Hy3 Preview: Tencent’s First Flagship After the Hunyuan Rebuild
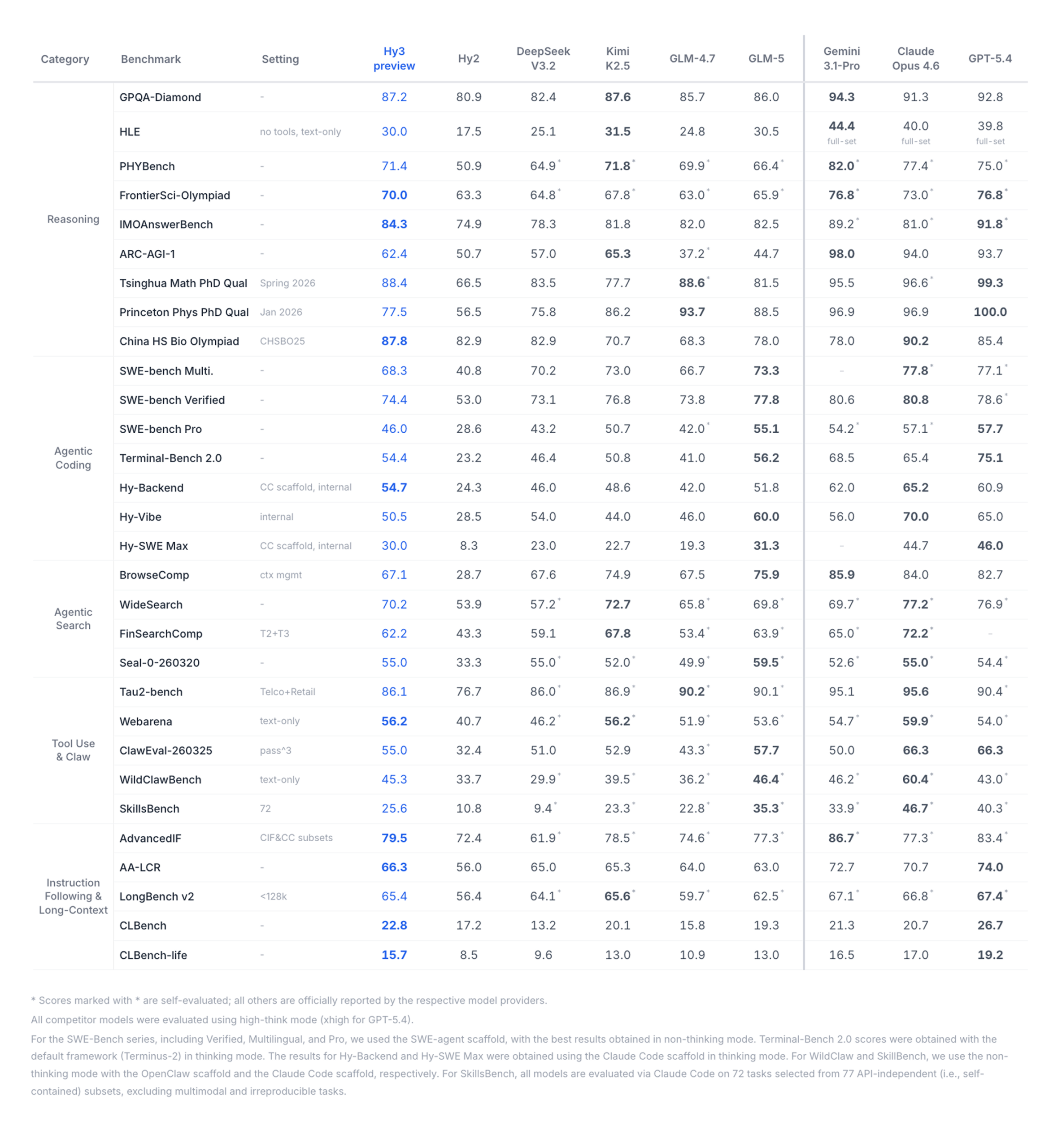
Hy3 preview is the first major large language model to emerge from Tencent’s rebuilt Hunyuan pre‑training and reinforcement‑learning pipeline, and the company is treating it as a proof point for its new AI stack. The Tencent Hy3 model is a mixture of experts LLM with 295 billion total parameters, of which 21 billion are activated for any given token, and it supports an exceptionally large 256K context window. Tencent says Hy3 is tuned for complex reasoning, instruction following, in‑context learning, coding, and agentic workloads, aiming squarely at frontier‑model territory. Just as notable is the speed: Hy3 preview reached public release in under three months after the infrastructure reset, signaling a shorter iteration loop between research, training, and deployment. With Hy3 preview framed as the first step in rebuilding the Hunyuan line, Tencent is positioning this 295B parameter AI as both a technical milestone and a structural shift in how it ships models.
