Mythos Arrives as the New Face of AI Vulnerability Detection
When Anthropic introduced its Claude Mythos Preview through Project Glasswing, it positioned the model as a frontier AI breakthrough for AI vulnerability detection. The message was clear: Mythos was too potent at uncovering security flaws to be broadly released, and needed careful, trusted-access channels. In security circles and R&D-heavy organizations, this framing fed into an existing wave of AI cybersecurity hype—promising automated audits of sprawling codebases, infrastructure, and research systems. Mythos was pitched not just as another scanner, but as an AI security tool that could rethink how defenders approach backlogs of unaddressed issues. Early narratives suggested it would comb source code, cloud environments, and critical infrastructure with unprecedented depth. That set expectations sky-high among developers, open source maintainers, and security teams who have long relied on static analyzers, fuzzers, and more modest AI systems to find bugs and exploitable patterns.
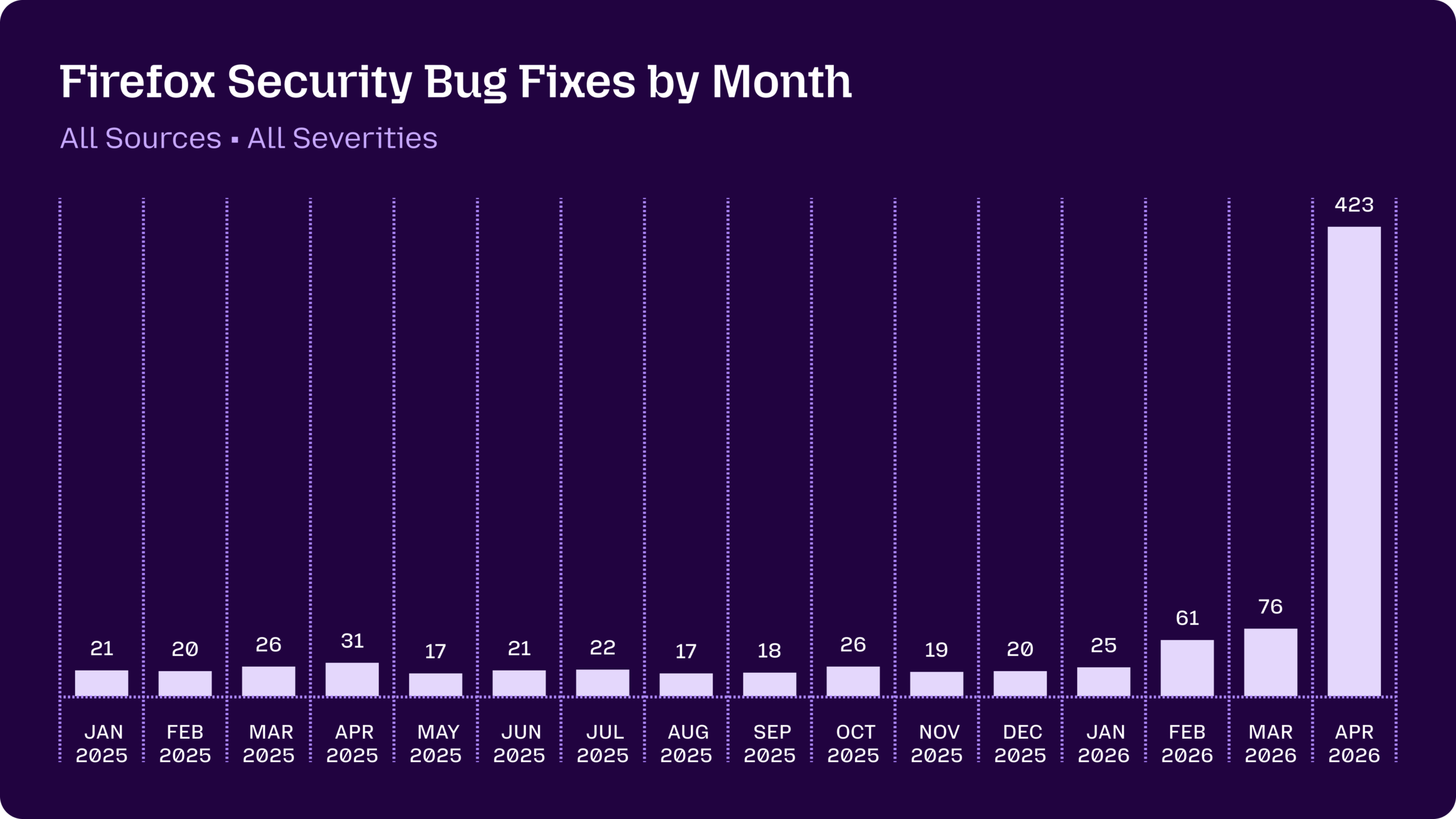
Mozilla’s Firefox Experiment: A Surge in Bugs, Not in Breakthroughs
Mozilla’s collaboration with Anthropic became the first major showcase for Mythos bug hunting at scale. After an earlier scan using Claude Opus 4.6 found 22 vulnerabilities in Firefox—14 of them high-severity—April’s results with Mythos Preview were dramatic: 423 security-related fixes in a single month. Of those, Mythos alone surfaced 271 issues, a headline figure that appeared to validate the promise of frontier AI models in security. Yet the details tell a more nuanced story. Only three of the Mythos-driven findings were deemed significant enough to receive their own CVE identifiers. The rest were low-severity vulnerabilities, defense-in-depth improvements, or fixes in obscure, long-dormant code paths that human auditors rarely touch. For defenders, this kind of broad hardening is valuable, especially when lower-priority flaws can later form high-severity chains. But it also underscores a gap: Mythos improved coverage and scale rather than revolutionizing the discovery of critical, high-impact bugs.
cURL’s Reality Check: One Low-Severity Flaw and a Lot of Hype
The clearest test of Mythos’s real-world value came from cURL, a mature, heavily scrutinized open source project. Developer Daniel Stenberg joined Project Glasswing expecting Mythos to reveal a trove of new issues beyond what existing AI and traditional tools had already uncovered. Instead, he never received direct access; someone else ran Mythos on cURL’s repository and sent him a brief report. That report initially flagged five supposed “confirmed security