Near-Frontier Performance from a Flash-Tier Model
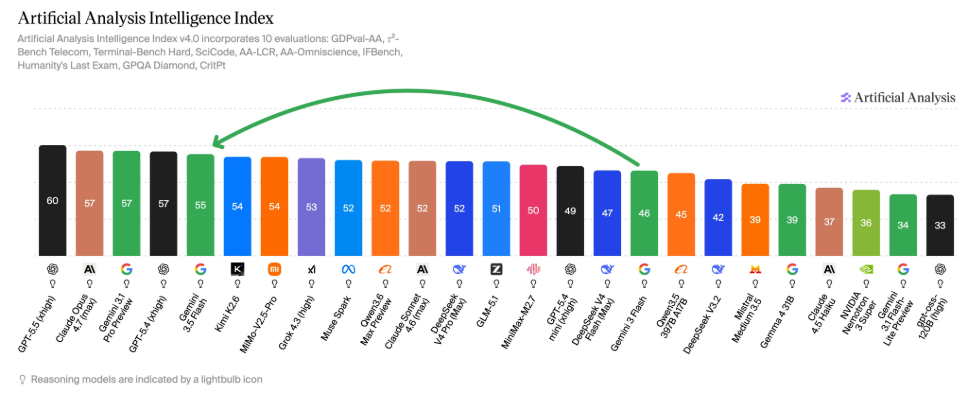
Gemini 3.5 Flash marks a decisive shift in how “lightweight” models are defined. On the independent Artificial Analysis Intelligence Index, it scores 55, placing it just two points behind Anthropic’s flagship Claude Opus 4.7 and five points behind GPT-5.5. That puts Gemini 3.5 Flash well inside frontier model benchmarks territory despite being positioned as a speed‑ and cost‑optimized tier. It also ranks fifth overall on the Intelligence Index, ahead of Grok 4.3 (high) and Claude Sonnet 4.6 (max), reinforcing that this is not merely a budget option but a serious general‑purpose model. For developers, the Gemini 3.5 Flash performance story is clear: the tradeoff versus top frontier systems is shrinking to a few benchmark points, while the model still carries the traditional Flash promise of higher throughput and more efficient deployment.
Token Pricing Efficiency and the New Cost Curve
Where Gemini 3.5 Flash becomes especially disruptive is in AI model cost comparison. Google prices the model at USD 1.50 (approx. RM6.90) per million input tokens and USD 9.00 (approx. RM41.40) per million output tokens. That is roughly one-third of GPT-5.5’s launch price of USD 5.00 (approx. RM23.00) input and USD 30.00 (approx. RM138.00) output per million tokens. On a pure token pricing efficiency basis, Flash offers near-frontier capability at a steep discount relative to OpenAI’s latest flagship. However, the picture is more nuanced in practice: Artificial Analysis estimates that running its full Intelligence Index with Gemini 3.5 Flash costs USD 1,552 (approx. RM7,149) because the model uses more turns per task than its predecessor. Even so, against other high-end models, Flash remains economically competitive, especially for workloads where throughput and raw speed amplify return on spend.

Speed, Agentic Gains, and Beating Gemini 3.1 Pro
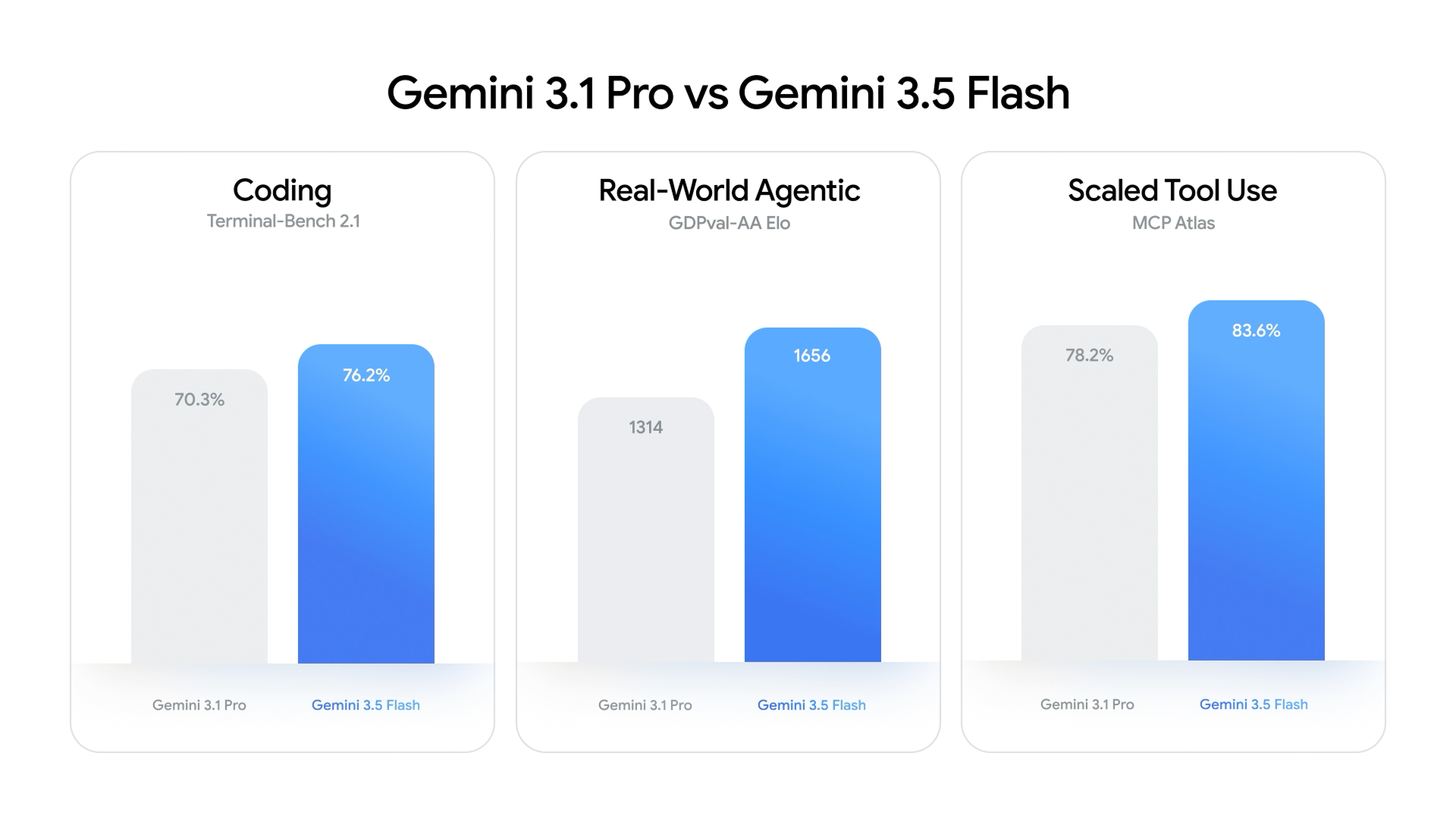
Beyond headline benchmarks, Gemini 3.5 Flash is optimized for agents and long-horizon tasks. It can plan across massive codebases, deploy subagents in parallel, and sustain multi-step workflows, posting a GDPval-AA Elo of 1,656. That score not only eclipses Gemini 3 Flash and Gemini 3.1 Pro, but also clears Claude Sonnet 4.6, signaling a step-change in agentic capability. On coding (Terminal-Bench 2.1), Gemini 3.5 Flash reaches 76.2% versus Gemini 3.1 Pro’s 70.3%, and