A Comeback Bid in the AI Coding Assistant Wars
Cursor is using Composer 2.5 to reassert itself in an AI coding assistant market now dominated by rivals like Claude Code. Once seen as the default AI IDE, Cursor has recently ceded mindshare as Anthropic’s tools reportedly attracted hundreds of thousands of business customers and significant recurring revenue. That success created an awkward dynamic: Cursor depended on Anthropic for inference while competing with it for developers’ attention. Composer 2.5 is Cursor’s clearest move to break that dependence and reclaim product differentiation. Built on Moonshot’s Kimi K2.5 but heavily retrained in-house, the model is designed to tackle long-running coding tasks and multi-step agent workflows, where developer expectations are rapidly rising. Cursor is betting that combining competitive intelligence with aggressive developer tools pricing will make Composer 2.5 a credible Claude alternative for teams looking to scale AI-assisted coding without ballooning costs.

Benchmarks: Near-Frontier Performance at a Discount
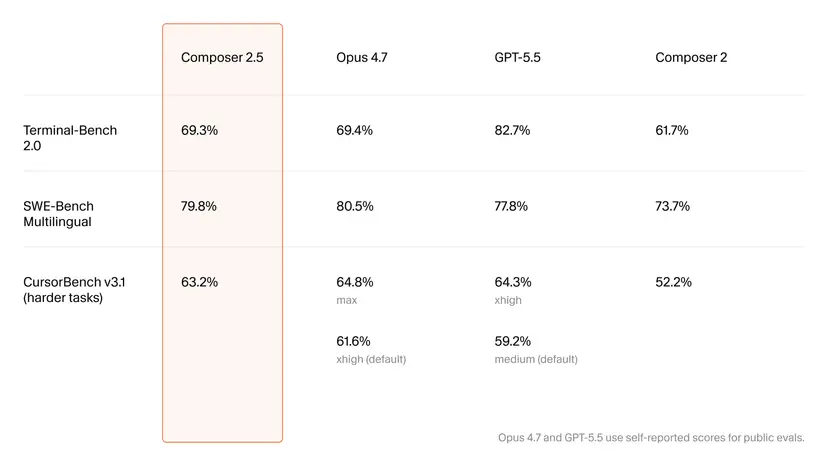
On paper, Composer 2.5 lands close to top-tier models like Opus 4.7 and GPT-5.5 while charging far less per token. Cursor reports a 79.8% score on SWE-Bench Multilingual, slightly trailing Opus 4.7’s 80.5% but edging ahead of GPT-5.5’s 77.8%. On Terminal-Bench 2.0, Composer 2.5 reaches 69.3%, a sizable jump from Composer 2’s 61.7%, though GPT-5.5 still leads with 82.7%. Cursor’s own CursorBench v3.1 shows Composer 2.5 at 63.2%, roughly on par with Opus 4.7’s higher-effort runs and ahead of GPT-5.5’s default setting. The crucial twist is cost efficiency: at USD 0.50 (approx. RM2.30) per million input tokens and USD 2.50 (approx. RM11.50) per million output tokens, Composer 2.5 can complete complex benchmark tasks while consuming significantly less budget, supporting Cursor’s claim of up to 10x cost efficiency versus premium competitors delivering similar accuracy.

Targeted Reinforcement Learning and 25x Synthetic Training
Under the hood, Composer 2.5 leans heavily on targeted reinforcement learning and massive synthetic training runs to reach its cost-performance sweet spot. Cursor says roughly 85% of the total compute on top of the Kimi K2.5 base went into its own training pipeline. A key innovation is localized textual feedback during reinforcement learning: instead of a single reward at the end of a long trajectory, the model receives precise hints at the exact point it misbehaves, such as a faulty tool call. This sharpens credit assignment across long contexts and agent-like workflows. On top of that, Composer 2.5 was trained on 25 times as many synthetic tasks as Composer 2, combined with improved behavioral calibration to refine communication style and coding consistency. This blend of synthetic scale and careful RL aims to make the model more dependable on real-world, long-running coding tasks while keeping inference costs low.
Developer Tools Pricing as a Strategic Weapon
Composer 2.5’s economics may be its strongest differentiator in the AI coding assistant landscape. The standard model is priced at USD 0.50 (approx. RM2.30) per million input tokens and USD 2.50 (approx. RM11.50) per million output tokens, with a faster default variant at USD 3.00 (approx. RM13.80) per million input tokens and USD 15.00 (approx. RM69.00) per million output tokens. Cursor’s own effort curves show Composer 2.5 achieving around 63% on CursorBench for under USD 1 (approx. RM4.60) per task, a cost level where competing models often require several times more budget for comparable scores. For engineering leaders, this positions Composer 2.5 as a cost efficient coding option: teams can run more iterations, longer agents, or broader rollouts without immediately hitting budget ceilings, potentially making it an attractive Claude alternative in organizations that prioritize price-performance over absolute top-end capability.
Benchmarks vs. Reality: Will Cost Efficiency Translate to Productivity?
Despite impressive numbers, the real test for Composer 2.5 will be how it behaves inside active repositories and CI pipelines. Early users praise its stronger handling of long-running tasks and more accurate tool calls relative to earlier Cursor models, but anecdotal reports also note agent confusion, such as switching modes mid-task or losing track of multi-step pipelines. Commenters point out that benchmark intelligence does not always map cleanly to day-to-day coding productivity, especially for multi-file refactors, codebase-specific conventions, and subtle context alignment. Cursor itself acknowledges that benchmarks provide only high-level comparisons, not guarantees of practical usefulness. For now, Composer 2.5 looks like a serious, aggressively priced contender among AI coding assistants, particularly for teams optimizing developer tools pricing. Whether its 10x cost efficiency truly pays off will depend on how reliably it can maintain context, follow nuanced instructions, and integrate into real production workflows over time.