Inside a Mixture of Experts LLM and Why It Matters
Hy3 preview uses a mixture of experts architecture that Tencent describes as a “fast‑and‑slow‑thinking fused” design. In accessible terms, a mixture of experts LLM is built from many specialized subnetworks (the “experts”), but only a small subset of them are activated for each token. That is why Hy3 can claim 295 billion total parameters while typically using only 21 billion at inference time. The benefit is straightforward: the model’s capacity grows significantly without compute and cost scaling linearly, because most parameters stay idle for any single request. This design is becoming a favored path for big players that want to push capabilities without unsustainable serving costs. For Tencent, the Hy3 architecture supports its stated focus on systematic capability, authentic evaluation, and cost‑effectiveness, turning MoE into a practical strategy for running a long context language model widely across products rather than a lab‑only showcase.
What a 256K Context Window Really Unlocks
The Hy3 preview’s 256K context window is one of its most consequential specs. A 256K context window means the model can ingest and reason over extremely long stretches of text or tokens in one shot rather than through fragmented chunks. In practical terms, that capacity can underpin full‑codebase assistance for sizeable software projects, analysis of multi‑day chat or meeting logs, and deep analytics across large document collections without constant summarization and re‑prompting. It also supports more reliable in‑context learning: instead of fine‑tuning, teams can provide extensive style guides, historical decisions, or domain documents directly in the prompt. Combined with Hy3’s mixture‑of‑experts efficiency, this long context language model is structured to handle dense, real‑world workflows such as agentic search, tool use, and complex reasoning benchmarks where keeping broader context intact can markedly improve quality and reduce orchestration overhead.
Pricing, Efficiency and Tencent’s Strategic Positioning
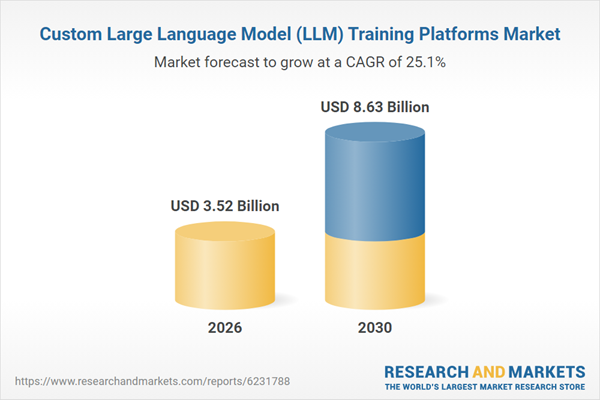
