What NVIDIA OpenShell Brings to Local AI Agents on Windows
NVIDIA OpenShell is a new runtime for secure, local AI agents on Windows that combines Microsoft’s agent security features with RTX-optimized inference to deliver faster, private, on-device automation. Announced at NVIDIA GTC Taipei alongside the RTX Spark PC class, OpenShell gives developers a packaged way to deploy local AI agents that act across applications while remaining under direct user control. It builds on new Windows primitives for identity, containment, policy and end-to-end security, adding its own policy layer so users can define what an agent may access, which queries stay local and which can reach cloud models. This puts local AI agents Windows users can trust within reach of both enthusiasts and enterprises, turning RTX PCs from gaming machines into capable AI teammates for content creation, productivity and automation.
Security, Privacy and Policy: Why OpenShell Matters for Enterprises
OpenShell’s core appeal is that it turns RTX PCs into secure AI workstations by giving agents strict boundaries. Built on Microsoft’s new security primitives, the runtime ties each agent to a clear identity, places it in a contained environment and enforces policy end-to-end. NVIDIA adds a policy engine that routes queries between local and cloud models based on user privacy rules and can disguise personal data before anything leaves the device. This framework answers a central enterprise concern: how to gain AI automation without exposing sensitive workloads to external services. According to NVIDIA, the new Windows primitives and OpenShell runtime “ensure agents run safely and under full user control.” With agent developers like Hermes Agent and OpenClaw integrating OpenShell, organizations gain a path to deploy local AI agents that respect internal compliance rules while still working seamlessly across common Windows applications.
2x Inference Gains and Faster RTX PC Agent Performance
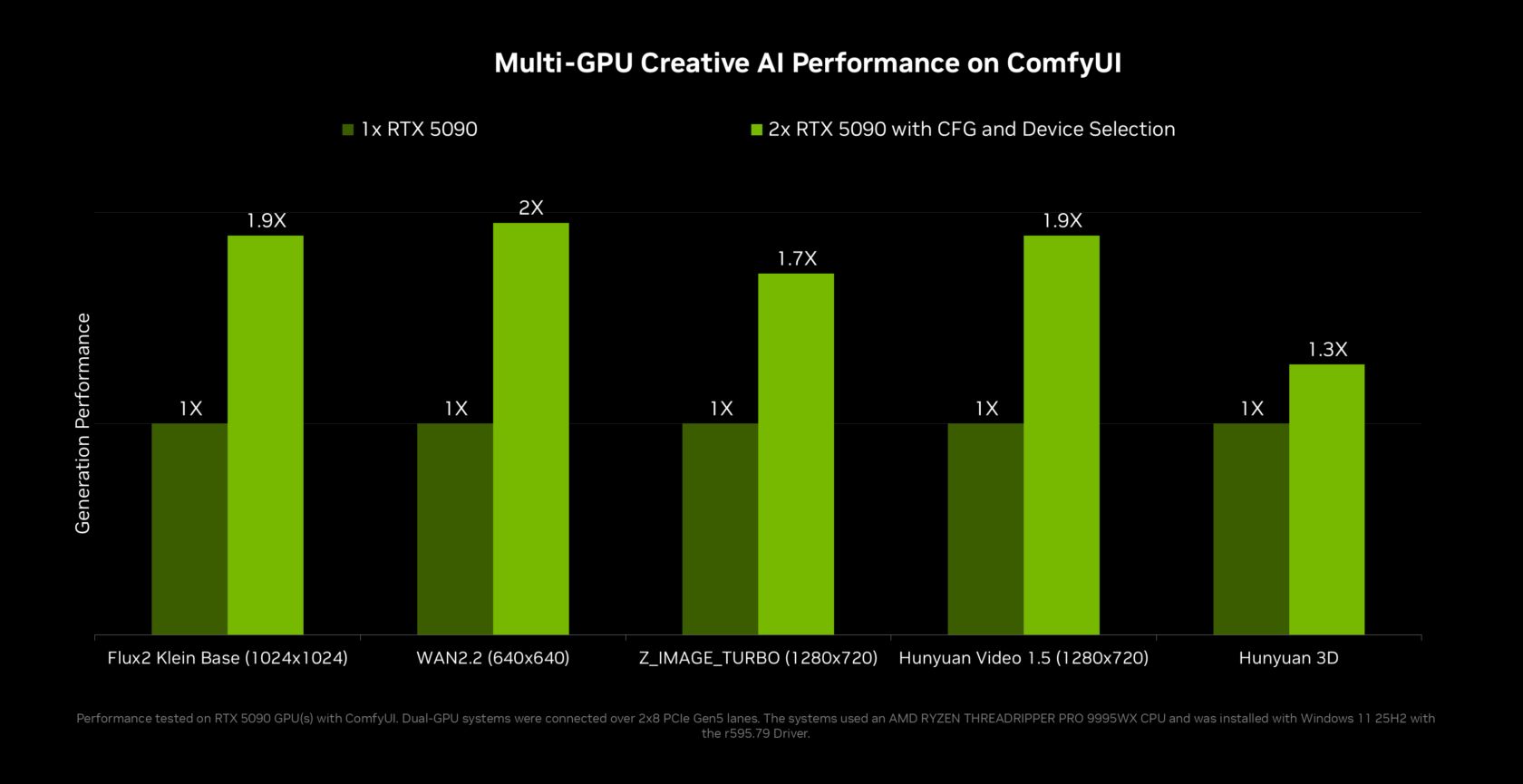
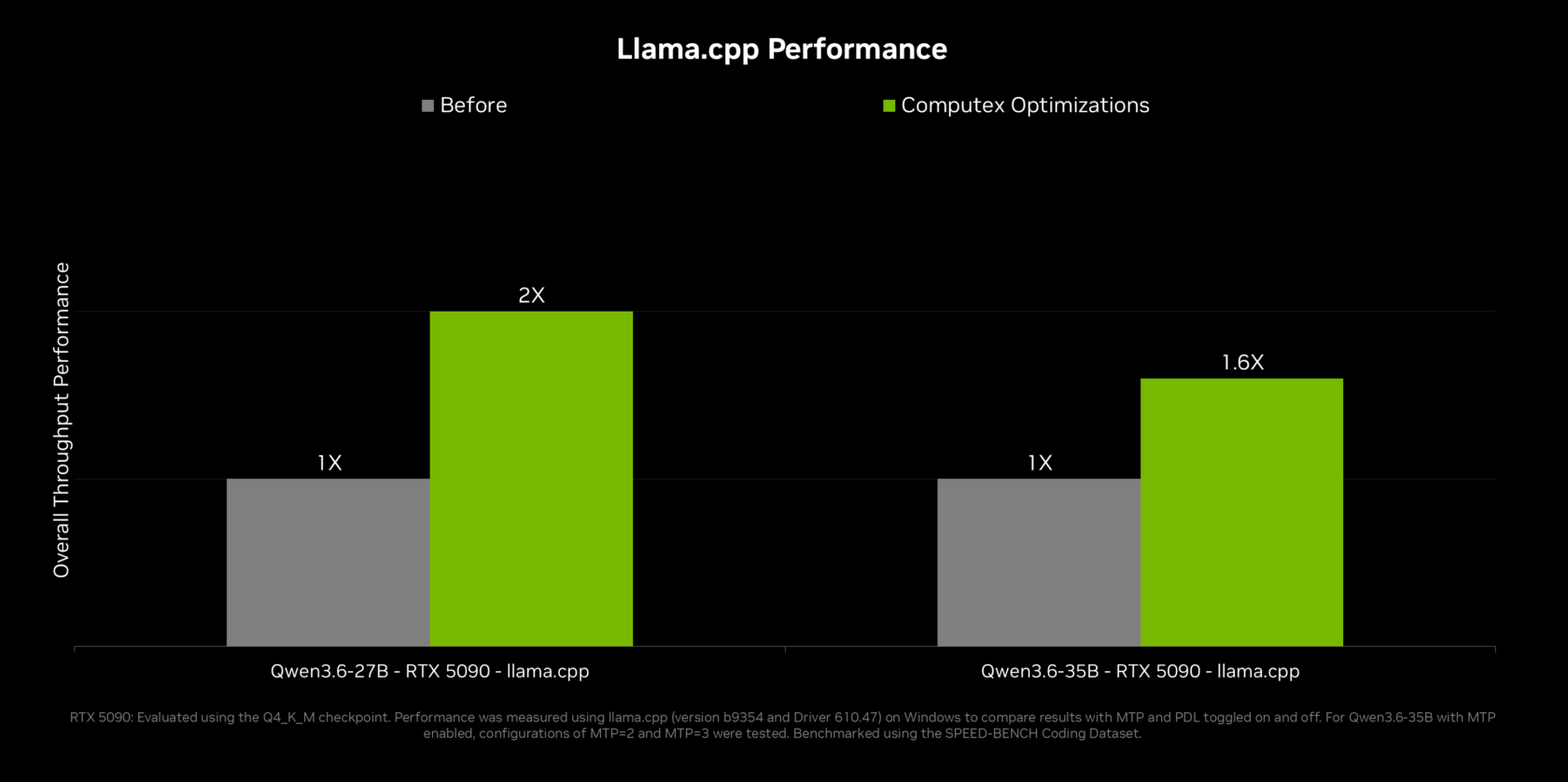
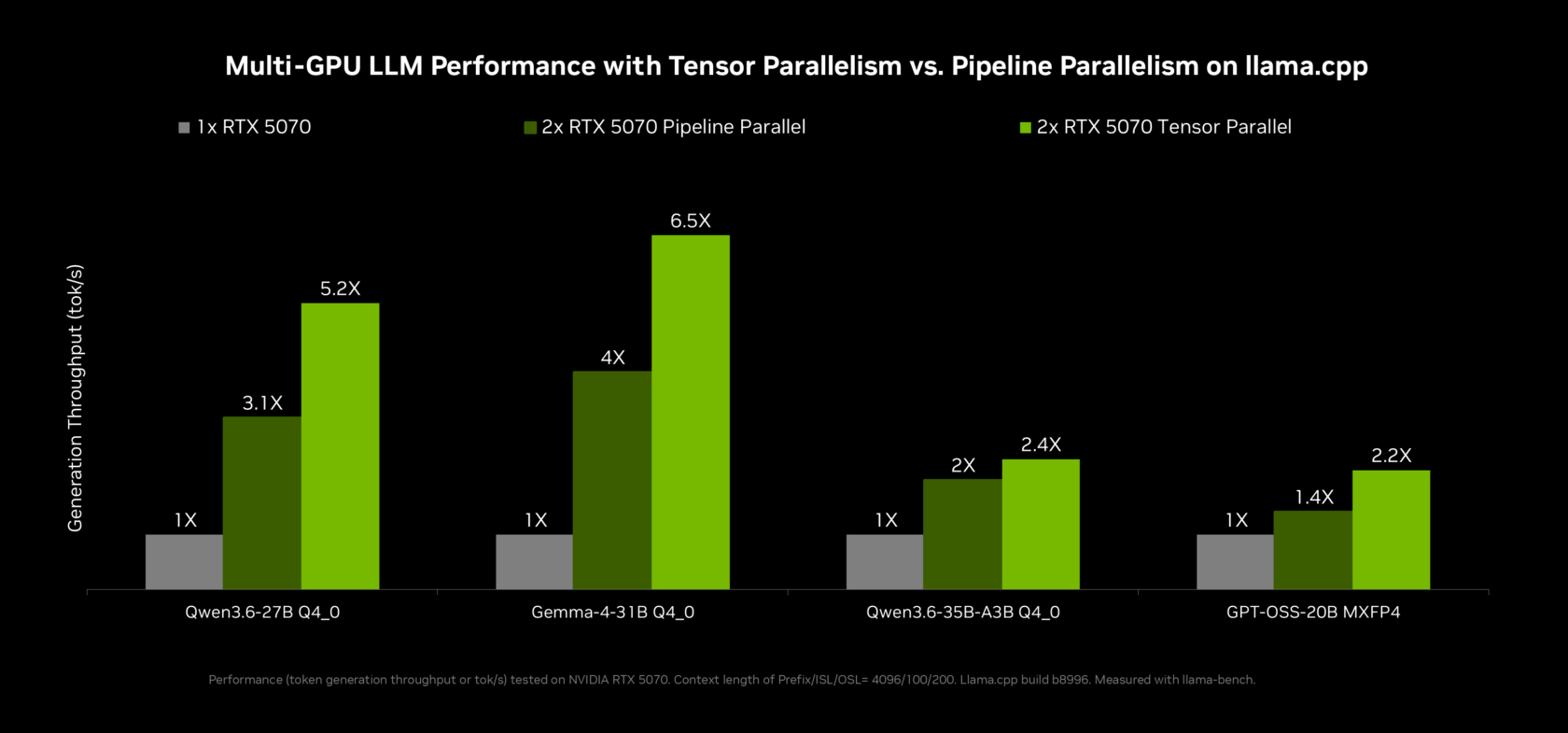
NVIDIA OpenShell performance gains are tied to deep optimization of the local model stack, especially for llama.cpp and vLLM. NVIDIA worked with the llama.cpp community to add multi-token prediction, where a smaller draft model proposes several tokens that a larger model verifies in one pass. Combined with programmatic dependent launch and other GPU-level improvements, this