vulnerabilities.” After several hours of review by the cURL security team, only one issue held up—and it will be classified as a low-severity CVE in an upcoming release. Three findings were false positives already covered in documentation, and one was just a non-security bug. Stenberg acknowledged that Mythos produced helpful descriptions and additional bug reports, but concluded the model was not a game-changing AI security tool. In his view, the surrounding narrative was “primarily marketing,” not a leap beyond prior AI analyzers.

Frontier AI Models vs. Practical Security Outcomes
Taken together, the Firefox and cURL cases illuminate the tension between marketing claims and practical outcomes for AI security tools. In Firefox, Mythos scaled up bug discovery, especially for low-severity and long-ignored issues. In cURL, it found a single low-severity flaw in a codebase already exercised by several AI systems and traditional analyzers. That pattern suggests frontier AI models can be powerful accelerators for coverage and backlog reduction, but they may not consistently uncover dramatically more severe vulnerabilities than existing methods. This is reshaping industry debates about where advanced models fit in cybersecurity R&D workflows. Security leaders must weigh the overhead of integrating such tools—via partner programs, trusted access schemes, and gated APIs—against the marginal gains over established scanners and fuzzers. The question is no longer whether AI can help; it’s whether the incremental value of these frontier systems matches the hype that surrounds them.
Beyond the Buzz: Rethinking AI Security Hype and Access
Mythos’s mixed record raises broader questions about how the AI ecosystem frames security capabilities. Programs like Project Glasswing and similar trusted-access initiatives map out who gets early access to the most capable models: cloud platforms, OS maintainers, chip vendors, browser makers, network and endpoint security firms. That prioritization may indeed harden critical layers of the global tech stack, giving defenders a temporary head start. However, the cURL experience suggests that claims of unprecedented AI vulnerability detection need careful scrutiny. Overstating AI cybersecurity hype risks eroding trust among maintainers and security engineers who must triage results and integrate findings into already strained workflows. As AI security tools evolve, transparency about evaluation methods, false positive rates, and comparative performance will matter more than mystique. Mythos demonstrates that frontier AI can materially help with bug hunting—but also that substance must keep pace with the stories told about these models.