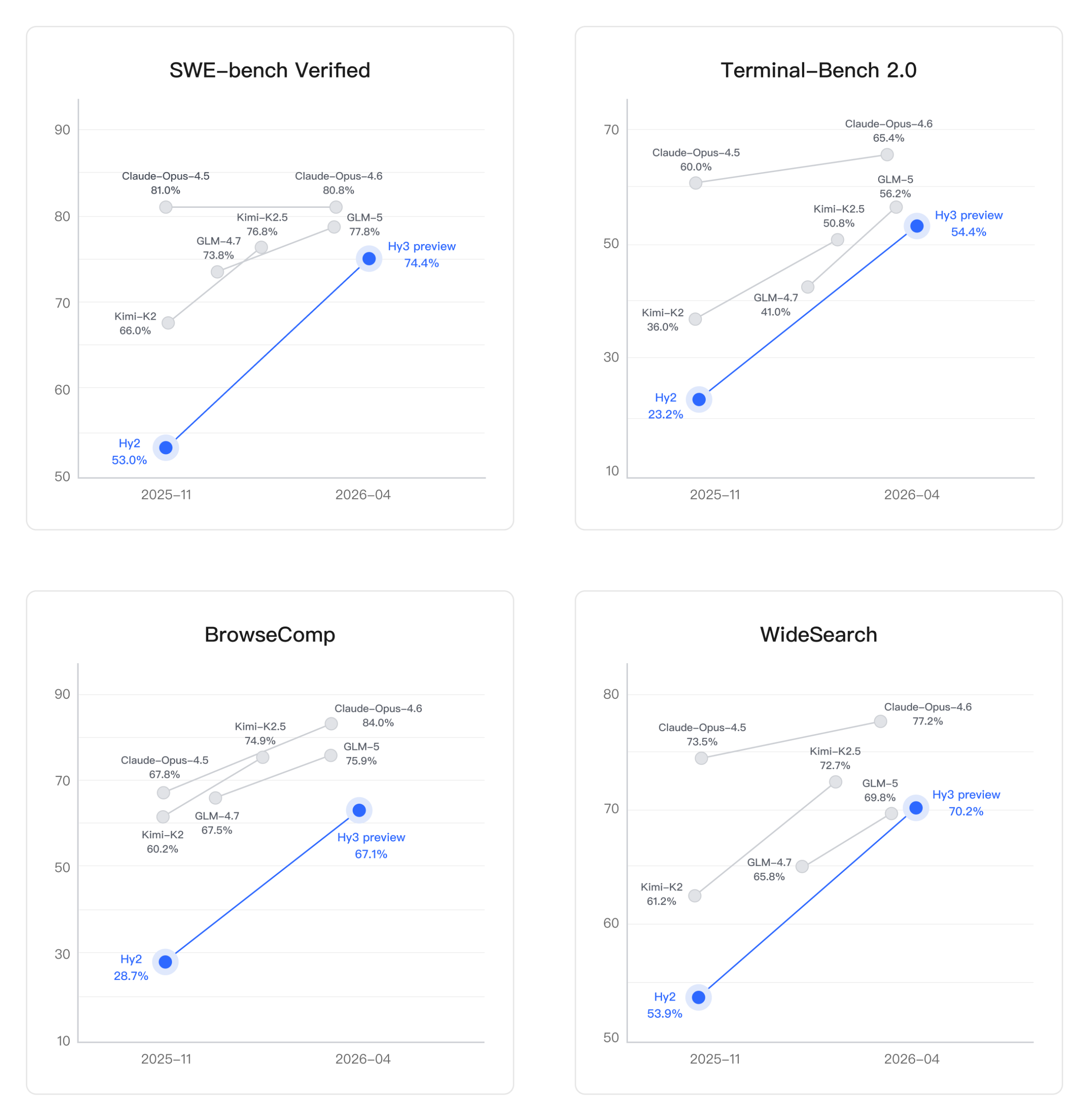
Tencent is pairing Hy3 preview’s specs with a clear efficiency and accessibility story. The company reports that Hy3 improves inference efficiency by 40%, and it is offered via Tencent Cloud’s TokenHub at RMB 1.2 per million input tokens and RMB 4 per million output tokens. That pricing, combined with the mixture‑of‑experts design, signals an intent to make Hy3 a workhorse model rather than a narrow flagship. Benchmarks across SWE‑bench Verified, Terminal‑Bench 2.0, BrowseComp and WideSearch show performance competitive with models like GLM‑5 and narrowing the gap with top frontier systems such as Claude Opus and GPT‑5‑class offerings. In a landscape where the custom LLM training platforms market is rapidly expanding and enterprises are demanding domain‑specific, cost‑controlled AI, Tencent’s rebuilt pipeline and Hy3’s deployment‑ready profile position the company as a serious player in long‑context, efficiency‑focused AI infrastructure.
From Internal Tools to Super‑App Integration: Early Hy3 Use Cases
Hy3 preview was not launched in isolation; Tencent deployed it inside multiple products even before public release. The model already powers tools such as Yuanbao, CodeBuddy, WorkBuddy, ima, Tencent Docs, and the game Peacekeeper Elite, illustrating a product co‑design strategy where model training and application feedback are tightly linked. Inside productivity suites, a 256K context window can drive rich document collaboration, long‑form summarization, and knowledge search. In code assistants like CodeBuddy, the 295B parameter AI with 21B activated parameters can tackle complex debugging and multi‑file refactors. In consumer and gaming contexts, Hy3 can support more adaptive agents, smarter in‑app assistants, and persistent, context‑aware experiences. As enterprises increasingly seek custom LLM training platforms and domain‑specific deployments, Tencent’s ability to plug a mixture of experts LLM directly into its ecosystem gives Hy3 an immediate proving ground and a feedback loop that should accelerate its evolution.