A New Benchmark for AI-Driven Code Refactoring
Scale Labs’ Refactoring Leaderboard marks a turning point in how AI coding agents are evaluated on real software engineering work. Rather than solving small, isolated coding puzzles, agents are dropped into full repositories and asked to perform complex, multi-file refactors while preserving behavior. The leaderboard is part of the broader SWE Atlas research suite, which measures agents across comprehension, testing, and now structural change. Refactoring tasks here are intentionally demanding, requiring roughly twice as many lines of code changes and 1.7 times more file edits than SWE-Bench Pro, making them a stress test for automated code restructuring. By focusing on production-style codebases, the benchmark moves closer to the realities of legacy code modernization, where understanding existing architecture, coordinating edits across modules, and keeping tests green are mandatory. This shift positions AI tools as potential collaborators in the most delicate phase of software maintenance: restructuring without breaking anything.
From Monoliths to Modules: What the Tasks Reveal
The Refactoring Leaderboard zeroes in on patterns that mirror the everyday pain of legacy systems. Tasks span decomposing monolithic implementations, replacing weak interfaces with stronger, typed abstractions, extracting duplicated or misplaced logic into shared modules, and relocating code to sharpen module boundaries. These are classic code refactoring tools in human workflows, but the benchmark asks whether AI coding agents can execute them end-to-end inside live codebases. Success is measured in two dimensions: tests must pass, and a rubric-based review assesses maintainability, artifact cleanup, and avoidance of anti-patterns. This dual lens shows that many agents can mechanically reshape code enough to satisfy tests, yet miss the craftsmanship developers expect. Dead code, stale imports, duplicated functions, outdated comments, and missed call sites frequently linger. For teams eyeing legacy code modernization, the message is clear: AI can accelerate structural change, but human review remains essential to ensure long-term maintainability and architectural integrity.
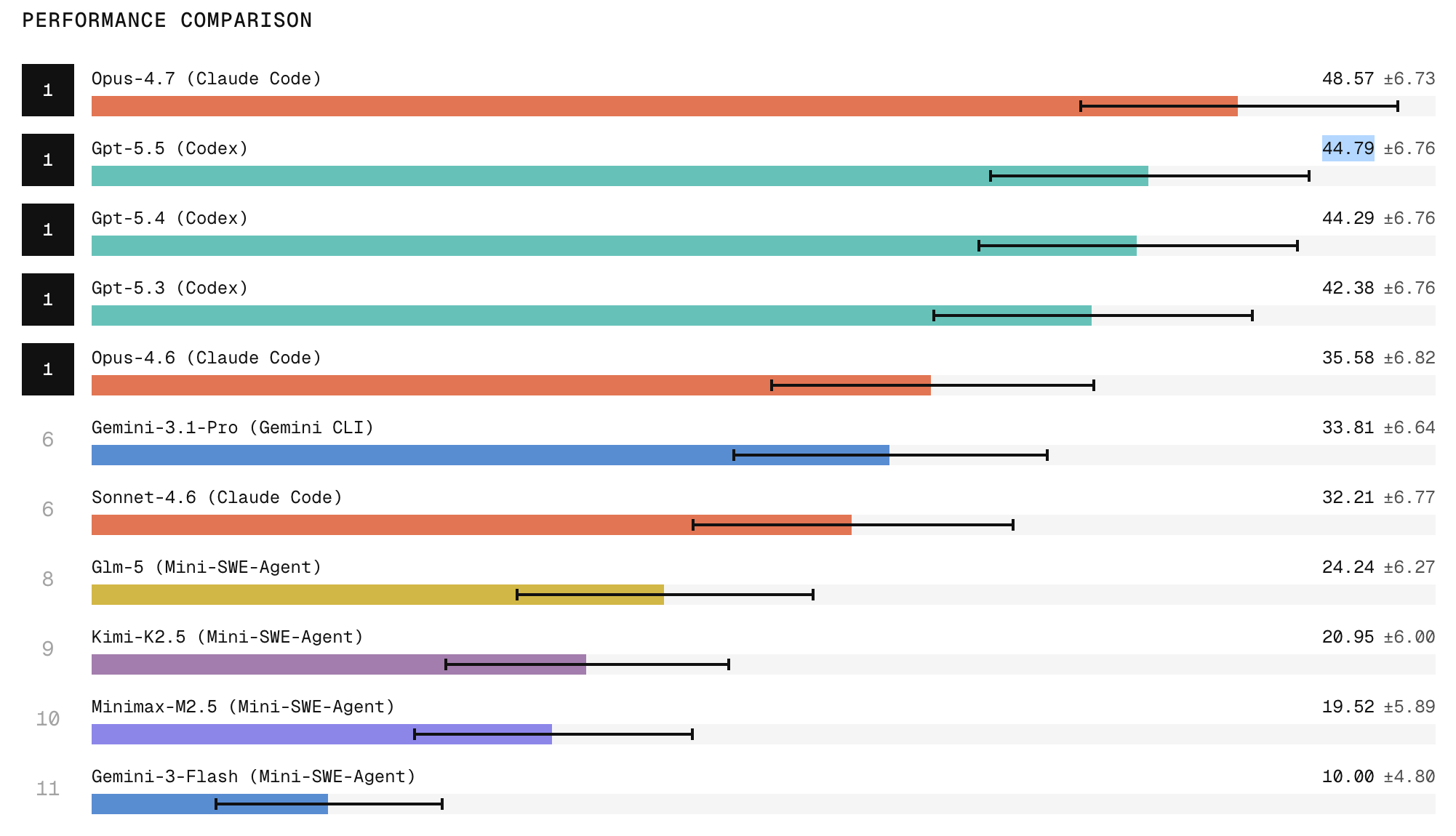
Performance Metrics: Stronger Refactors, Uneven Consistency
Leaderboard results suggest frontier models are already capable of sophisticated automated code restructuring. Claude Code with Opus 4.7 tops the Refactoring Leaderboard, with ChatGPT 5.5 following, indicating that the strongest closed models can orchestrate broad repository exploration, structural edits, and behavioral preservation more effectively than current open-weight systems. However, the same data exposes a gap between peak performance and everyday reliability. When agents attempt the same refactoring task three times, they are two to three times more likely to succeed once than to succeed in all three runs. In practice, that means a tool may appear impressive in a demo yet prove volatile in continuous integration pipelines. For engineering leaders, these metrics underscore that assessing AI coding agents is not just about whether they can restructure complex codebases once, but whether they can be trusted to do so repeatedly under similar conditions.
Trust, Adoption, and the Path to Production-Grade Agents
Despite promising progress, developer trust remains the central adoption barrier for AI-assisted refactoring. Scale Labs frames SWE Atlas as a way to treat AI agents more like software engineers than code generators, testing their ability to inspect codebases, infer design constraints, and coordinate edits without regressions. Yet the Refactoring Leaderboard shows that even leading models still struggle with consistent behavior, deep codebase understanding, and thorough cleanup of artifacts. Jason Droege, Scale Labs’ CEO, emphasizes reliability as the key hurdle: capability is rising, but consistency is not keeping pace. For teams considering AI coding agents in legacy code modernization, a realistic stance is emerging. These tools can meaningfully accelerate refactors and reduce toil, especially on large-scale, repetitive changes. However, they are not yet ready for unattended production workflows, and must be embedded into processes that assume human oversight, code review, and iterative validation.