delivers up to 2x throughput on Qwen 3.6 and 3.5 27B and 1.6x on Qwen 3.6 and 3.5 35B on GeForce RTX 5090, boosting RTX PC inference speed for agentic workloads. For multi-GPU enthusiasts, new tensor parallelism in llama.cpp doubles effective memory and increases compute by up to 1.8x on two equivalent GPUs, while ComfyUI gains multi-GPU methods that nearly double performance on long chains. These changes make complex local AI agents feel more responsive and bring desktop inference closer to interactive cloud-level speeds.
RTX Spark, DGX and the Rise of Secure Local AI Workstations
OpenShell arrives as part of a broader push to turn RTX machines into secure AI workstations. RTX Spark introduces a new class of Windows PCs built for personal agents, with up to 1 petaflop of AI compute and 128GB of unified memory to keep large local models fed and responsive. At the high end, NVIDIA DGX Station for Windows brings data-center-class GPUs and CPUs into a deskside tower while preserving Windows manageability and compatibility. NemoClaw blueprints now span GeForce RTX, RTX PRO, RTX, DGX Spark and DGX Station, offering streamlined installers and automatic sandboxing for local agents. On Linux and Windows Subsystem for Linux, DGX Spark and vLLM optimizations deliver up to 2.6x performance on Qwen 3.6 35B NVFP4 checkpoints. Together, these systems form an ecosystem where developers can prototype agents locally and scale them without changing platforms.
Adobe, H Company and the Future of Local AI Agents on RTX PCs
The OpenShell ecosystem is already attracting major software partners, pushing local AI agents Windows users can deploy into mainstream workflows. Adobe is rearchitecting Photoshop and Premiere for RTX Spark, focusing on performance and memory efficiency so creative tools can tap local models without overwhelming system resources. H Company is releasing computer-use tools and an upcoming desktop agent harness that let agents use a PC like a human, seeing the screen and operating mouse and keyboard even in applications with no APIs. NVIDIA has helped quantize H Company’s Holo Computer Use models and accelerate the harness, doubling speed on NVIDIA GPUs while cutting memory use by 35%. With Hermes Agent, OpenClaw, Blender, ComfyUI and NVIDIA Broadcast updates also in the pipeline, RTX PCs are shifting from gaming-first machines to secure AI workstations ready for professional content creation and enterprise-grade automation.






