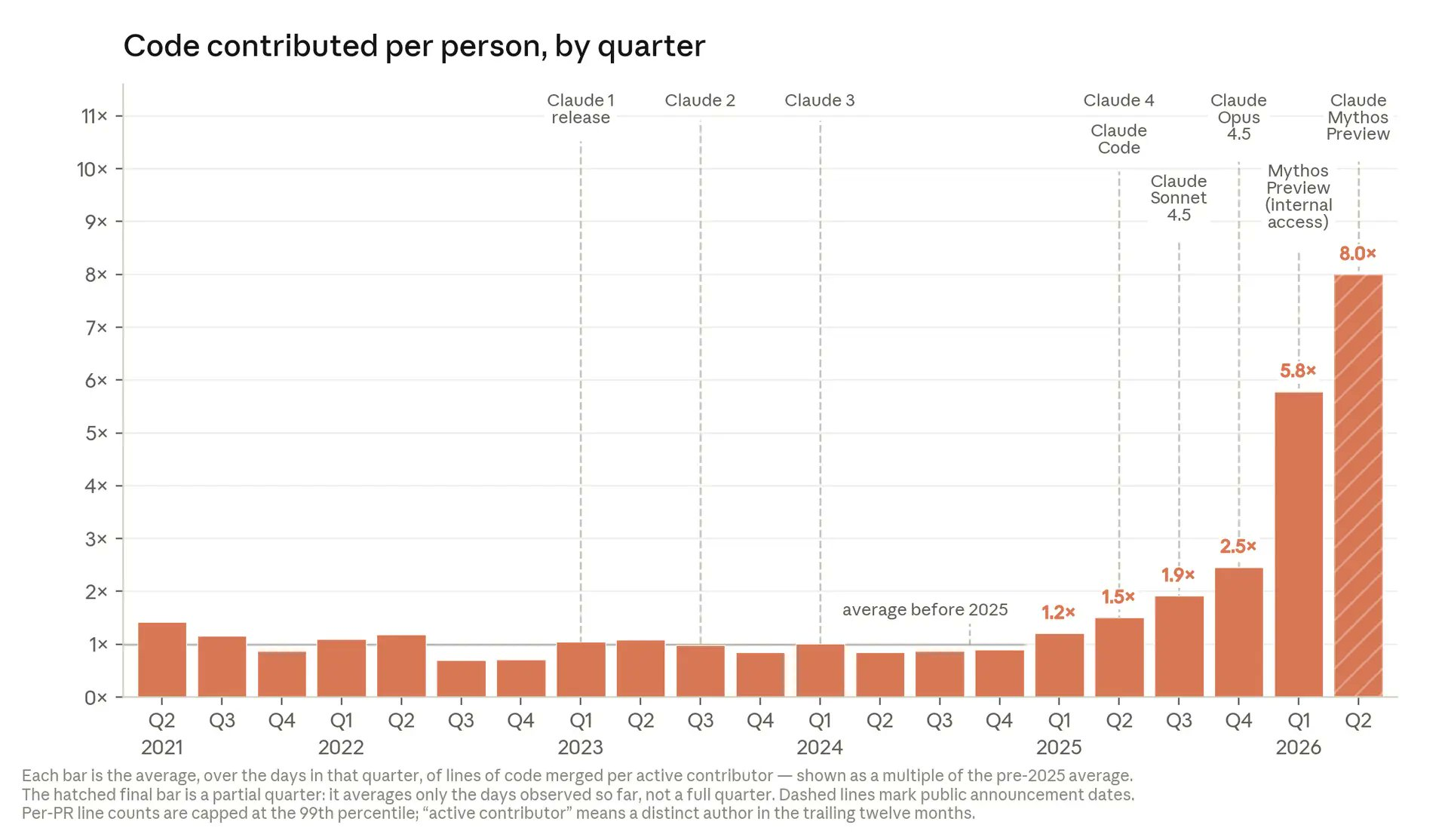
Anthropic’s 8x Code Output and the New Shape of Engineering Work
Anthropic’s internal metrics show how far AI-assisted development can go when adopted deeply. The company reports that average lines of code merged per active contributor have reached 8x the pre-2025 baseline, with Q2 2026 still in progress. The curve tracks the rollout of its own models: productivity hovered near 1x through 2024, then climbed to 1.2x in Q1 2025, 1.5x in Q2, 1.9x in Q3, and 2.5x in Q4, before jumping to 5.8x in Q1 2026. CEO Dario Amodei has said that a majority of the code at Anthropic is now written by AI, and some engineers stopped opening code editors, instead editing Claude Code’s drafts. These coding productivity metrics are based on real merges and capped per-pull-request line counts, making them more credible than surveys and highlighting how AI shifts engineering toward prompting, coordination, and product decisions.
Why Engineering Leaders Need Independent Benchmarks
Navigara’s index and Anthropic’s internal data address a credibility gap facing engineering leaders. Many AI productivity claims come from vendors’ own controlled trials, which rarely resemble complex production environments. Leaders are asked to make major AI tooling investments without an independently verifiable baseline or shared methodology for evaluating engineering productivity gains. Navigara responds with a transparent scoring engine and an open methodology, while its AI Spend Calculator gives finance teams a way to link hypothetical AI budgets to Growth, Maintenance, and Fixes in terms of cost per ETV delivered. Anthropic’s 8x figure, grounded in merged code rather than self-reported satisfaction, shows a real-world ceiling for what AI-heavy workflows can reach. Together, these sources offer a more reliable AI developer tools comparison framework, helping teams separate hype from measurable output and decide where AI will pay off in their own codebases.




