
What DiffusionGemma Is and Why Its Speed Matters
DiffusionGemma is an experimental 26-billion-parameter Mixture of Experts language model from Google DeepMind that replaces traditional word-by-word generation with diffusion-style, block-wise denoising, delivering roughly four times faster on-device text generation than comparable Gemma 4 models on local GPUs while activating only 3.8 billion parameters per step to fit within high-end consumer graphics cards for low-latency, single-user inference. Instead of emitting one token at a time like a typist, the model begins from noisy placeholder tokens and refines a block of up to 256 tokens in parallel across several passes. This makes DiffusionGemma a fast language model for on-device text generation where latency, not leaderboard scores, is the main constraint. Google labels the model “experimental,” signaling that output quality trails standard Gemma 4, but the performance profile targets practical local GPU inference more than cloud-scale serving or maximum benchmark accuracy.

How Diffusion-Based Generation Changes the Performance Equation
DiffusionGemma borrows its core idea from image diffusion models like Stable Diffusion: start with noise, then iteratively denoise. In text form, that means generating an entire block, scoring and updating every token multiple times until the content stabilizes. Each step denoises up to 256 tokens in parallel, and every token can attend to every other token in both directions across the block. This structure shifts the bottleneck from memory bandwidth to compute, letting local GPUs stay busy instead of waiting between sequential “keystrokes.” According to Google, DiffusionGemma can exceed 1,000 tokens per second on a single Nvidia H100, while tests on a GeForce RTX 5090 reach around 700 tokens per second. Those numbers amount to roughly a 4x DiffusionGemma performance gain over similarly sized autoregressive Gemma models, especially for local GPU inference and single-user workloads.
The Accuracy Tradeoff: Where DiffusionGemma Falls Short and Shines
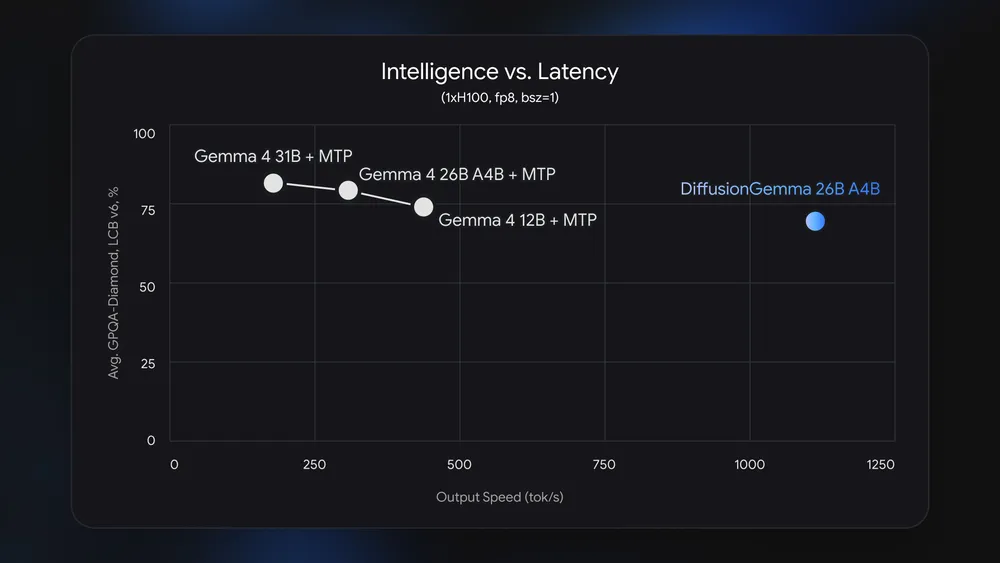
The speedup comes with a clear model optimization tradeoff: DiffusionGemma underperforms Gemma 4 26B A4B on standard language benchmarks. Google openly notes that the model is experimental and that the primary focus is speed and efficiency, not topping accuracy charts. Yet the architecture’s strengths line up with less linear tasks. Because every token can see both earlier and later positions, DiffusionGemma handles inline editing, code infilling, amino acid sequences, and mathematical graphs more naturally than strictly left-to-right models. Demonstrations include Sudoku solving and structured constraint reasoning, where the model can revisit and correct the entire block repeatedly. For everyday chat or long-form drafting, that may mean slightly weaker outputs than a tuned autoregressive alternative. For tool-like interactions and fast on-device text generation, however, the tradeoff is often worth it: responsiveness matters more than squeezing out a few extra benchmark points.

NVIDIA’s RTX and DGX Stack Turn Theory into Practical Throughput
DiffusionGemma’s parallelism lines up neatly with NVIDIA’s current hardware. The model is available under an Apache 2.0 license and arrives with day-1 support across GeForce RTX, RTX PRO platforms, and DGX systems, integrated into CUDA-based stacks and frameworks like Hugging Face Transformers, vLLM, and Unsloth. NVIDIA reports that a single H100 Tensor Core GPU in a DGX Station can reach about 1,000 tokens per second, while DGX Spark personal AI systems deliver around 150 tokens per second for local inference. DGX Station is positioned for up to 800 tokens per second in low-latency text workloads. Because the Mixture of Experts setup activates only 3.8 billion parameters per step and supports BF16 and NVFP4 precision, DiffusionGemma fits within 18GB VRAM and benefits from tensor core acceleration, turning it into a practical fast language model for local GPU inference rather than a cloud-only experiment.

Real-Time Code Completion and the Future of On-Device Text Generation
For developers, the most immediate impact is latency-sensitive tooling like real-time code completion, inline refactoring, and documentation suggestions. Generating hundreds of tokens per second on a single GPU means editors can request large chunks of context-aware output without visible lag, even when running fully offline. On-device text generation also avoids per-token cloud costs and reduces privacy exposure, a draw for organizations that want local GPU inference for sensitive codebases. DiffusionGemma’s 256K-token context window and multi-modal inputs further open doors to agentic workflows that mix logs, source trees, and UI traces. The cost is lower raw accuracy than top-tier Gemma 4 models, so it is less suited as a general-purpose oracle and more as a fast, specialized assistant. As more tools target this pattern, the question shifts from “Is it the smartest?” to “Is it fast and good enough to feel instant on your own machine?”





