Redundant Context Recomputation: The Silent Tax on Enterprise LLMs
Redundant context recomputation in LLM inference is the repeated processing of the same prompt or document context across multiple queries or agents, causing unnecessary compute, latency, and infrastructure cost in enterprise AI systems that run long-context, multi-step workloads at scale. In most stacks, every query is treated as a fresh session: the model re-reads the full document, rebuilds attention states, and discards them once the answer is generated. Over ten questions on a 100-page report, this means processing a thousand pages instead of a hundred. That waste dominates the context recomputation cost in long-context deployments and erodes the gains from model quantization or hardware upgrades. It also inflates latency; users wait seconds for a model to “remember” what it already saw. As enterprises shift to multi-agent LLM pipelines, this hidden tax multiplies, making LLM inference optimization a strategic priority rather than a nice-to-have refinement.

Taliesin and the Rise of Memory Engines for LLM Inference Optimization
Corbenic AI’s Taliesin is a memory engine built to remove this tax by caching and restoring processed context instead of recomputing it. Rather than forcing a model to re-run dense attention over the same prompt, Taliesin saves the internal “AI memory” after prefill and later restores it byte-identically, even on a different GPU. Corbenic describes redundant recomputation of context as “the single largest recurring cost in enterprise AI deployments,” and Taliesin targets that line item directly. On a $0.69-per-hour (approx. RM3.18) graphics card, Corbenic reports that the longest test contexts took more than two minutes to process from scratch, while Taliesin restored them in under seven seconds, a 21× speedup with no loss of accuracy. Cryptographic SHA-256 hashes back this claim, and bidirectional tests between Ampere and Ada cards produced output tokens that matched bit for bit, proving reliable KV cache sharing across GPU generations.
KV Snapshot Sharing: Prefill Once, Fan Out in Multi-Agent Pipelines
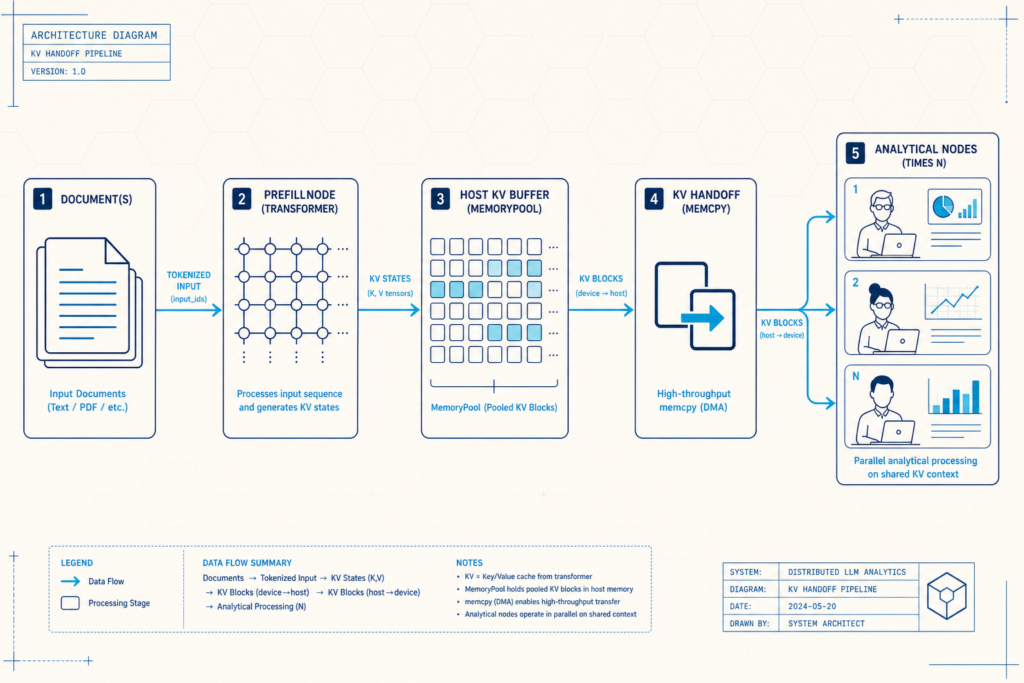
While Taliesin targets cross-session, cross-machine memory, work like SwarmKV shows how KV cache sharing can reshape multi-agent LLM pipelines. In a standard setup, if two agents analyze the same 3,500-token document, each agent triggers a full prefill, rerunning billions of identical multiplications. SwarmKV’s orchestrator instead runs prefill once, serializes the KV cache to a host buffer, then uses copy-on-fork style memcpy operations to create per-branch snapshots and restores them before decoding. On a GTX 1080 with a two-agent pipeline, this “compute once, fan out” approach made the system about 1.95× faster end to end and cut the second agent’s activation latency by roughly 52×, removing 8,685 ms of redundant dense compute. This is systems engineering, not a new transformer trick, but it sharply improves enterprise AI efficiency for graph-shaped, multi-agent LLM pipelines built around one shared source document.
