The Hidden Cost Crisis in AI Inference
As AI systems evolve from single-shot prompts to long-running, agentic workflows, the cost of simply keeping them “thinking” has become a major operational constraint. Two issues dominate: AI token costs and chronic GPU underutilization. Every time an agent reloads context or re-runs a calculation, it consumes extra tokens and burns GPU cycles without adding new value. This recompute tax quietly inflates bills and caps throughput, even when headline model performance looks impressive. At scale, inefficiencies in context handling and state management can eclipse model licensing as the primary cost driver. That is why a new wave of open-source AI tools is focusing not on bigger models, but on AI inference efficiency. Solutions like MinIO’s MemKV and the OpenSquilla runtime are redefining how context is stored, shared, and reused so developers can squeeze more useful work out of each token and each GPU-second.
MemKV Turns Context into a Shared, Durable Resource
MinIO’s MemKV tackles GPU utilization optimization by reimagining context as durable state rather than disposable cache. In many AI stacks, limited memory near the GPU forces systems to drop context, causing models to recompute prior steps and pay a heavy recompute tax. MemKV introduces a flash-based context memory tier, exposed over high-speed 800 GbE RDMA, that can persist and share context across GPU clusters. By eliminating repeated work, MinIO reports more than 95% better GPU utilization and around 50% lower cost per token on benchmarked inference workloads. Developers can make serving layers stateless, offloading session and agent state into MemKV so any replica can resume a conversation or task instantly, without sticky sessions. Context becomes a first-class, addressable asset, retrievable in microseconds, which reduces structural drag on GPU fleets and lays the groundwork for context‑as‑a‑service architectures.

OpenSquilla’s Token-Aware Routing and Memory Architecture
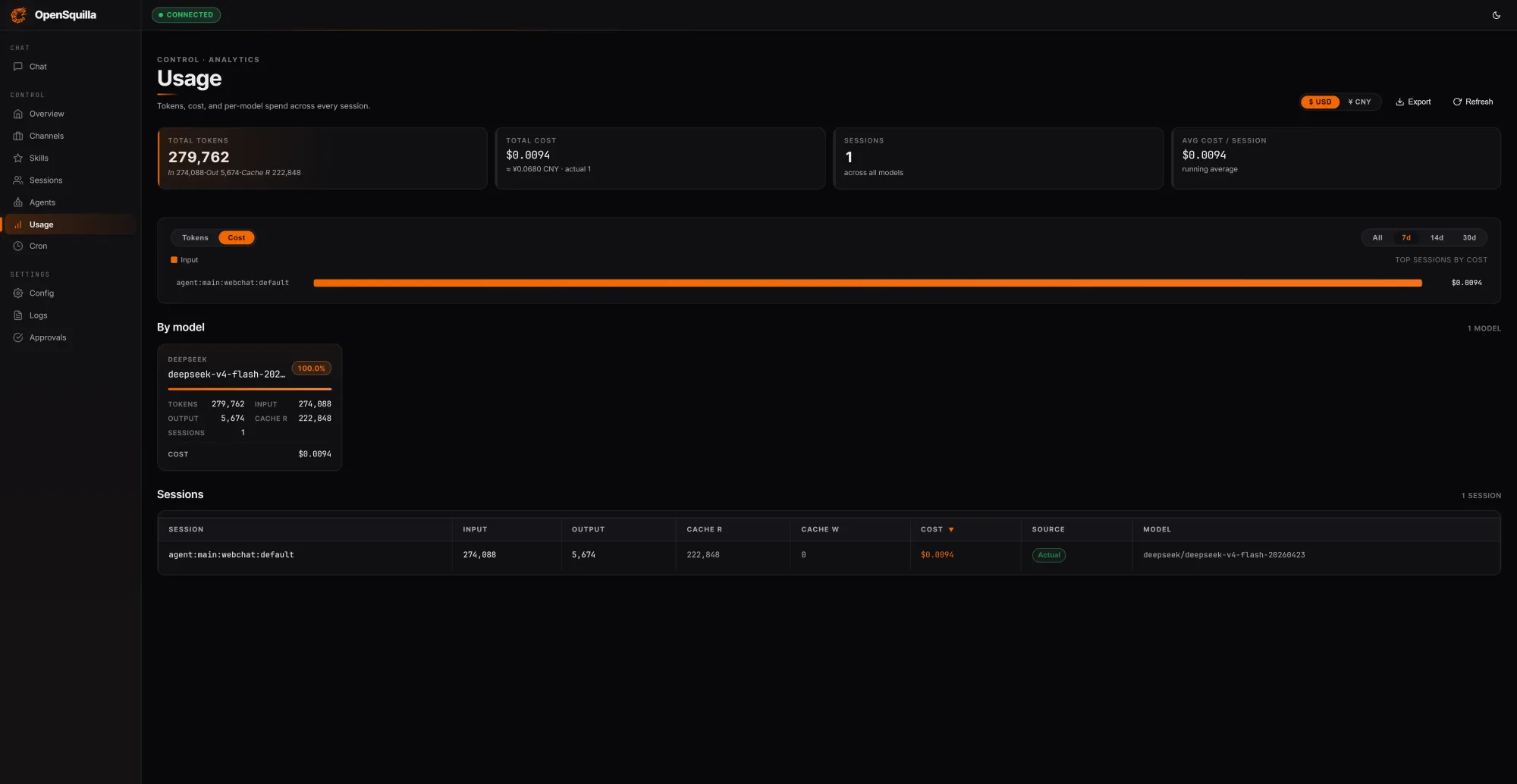
