
What Claude Fable 5 Is and Why It Matters
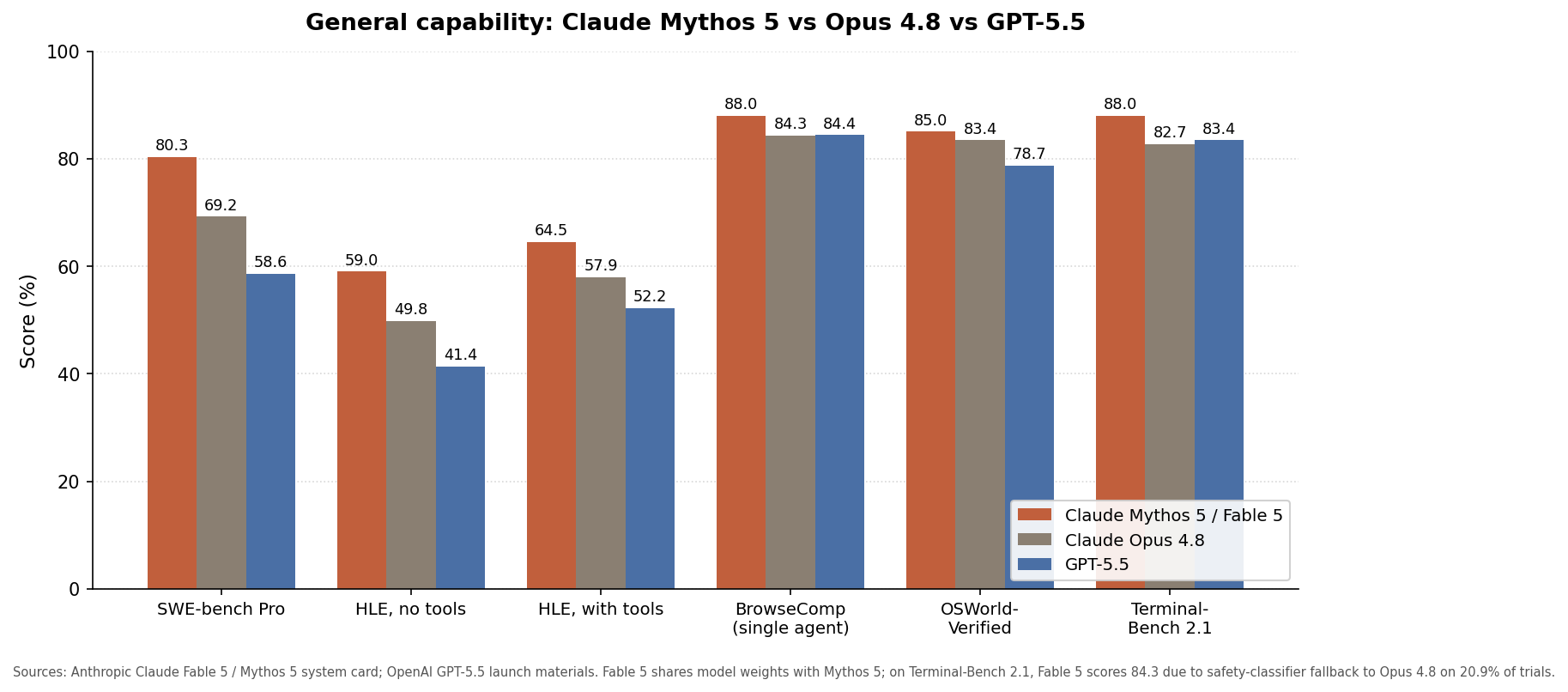
Claude Fable 5 performance refers to the real-world behavior of Anthropic’s first publicly available Mythos-class model, including its coding quality, reasoning strength, cost-per-session profile, and safety-driven routing to Claude Opus 4.8 on sensitive tasks. Fable 5 is built on the same weights as Mythos 5 but wrapped in classifiers that intercept cybersecurity, biology, chemistry, and model-distillation prompts before generation. On SWE-Bench Pro it scores 80.3% versus Opus 4.8’s 69.2%, and it is the first Claude model to exceed 90% on Hex’s long-running analytical benchmark. Artificial Analysis’s Intelligence Index ranks Fable 5 at 65, ahead of GPT 5.5 at 60 and Gemini 3.1 Pro Preview at 57. In Anthropic’s interface, selecting Fable 5 surfaces a notice that it “takes 2x the usage of Opus,” making its higher AI model cost efficiency tradeoff visible from the first message.
