
A New Stack for Real-Time Voice AI
OpenAI has released three new OpenAI audio models—GPT-Realtime-2, GPT-Realtime-Translate, and GPT-Realtime-Whisper—through its Realtime API, signalling a shift in real-time voice AI from simple chatbots to live, task-capable agents. Instead of a single model handling every audio job, OpenAI separates reasoning, translation, and transcription into dedicated tiers that can be tuned independently for latency and depth. GPT-Realtime-2 serves as the reasoning core for spoken interactions, while the other two models specialize in live translation and low-latency transcription. This modular approach is aimed at developers building voice app development stacks for assistants, call flows, and streaming tools that must keep talking while they reason, call APIs, or switch workflows mid-conversation. By offloading more orchestration into the model layer, OpenAI wants to reduce the complexity of managing long-running, interrupted, and tool-heavy voice sessions in production systems.

GPT-Realtime-2: GPT-5-Class Reasoning for Live Voice Agents
GPT-Realtime-2 is OpenAI’s flagship real-time voice agent, described as having GPT-5-class reasoning for spoken conversations. The model is designed to handle complex voice tasks: it tracks long context with a 128K token window, manages interruptions, reacts to corrections, and can call multiple tools in parallel without dropping the conversational thread. Developers can configure reasoning effort from minimal to xhigh, choosing between lower latency for simple interactions and deeper reasoning for intricate workflows. GPT-Realtime-2 also supports short spoken preambles such as “let me check that,” allowing apps to keep speaking while background actions run. OpenAI reports measurable gains over GPT-Realtime-1.5 in audio intelligence and instruction following, and emphasizes improved failure recovery: instead of going silent when a tool call breaks, the model can explain the issue and continue. This gives voice agents a more resilient, human-like feel in real-time voice AI experiences.

GPT-Realtime-Translate: Live Multilingual Conversations as a Service
GPT-Realtime-Translate targets developers building live multilingual products that need a fast live translation API. It ingests speech in more than 70 languages and can produce spoken or transcribed output in 13 languages, while staying in sync with the speaker. The model is tuned to preserve meaning and context even as users shift topics, speak quickly, or use regional accents and specialized vocabulary. Beyond basic translation, it can emit real-time transcriptions alongside translated audio, enabling scenarios such as bilingual customer support, cross-border sales calls, event interpretation, or creator platforms that localize content as it is recorded. Early tests highlighted by OpenAI include telecom and media companies exploring multilingual voice interactions. For developers, the dedicated translation tier means they can avoid overusing heavier reasoning models when they primarily need high-quality, low-latency translation in their voice app development pipelines.
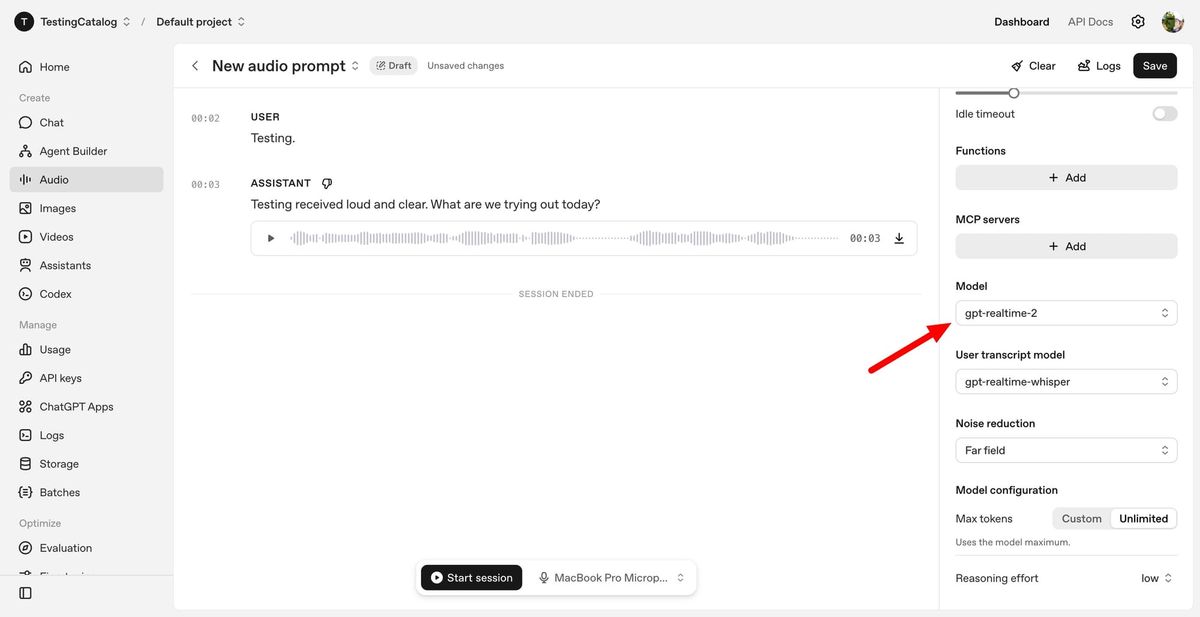
GPT-Realtime-Whisper: Low-Latency Transcription for Live Workflows
GPT-Realtime-Whisper brings streaming speech-to-text to OpenAI’s Realtime API, focusing on low-latency transcription. It listens and transcribes as people speak, making it suitable for live captions, meeting notes, and voice-driven workflows that need continuous recognition rather than offline batch processing. By dedicating a model to transcription, OpenAI lets developers reserve heavier reasoning or translation capabilities for the moments that truly require them, instead of routing all audio through a single monolithic system. This separation is particularly helpful in enterprise voice pipelines where only certain segments of a conversation need deep analysis. GPT-Realtime-Whisper can act as the always-on capture layer, feeding text into downstream tools, business logic, or GPT-Realtime-2 for reasoning. The result is a more efficient stack for low-latency transcription that fits into everything from productivity tools to customer interaction platforms that must respond while conversations are still unfolding.
From Simple Chat to Business Workflows
Together, the three models push voice AI beyond simple call-and-response chatbots into operational workflows. GPT-Realtime-2 anchors voice-to-action scenarios, where users speak naturally while the system searches data, applies filters, or schedules tasks in the background. The translation tier underpins systems-to-voice and voice-to-voice patterns, turning existing software outputs into spoken experiences and bridging languages in real time. Businesses can design agents that keep their place across long calls, interruptions, and tool hops without constant session resets. Developers gain fine-grained control: they can dial up reasoning when a complex decision is needed, or lean on translation and transcription for lighter turns to keep latency down. With all three OpenAI audio models exposed via the API platform, voice app development teams can assemble customized stacks that reason, translate, and transcribe live, turning voice into a first-class interface for modern applications.