Copy-on-Fork Memory Engines and the Future of Enterprise AI Efficiency
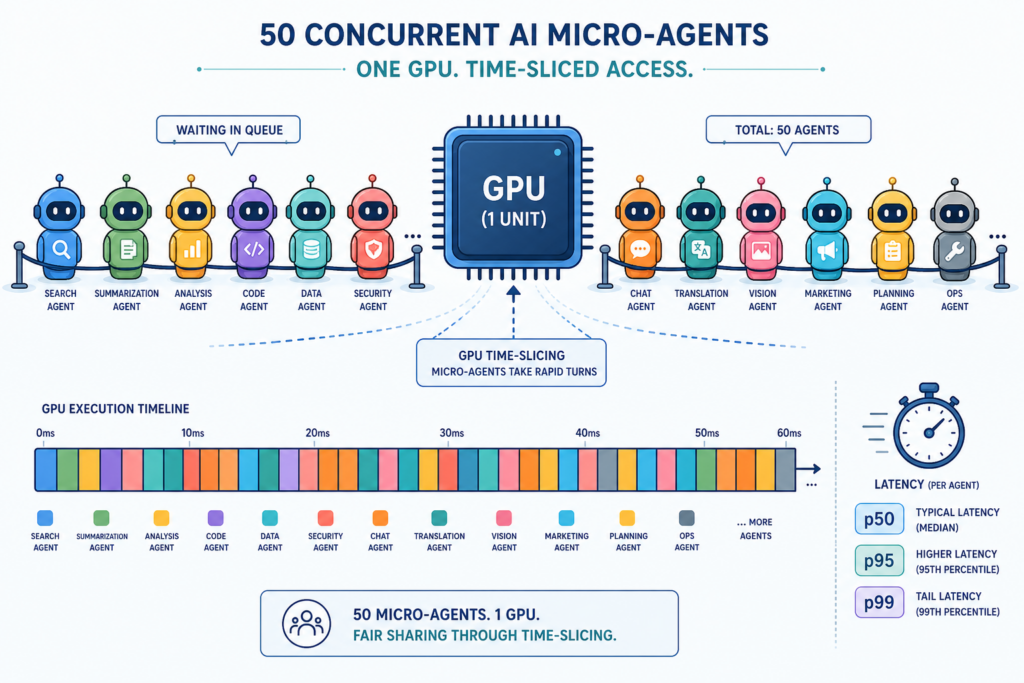
Both Taliesin and SwarmKV point toward a new design pattern: treat context as shared state that can be copied and moved, not recomputed. Copy-on-fork style mechanisms mean a single prefill can be preserved as a KV snapshot, then cheaply duplicated for dozens of downstream agents without re-running the dense pass. Because prefill cost grows steeply with context length while KV transfer scales more gently, this swap from recomputation to data movement can transform LLM inference optimization for long-context workloads. In practice, that means lower GPU utilization, shorter time-to-first-token, and reduced infrastructure footprints for teams running analytics, RAG, or compliance checks with many coordinated agents. As future work explores time-slicing many micro-agents on one GPU and persisting state across hand-offs, memory engines and KV cache sharing are set to become core tools for controlling context recomputation cost in enterprise-scale AI systems.