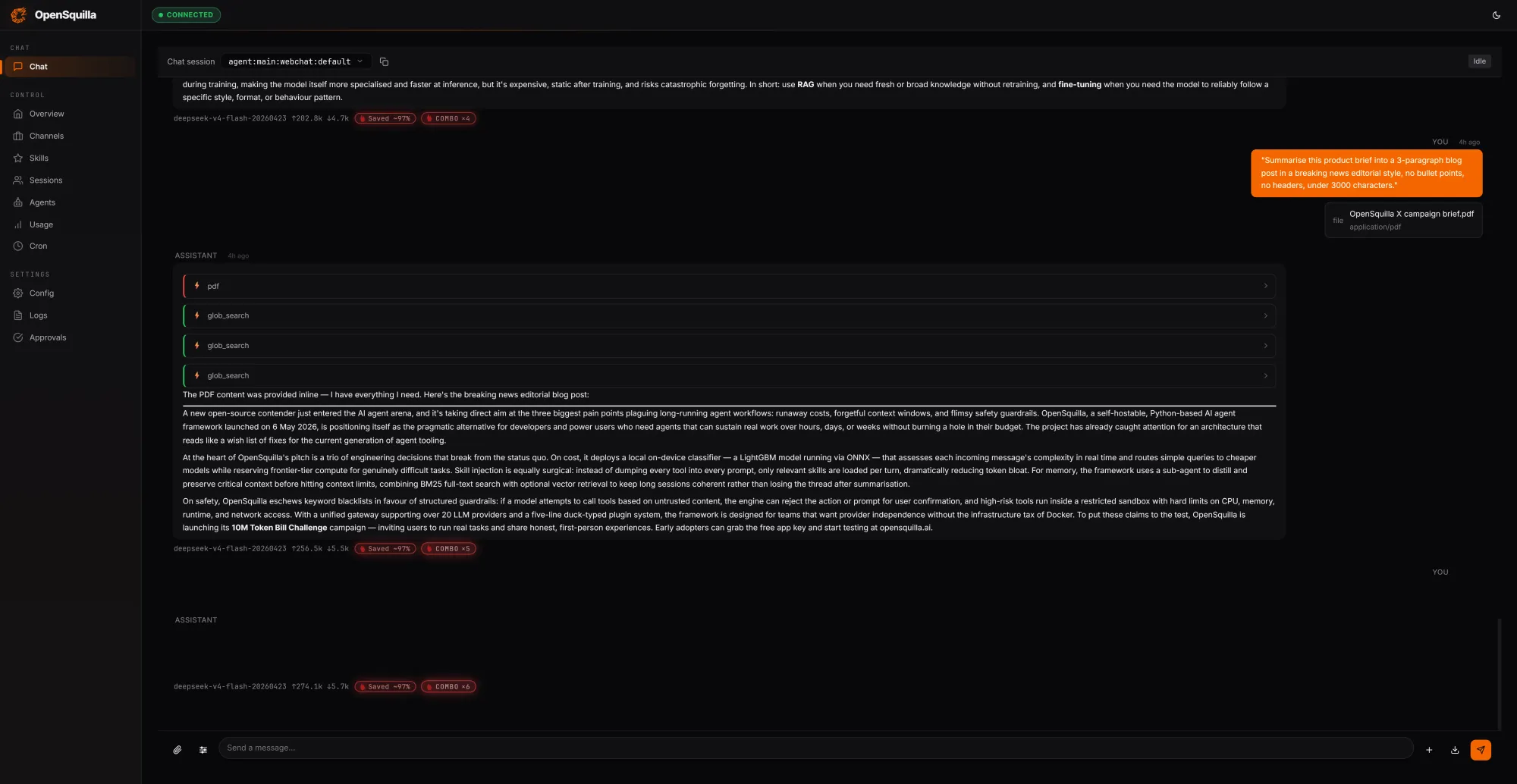
OpenSquilla approaches AI token costs from the agent runtime side, arguing that most frameworks burn tokens they never needed to spend. Its open-source, self-hostable agent runtime layers several AI inference efficiency techniques. An ML classifier inspects each incoming request using signals like message length, code presence, keywords, and semantic embeddings to estimate complexity. Easy questions route to cheaper models, while deep reasoning is disabled for trivial tasks so teams are not paying for extended chain-of-thought when it adds little value. In OpenSquilla’s own tests, three prompts consuming 279,762 tokens cost USD 0.0094 (approx. RM0.044), with 222,848 tokens—around 80% of input—served from cache by reusing context across turns. Its four-tier memory system (working, episodic, semantic, and raw) combines vector search with BM25 and local ONNX embeddings, minimizing redundant context reloads while keeping sensitive data on-device.
From Tokenomics to Practical Cost Control for Agentic AI
Both MemKV and OpenSquilla reflect a broader shift in AI from raw model benchmarks to token economics and operational discipline. Analyst commentary around MemKV underscores that the real battleground is how systems retain and share context during inference, not just which model scores highest on a leaderboard. OpenSquilla embeds cost controls directly into its runtime with quota hooks and per-call cost tracking, allowing teams to monitor and throttle spend in real time. Meanwhile, MemKV eliminates the need for brittle cache eviction strategies by treating context as a durable, regionally deployable resource, reducing recompute overhead and making GPU scheduling more flexible. Together, these open-source AI tools show how smarter routing, memory promotion, and context sharing can significantly cut AI token costs and GPU waste. For developers and enterprises running long-horizon agents, they offer a practical blueprint for scaling capability without letting infrastructure bills spiral.