
What the Next Generation of Amazon OpenSearch Serverless Delivers
Amazon OpenSearch Serverless is a fully managed, serverless search and analytics service on AWS that now uses a redesigned architecture to deliver much faster resource provisioning, automatic scaling, and lower peak costs for enterprise text and vector search workloads. AWS has announced the general availability of the next generation of Amazon OpenSearch Serverless with “20 times faster resource provisioning than the previous serverless architecture” and true scale-to-zero capability. This matters for enterprises that depend on search-powered applications, observability, or AI workloads, where slow provisioning can delay deployments and incident response. The new model sits between traditional search platforms and newer AI-focused vector stores, offering a balance of search functionality and operational simplicity. For teams standardizing on AWS serverless search, this update aims to cut the lag between defining a collection and serving queries into seconds rather than minutes.
Inside the New Architecture: Stateless OCUs and Shared Storage
The heart of the next-generation Amazon OpenSearch Serverless architecture is a shared storage layer that decouples compute from data. OpenSearch Capacity Units (OCUs) are now stateless, mounting shared storage directly instead of relying on local disks. This design removes the need to bootstrap local storage during startup, enabling OCUs to begin serving traffic within seconds and driving the headline improvement in resource provisioning performance. It also allows idle capacity to scale down without impacting data, because the data no longer lives on the compute nodes themselves. This shift is central to building more efficient enterprise search infrastructure, where unpredictable workloads often force teams to overprovision. By making OCUs disposable and fast to spin up, AWS serverless search can react more closely to real-time demand, improving cost efficiency during off-peak periods while preserving performance when traffic spikes.
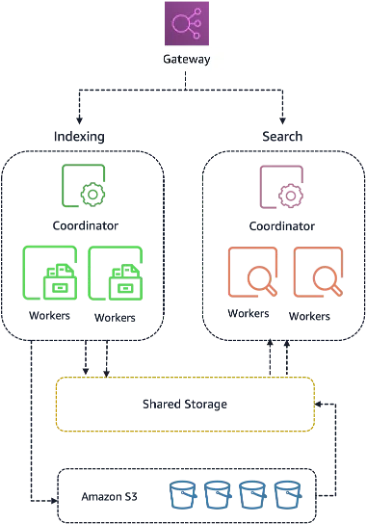
Reducing Enterprise Deployment Complexity with New Endpoints and Groups
Beyond raw resource provisioning performance, the redesign targets day-to-day deployment complexity for large organizations. AWS introduces two endpoint formats under the on.aws domain, both using AWS PrivateLink for private connectivity from a virtual private cloud or on-premise environments. A per-collection endpoint continues to give one hostname per collection, but the new per-account regional endpoint exposes all collections behind a single hostname, with the target specified through x-amz-aoss-collection-id or x-amz-aoss-collection-name headers. This simplifies network management, connection pooling, and TLS session reuse in complex enterprise search infrastructure. Collection groups, introduced earlier, now sit at the center of the experience: teams define whether a group is Classic or NextGen, and all collections in that group inherit the architecture generation. They can also share compute across collections, which can lower costs for many smaller workloads consolidated under one operational umbrella.
Faster Time-to-Value for Search and AI-Driven Applications
For product and data teams, the biggest impact of faster Amazon OpenSearch Serverless provisioning is time-to-value. New search collections, whether for log analytics, customer-facing search, or vector search in AI applications, can move from definition to ready state much more quickly. AWS positions OpenSearch Serverless as a foundational building block for agentic AI, with native integrations to AI-focused development platforms and AI-assisted coding tools. According to AWS authors Sohaib Katariwala, Arjun Nambiar, and Raj Ramasubbu, the NextGen architecture is now the default for new collections, helping AI and analytics teams standardize on the improved model. Scale-to-zero support also opens the door for more experimental or low-traffic projects that would previously have been priced out, though teams still need to weigh potential cold-start latency against cost savings when designing their search-dependent applications.
Operational Benefits of AWS Serverless Search for Large-Scale Data
The serverless consumption model means enterprises using Amazon OpenSearch Serverless no longer need to manage clusters, node sizing, or manual scaling policies for their search infrastructure. Compute is billed through OCUs for search, indexing, and GPU acceleration, while storage is charged separately by capacity, aligning costs more closely with actual usage. AWS states that the redesigned architecture can deliver up to 60% lower cost than a provisioned cluster for peak loads, which is significant for organizations running many high-traffic search workloads or multi-tenant analytics platforms. Combined with PrivateLink endpoints and collection groups, operations teams can standardize deployment patterns across business units while keeping network paths and access control clear. For AWS customers already invested in serverless architectures, OpenSearch Serverless now offers a more coherent fit with event-driven and AI-heavy stacks, reducing infrastructure management overhead while preserving flexibility in how data is indexed and queried.