on scaled tool use (MCP Atlas) it scores 83.6% against 78.2%. These gains come with exceptional speed: Google reports 289 tokens per second, with Artificial Analysis measuring over 280 output tokens per second—around 70% faster than Gemini 3 Flash. On the intelligence‑versus‑speed frontier, Gemini 3.5 Flash sits in the highly attractive zone where high capability meets low latency, redefining expectations for Flash‑tier models.
Multimodal Strength and the Tradeoffs Behind Efficiency
Gemini 3.5 Flash also extends Google’s lead in multimodal AI. It achieves 84% on the MMMU-Pro benchmark, edging out Gemini 3.1 Pro’s 82% and posting the highest recorded result there. The model accepts image, video, speech, and text inputs, a broader modality set than many competing frontier models that remain image‑only. At the same time, Google has substantially reduced hallucinations: on the AA-Omniscience benchmark, Gemini 3.5 Flash cuts its hallucination rate from 92% to 61%, an 11‑point overall improvement score-wise. Yet it still trails GPT-5.5 and Claude Opus 4.7 on knowledge reliability, which matters for high‑stakes, information‑dense use cases. Another tradeoff is interaction length: Flash averages 49 turns per task, higher than several rivals. That longer conversational footprint partly drives up total run costs even as per‑token prices remain attractive, reminding teams that efficiency depends on both model pricing and behavior.
What It Means for Choosing Between Frontier and Efficient Models
Taken together, these results show an AI market where the historical gap between frontier and efficient models is collapsing. Gemini 3.5 Flash outperforms Gemini 3.1 Pro on many benchmarks, including coding and real‑world agentic tasks, despite being branded as a lighter‑weight tier released just months later. For developers, the decision is no longer a simple choice between maximum quality and budget. Instead, it becomes a portfolio question: when is a near‑frontier model with superior speed and better token pricing efficiency more valuable than a slightly smarter but slower and more expensive frontier system? As Google prepares Gemini 3.5 Pro, Flash already pressures rivals by delivering high intelligence, strong multimodal performance, and compelling economics. The message to the ecosystem is clear: model generations now move fast enough that “Flash” releases can invalidate assumptions about Pro‑tier superiority in a single cycle.