Mythos-Class Model Testing vs Opus 4.8: Quality and Token Economics
Head-to-head Mythos-class model testing against Opus 4.8 shows a clear quality jump but with higher session drain. On a simple ping pong browser game prompt, both models produced working HTML/JS, yet Fable 5 added a dark navy field, distinct paddle colors, and a clean score display, while Opus 4.8 stuck to classic arcade colors and a tighter layout. Third-party tests from Genspark reported that Fable 5 performs better on UI design and game coding, and Anthropic says it can rebuild a web app’s source code from a screenshot. The numbers show the cost side: Fable 5 used 37,927 tokens for 109,035 session credits, while Opus 4.8 used 38,587 tokens for 81,225 credits, a 34% higher credit burn for nearly identical token counts. Since Fable 5 is priced at USD 10 (approx. RM46) per million input tokens and USD 50 (approx. RM230) per million output tokens, roughly double Opus 4.8, frequent coding sessions hit usage ceilings faster.
Security Fallback Behavior: How Fable 5 Routes to Opus 4.8
One of Fable 5’s defining traits is its security fallback, which materially affects session consistency. Ask about a real security vulnerability or certain biology topics and the Claude interface quietly switches to Opus 4.8, marked by a small “Switched to Opus 4.8” banner plus an option to retry with Fable. The answer that follows comes from Opus, not the Mythos-class model you selected. Anthropic reports that this routing, driven by classifiers, triggers in fewer than 5% of sessions on average and that more than 1,000 hours of external red-teaming found no universal jailbreak. For users, this means cybersecurity-focused flows will see a mix of Fable 5 and Opus behavior and quality. The classifier is not an afterthought; it is the safety mechanism that made Mythos-level capability deployable while keeping response generation constrained on sensitive domains.
Claude vs GPT Comparison: Fable 5 and GPT 5.5 Strengths
In a Claude vs GPT comparison, available public data points to Fable 5 overtaking GPT 5.5 on several fronts that matter to builders. On Artificial Analysis’s Intelligence Index, Fable 5 scores 65 while GPT 5.5 scores 60, indicating stronger performance across the composite tasks that index tracks. Early users report the biggest gains in Claude Fable 5 performance for Claude Code, long coding tasks, application building, design iteration, and complex workflows. Stripe reported compressing months of engineering into days by running a migration across a 50‑million‑line Ruby codebase in a single day using Fable’s underlying Mythos 5. Physical Superintelligence described it as the strongest model it tested on frontier physics research while using about a third of the reasoning tokens. GPT 5.5 remains competitive, but these reports suggest Fable 5’s edge grows with task length, structural complexity, and need for multi-step reasoning.
Cost-Per-Session Choices for Developers and Enterprises
From a cost-per-session angle, the tradeoff is clear: Fable 5 offers higher quality and stronger reasoning at roughly 2x the model price of Opus 4.8 and with a measurable increase in credit usage per task. For teams running many interactive coding or analysis sessions, Fable 5’s 34% higher credit burn in the ping pong test illustrates how budgets can compress even when token counts are similar. Opus 4.8 remains the better fit when predictable usage, lower spend, and consistent latency matter more than absolute peak performance. Fable 5 fits cases where a small number of complex, high-value workflows justify higher spend, such as large codebase migrations, dense analytical work, or research exploration. GPT 5.5 sits as an alternative frontier option, but for users already in the Claude ecosystem, the choice becomes a targeted mix: Fable 5 for intensive sessions, Opus 4.8 for everyday throughput.





