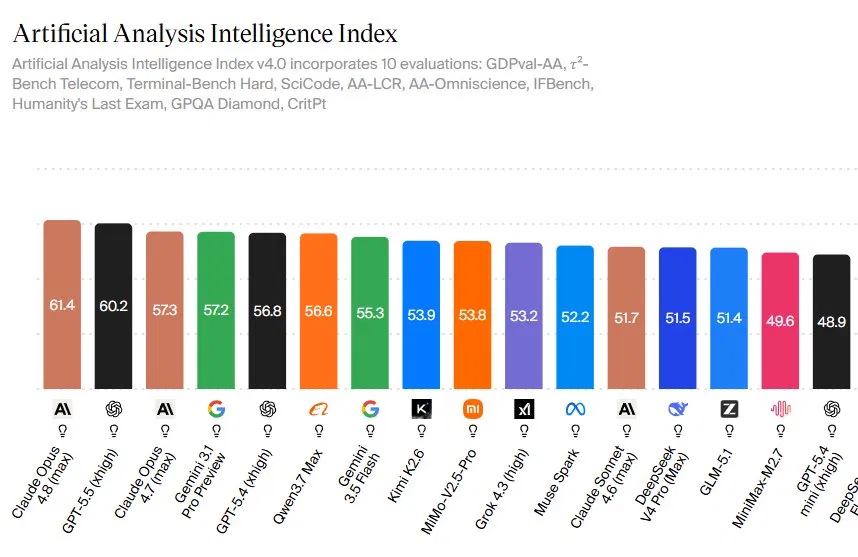
What Claude Opus 4.8’s Benchmark Win Actually Means
Claude Opus 4.8 is Anthropic’s newest flagship large language model that tops the Artificial Analysis Intelligence Index with a 61.4 score, outperforming GPT-5.5’s 60.2 and Opus 4.7’s 57.3, signaling a narrow but broad-based lead in real-world, agentic enterprise tasks. The Artificial Analysis Intelligence Index v4.0 blends ten demanding evaluations, including GDPval-AA, τ²-Bench Telecom, Terminal-Bench Hard, SciCode, AA-LCR, AA-Omniscience, IFBench, Humanity’s Last Exam, GPQA Diamond, and CritPt. Claude Opus 4.8’s lead comes not from a single standout metric but from consistent strength across this mix, especially in agentic coding, multidisciplinary reasoning, and autonomous computer use. In benchmark terms, the 1.2-point gap over GPT-5.5 looks small, yet it represents a shift in who defines the cutting edge of AI model performance comparison, with direct implications for which stack enterprises adopt for mission-critical automation.
GDPval-AA: From Lab Scores to Enterprise Outcomes
The strongest signal for enterprise buyers is Opus 4.8’s performance on GDPval-AA, a benchmark for agentic real-world work using web and shell access. Opus 4.8 reaches an Elo score of 1890, pulling 121 points ahead of GPT-5.5 and improving 137 points over Opus 4.7 at its max effort setting. That translates to an implied win rate of about 67% in head‑to‑head comparisons against GPT-5.5, indicating a reliable edge on economically valuable tasks across 44 occupations and nine industries. One quotable takeaway: “On knowledge work (GDPval-AA), it scores 1890, above GPT-5.5’s 1769 and Opus 4.7’s 1753.” For enterprises, this makes GDPval-AA more than a scorecard; it becomes a proxy for how models will behave in production environments where agents browse, script, and operate systems with minimal oversight.
Inside the Claude Opus 4.8 Benchmark Advantage
Beyond the composite index, Anthropic’s own numbers explain where Claude Opus 4.8 pulls ahead. On agentic coding (SWE-Bench Pro), it scores 69.2%, beating GPT-5.5’s 58.6% and Opus 4.7’s 64.3%. On Humanity’s Last Exam, the multidisciplinary reasoning benchmark, Opus 4.8 hits 49.8% without tools and 57.9% with tools, again leading rivals. Agentic computer use via OSWorld-Verified comes in at 83.4%, slightly above Opus 4.7’s 82.8% and ahead of GPT-5.5’s 78.7%. It also tops Finance Agent v2 for agentic financial analysis at 53.9%. The exception is terminal-focused coding, where GPT-5.5 leads Terminal-Bench 2.1 at 78.2% while Opus 4.8 scores 74.6%. Overall, this pattern reinforces that the Claude Opus 4.8 benchmark story is about breadth: strong coding, reasoning, and computer control in one model, not isolated strengths.
Cost, Speed, and Efficiency: Trade-offs for Enterprise AI Adoption
For enterprises, Claude Opus 4.8’s appeal is heightened by practical deployment factors. The model launches at the same price as Opus 4.7 while introducing a Fast Mode that runs Opus 4.8 at about 2.5x the speed at one‑third of the standard cost, accessible via the /fast command in Claude Code. Internally, Opus 4.8 is also more frugal than its predecessor, using 15% fewer turns and 35% fewer output tokens per GDPval-AA task. However, it still consumes around 30% more turns per task than GPT-5.5 to reach its higher scores. That means enterprises running high‑volume agentic workflows must weigh higher quality and stronger autonomy against interaction costs. Anthropic is betting that, for many teams, better task completion and lower oversight needs will offset the additional turns, especially when Fast Mode is in play.
Anthropic vs OpenAI: A Tighter Race for Enterprise AI Stacks
Claude Opus 4.8’s narrow lead over GPT-5.5 reshapes the frontier race without deciding it. On the Artificial Analysis Intelligence Index, Opus 4.8 sits at 61.4 while GPT-5.5 scores 60.2, and on GDPval-AA the gap is wider, yet both models remain clearly ahead of mid‑tier options such as Gemini 3.1 Pro Preview, GPT-5.4, Qwen3.7 Max, Kimi K2.6, and MiMo-V2.5-Pro. The rapid turnover at the top—GPT-5.5 recently dethroned Opus 4.7 on GDPval-AA before Opus 4.8 reversed the order—signals an intensifying cycle of releases where leadership is measured in weeks, not years. For enterprises, this suggests AI model performance comparison will be an ongoing process rather than a one-time choice. The stack decision now includes questions of ecosystem, reliability, and agentic tooling as much as raw scores, with Anthropic and OpenAI locked in a moving stalemate.





